




 本文深入解析MapReduce的工作原理,包括map()与reduce()函数的角色,数据处理流程如shuffle和sort,以及如何通过计数器进行分布式Job调试。同时,介绍了在不同环境下执行MapReduce作业的方法,包括本地和集群环境,并提供了详细的配置指导。
本文深入解析MapReduce的工作原理,包括map()与reduce()函数的角色,数据处理流程如shuffle和sort,以及如何通过计数器进行分布式Job调试。同时,介绍了在不同环境下执行MapReduce作业的方法,包括本地和集群环境,并提供了详细的配置指导。
-
map()——映射
一次处理一行,每行记录都会经过map()处理。
需转换为键值对,map(key, value)。
通过对key哈希,把相同key的键值对交给特定的节点处理。
适时地调用combiner()进行处理,用于降低网络带宽。 -
reduce——化简
- shuffle
从mapper节点复制存储的output数据。本质上是数据的分发,即根据key值,通过哈希算法将键值对数据分发到不同的的reduce处理器上去处理,防止数据倾斜。 - sort
按照key值对input数据进行排序。 - reduce
可以通过配置指定到几个节点上。
-
job
一个mapreduce称为一个job,即job = map task + reduce task。 -
LocalJobRunner执行Mapreduce的作业流程
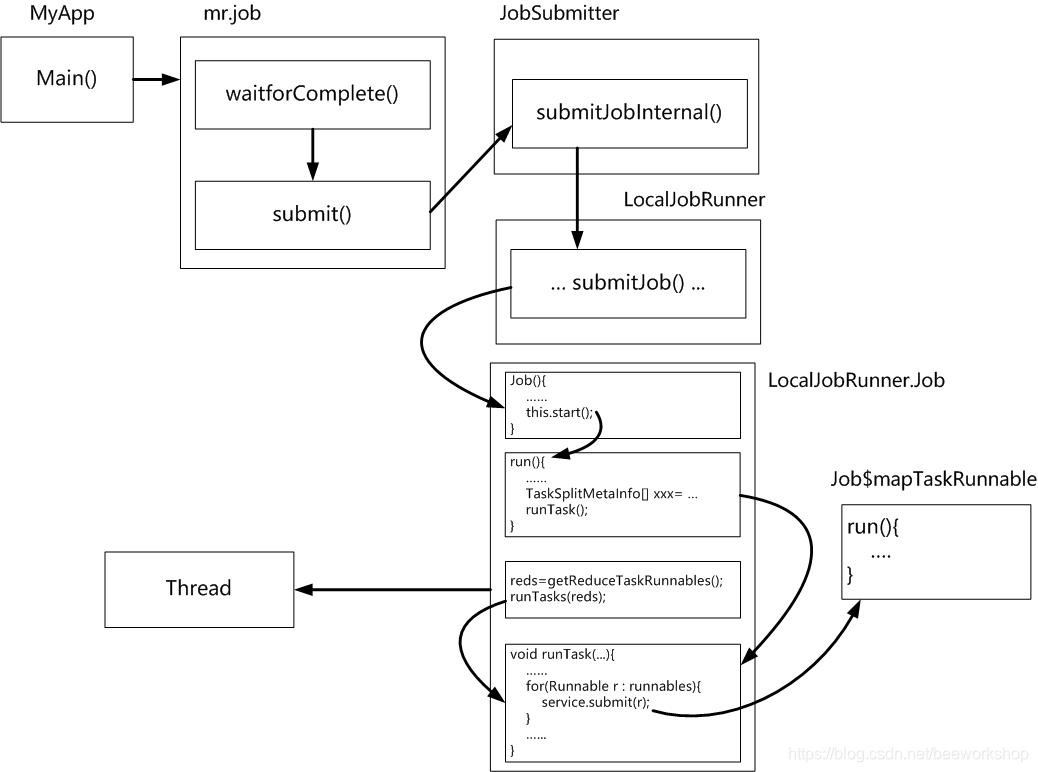
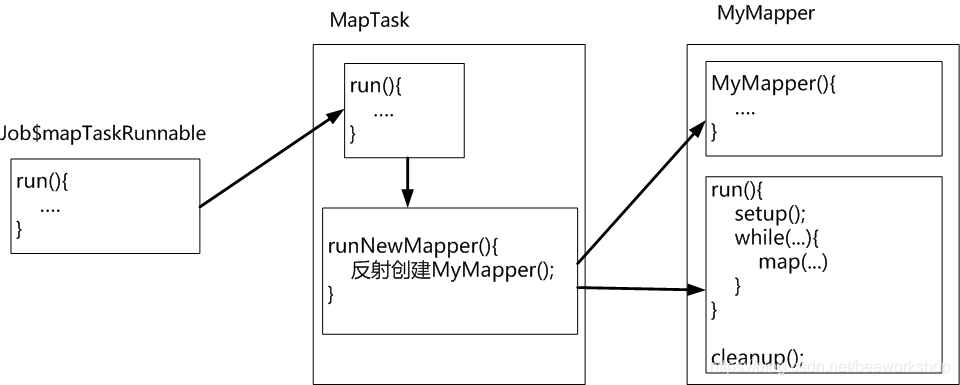
-
运行分布式job
- 启动hadoop集群
start-dfs.sh
start-yarn.sh
mapreduce.framework.name:
local——伪分布式
yarn——完全分布式
- 将MR程序导出为Jar包。
eclipse -> export
# 查看jar包中的内容
jar -tvf xxx.jar
- 准备数据
hdfs dfs -mkdir /user/data/ncdc
hdfs dfs -put * /user/data/ncdc
- 运行job
hadoop jar xxx.jar fullpath.to.main.class.App.name dir/input dir/output
使用YarnJobRunner才使用集群的计算资源。
- 验证
http://namenode:8088/ - logs
- 利用计数器进行分布式Job的调试(服务器集群侧)
自定义计数器。计数器包括:
- group name
- counter name
context.getCount("groupname","counter-name").increment(1);
- 在非集群客户端提交执行Job
- 客户端必须的配置
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<? -- 指定NameNode -->
<value>hdfs://node01:8020</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 资源管理器设定为NameNode主机 -->
<value>node01</value>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
core-site.xml,yarn-site.xml和mapred-site.xml配置文件放在java项目的classpath根目录,即src/目录下。
注意:在客户端(eclipse上)运行的是应用主类,而在服务器端是运行打成的jar包。客户端不运行Job,只负责提交Job,但可以与服务器的集群端进行通信获得状态。客户端的debug只能看到客户端的作业提交过程,看不到服务器集群端的运算过程,而目前服务器集群端的debug只提供了println()和计数器的log输出方式。这些log的输出是可以传回客户端的。
- 客户端打成jar包
三个文件:
MyMapperApp.java <------------------在客户端运行
MyMapper.java <--------------------在集群上运行
MyReducer.java <---------------------在集群上运行
在客户端的debug只能看到MyMapperApp类的计算过程,看不到类MyMapper和MyReducer的计算过程。MyMapper和MyReducer类的计算过程在集群上进行(通过jar包),debug调试只能通过println()和计数器以log的方式返回客户端。
MyMapperApp只有使用YarnJobRunner调度Job才表示已经提交到集群上了。如果是LocalJobRunner调度,表示是在客户端本地通过多线程模拟的。
运行过程如下:
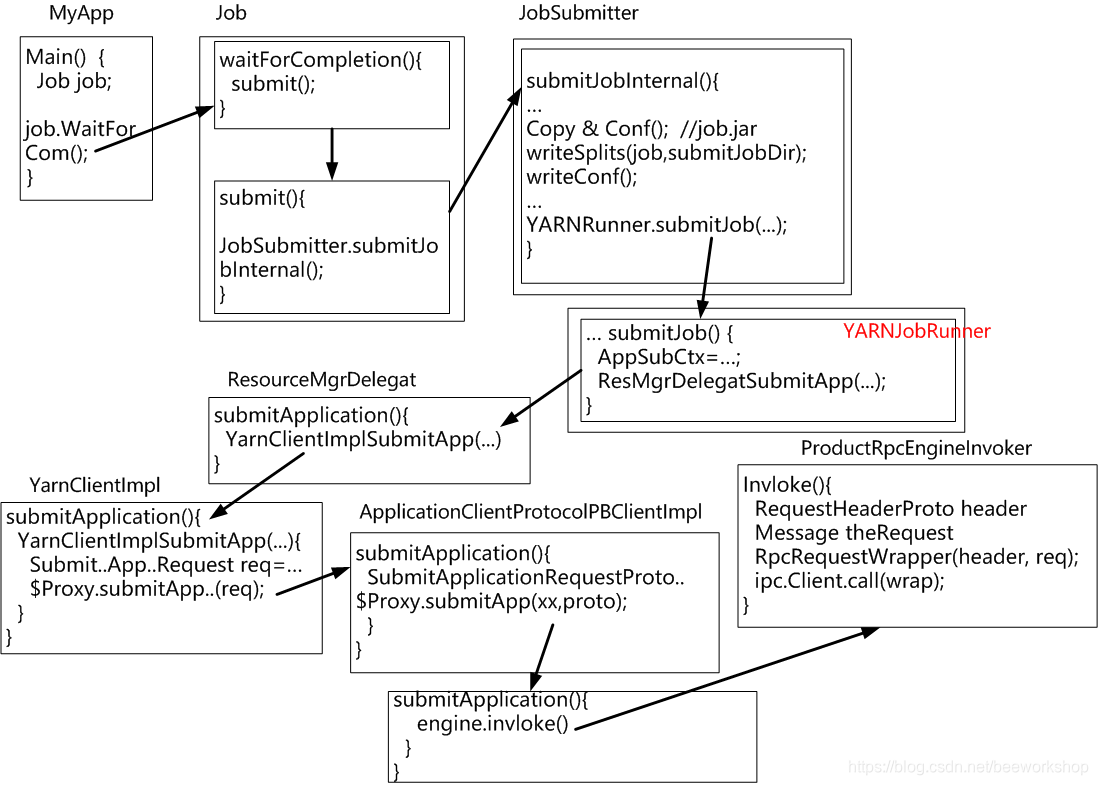
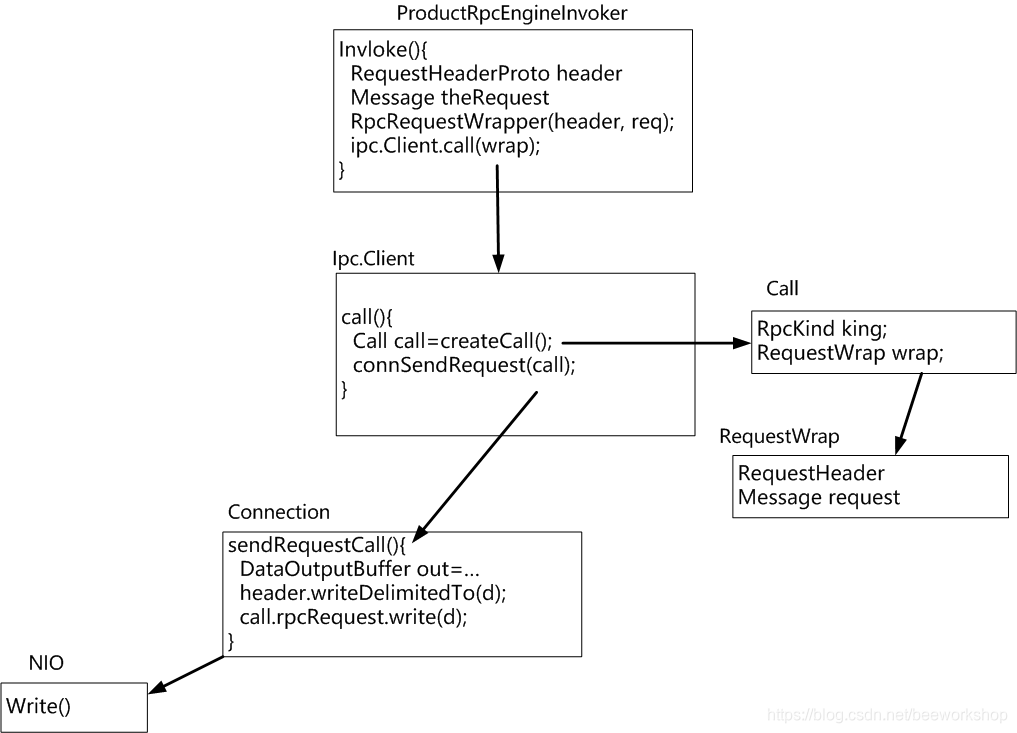
- 提交到hadoop集群上运行。
在客户端称为Job,一旦提交到服务器集群端则被称为Application。
- 安装客户端hadoop软件
不论在服务器集群端还是在客户端,安装的hadoop软件都是hadoop-2.9.2.tar.gz,客户端程序及服务器端程序都在里边了。
- 解压tarball
需要把winutils.exe放到%HADOOP_HOME%\bin目录下。 - 配置环境变量
HADOOP_HOME=...
PATH=%PATH%;%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin
- 验证
hadoop version
-
配置文件
core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml。
具体配置同node01-node05。 -
客户端插件
配置如下:
① MR信息
hostname:NameNode_IP
port:8032(默认)
② DFS信息
hostname:NameNode_IP
port:8020(默认)

















 1550
1550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









