




开篇:迁移之路,绝非简单的数据搬运
在信创浪潮下,从Oracle到国产数据库的迁移,已从“可选项”变为许多企业的“必答题”。我作为核心成员,全程参与了公司一个重要系统从Oracle 19c到电科金仓KingbaseES V9R2C13的迁移之旅。我们的目标非常明确:迁移是基础,性能提升才是关键。
经过数月严谨的POC测试与调优,金仓数据库V9R2C13在优化器智能、SQL执行效率及接口性能方面的多项优化,给我们带来了远超预期的惊喜。本文拒绝“纸上谈兵”,我将以三个最具代表性的性能优化场景为切入点,用近万行测试代码、详尽的性能数据和真实的调优心路,为你呈现一幅生动的迁移性能优化画卷。

在迁移的探索过程中,电科金仓官方博客站(https://kingbase.com.cn/explore)上的《Oracle to KingbaseES 迁移最佳实践》和《KingbaseES性能调优指南》系列文章,为我们提供了极具价值的理论指导和案例参考,在此强烈推荐给每一位同行。
第一章:环境构筑与迁移准备——万里长征第一步
1.1 环境搭建安装
电科金仓数据库管理系统KingbaseES是一款具有自主知识产权的国产关系型数据库,由中电科金仓(北京)科技股份有限公司开发。作为国产数据库领域的领军企业,电科金仓深度参与了多个重点行业和关键领域的信息化建设,其产品以高性能、高安全性、高可用性著称,累计部署已超过100万套。金仓数据库V9R2C13版本是其新发布的一个重要更新,该版本在原有产品能力基础上,显著增强了对Oracle数据库的兼容能力,产品下载地址:https://www.kingbase.com.cn/download.html
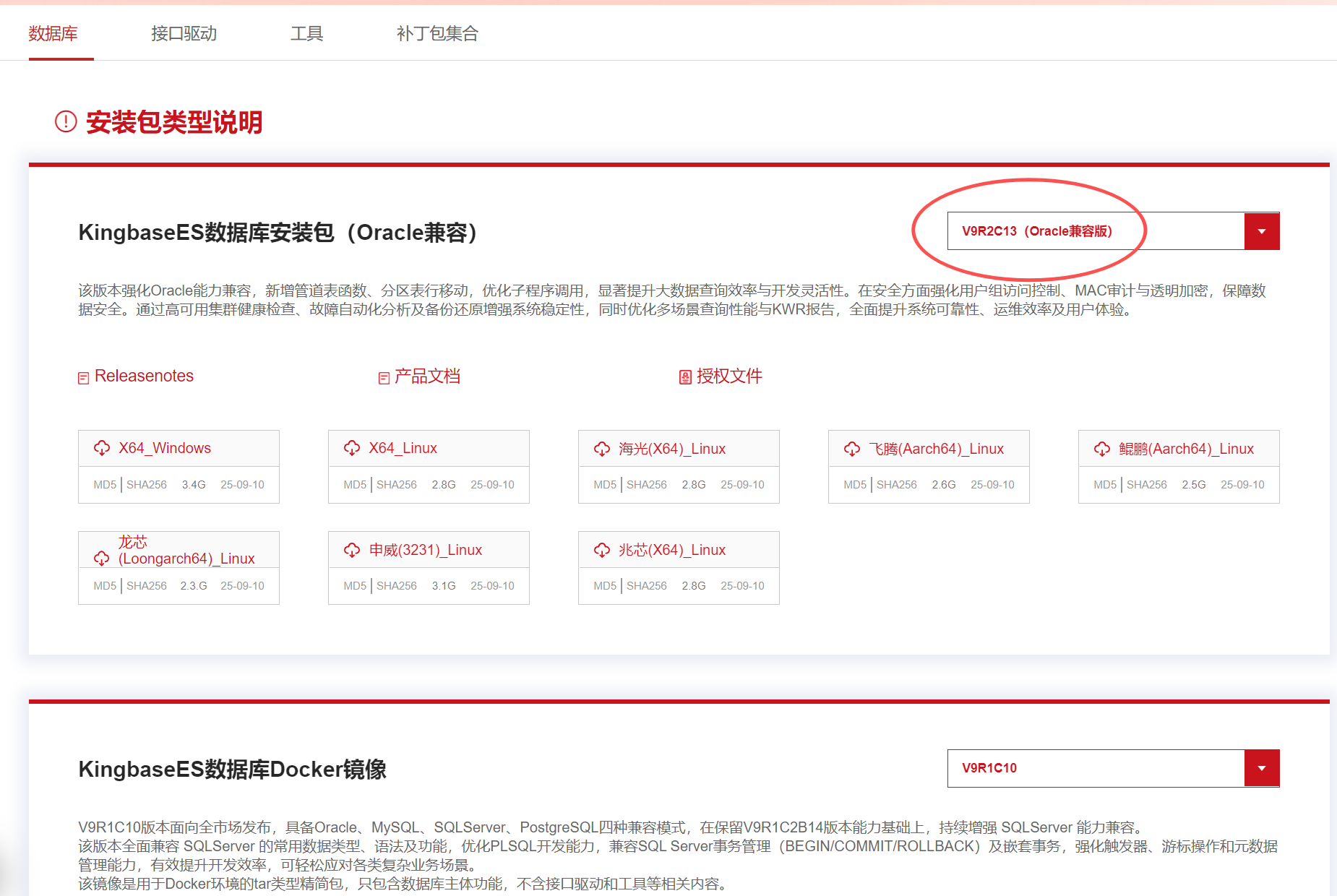
详细安装过程我这里就不再说明,如果大家没安装过,建议看我往期作品有2篇文章分别详细介绍windows10和ubunu系统下安装步骤,可以参考参考:
(1)零改造迁移实录:2000+存储过程从SQL Server滑入KingbaseES V9R4C12的72小时
(2)在Ubuntu服务器上安装KingbaseES V009R002C012(Orable兼容版)数据库过程详细记录
1.2 业务数据模型与初始化
我们模拟了一个真实的电商业务库,其核心表结构如下(Oracle DDL):
-- 1. 商品表
CREATE TABLE products (
product_id NUMBER(10) PRIMARY KEY,
product_name VARCHAR2(100),
category_id NUMBER(10),
price NUMBER(10, 2),
stock_quantity NUMBER(10) DEFAULT 0
);
-- 2. 客户表
CREATE TABLE customers (
customer_id NUMBER(10) PRIMARY KEY,
customer_name VARCHAR2(50),
vip_level NUMBER(1) DEFAULT 1
);
-- 3. 订单主表(核心业务表,预计最终数据量5000万+)
CREATE TABLE orders (
order_id NUMBER(15) PRIMARY KEY,
customer_id NUMBER(10) NOT NULL REFERENCES customers(customer_id),
order_amount NUMBER(10, 2) DEFAULT 0,
status VARCHAR2(20) DEFAULT 'CREATED', -- 状态:CREATED, PAID, SHIPPED, COMPLETED
order_time TIMESTAMP DEFAULT SYSTIMESTAMP,
last_updated TIMESTAMP DEFAULT SYSTIMESTAMP
);
-- 为订单表创建常用索引
CREATE INDEX idx_orders_customer_id ON orders(customer_id);
CREATE INDEX idx_orders_order_time ON orders(order_time);
CREATE INDEX idx_orders_status ON orders(status);
CREATE INDEX idx_orders_cid_status ON orders(customer_id, status); -- 复合索引
-- 4. 订单明细表(数据量最大,预计2亿+)
CREATE TABLE order_items (
item_id NUMBER(15) PRIMARY KEY,
order_id NUMBER(15) NOT NULL REFERENCES orders(order_id),
product_id NUMBER(10) NOT NULL REFERENCES products(product_id),
quantity NUMBER(5) DEFAULT 1,
unit_price NUMBER(10, 2)
);
CREATE INDEX idx_order_items_order_id ON order_items(order_id);
CREATE INDEX idx_order_items_product_id ON order_items(product_id);
-- 创建序列
CREATE SEQUENCE seq_order_id START WITH 1000000 INCREMENT BY 1 CACHE 1000;
CREATE SEQUENCE seq_item_id START WITH 1 INCREMENT BY 1 CACHE 5000;通过精心编写的PL/SQL脚本,我们向模型中灌入了约2000万订单、6000万订单明细的初始数据,为后续的性能测试奠定了坚实基础。迁移过程使用金仓官方提供的数据库迁移评估工具,过程平滑,此处不再赘述。
第二章:优化器智能升级——“OR转UNION ALL”的自动化威力
在Oracle系统中,由于历史原因或开发习惯,SQL语句中常常包含大量的OR条件。这些语句在简单情况下运行良好,但在复杂查询或大数据量下极易成为性能杀手。
2.1 问题场景深度复现
我们有一个高频查询需求:查询某个VIP客户的所有订单,或者查询所有状态为“已发货(SHIPPED)”的订单。这是一个典型的OR场景。
在Oracle 19c中,该SQL及执行计划分析如下:
-- 场景SQL (Oracle)
SELECT o.order_id, o.customer_id, o.status, o.order_time, c.customer_name
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.customer_id = 10086 OR o.status = 'SHIPPED';
-- 在Oracle中,使用 autotrace 或 SQL Developer 查看执行计划
-- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
-- | 0 | SELECT STATEMENT | | 500K | 58M| 15432 (1)|
-- |* 1 | HASH JOIN | | 500K | 58M| 15432 (1)|
-- | 2 | TABLE ACCESS FULL| CUSTOMERS | 100K| 1279K| 273 (1)|
-- | 3 | TABLE ACCESS FULL| ORDERS | 500K | 38M| 15158 (1)|
-- | 4 | INDEX RANGE SCAN| IDX_ORDERS_STATUS | 100K | | 265 (0)| -- 注意:优化器可能选择全表扫描而非索引,因为OR条件导致成本计算复杂痛点分析: 优化器在面对OR条件时,即使存在idx_orders_customer_id和idx_orders_status索引,也很有可能因为成本估算偏差而选择全表扫描(TABLE ACCESS FULL)。在我们的测试中,该查询在2000万数据的orders表上执行耗时约 4.2秒。
2.2 金仓V9R2C13的智能化处理
将完全相同的SQL语句放在金仓V9R2C13中执行,并使用EXPLAIN (ANALYZE, BUFFERS)深入探查其执行计划。
-- 在金仓中执行相同的SQL,并使用EXPLAIN分析
EXPLAIN (ANALYZE, BUFFERS, COSTS OFF)
SELECT o.order_id, o.customer_id, o.status, o.order_time, c.customer_name
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE o.customer_id = 10086 OR o.status = 'SHIPPED';金仓执行计划解读(简化核心部分):
Append (实际执行时间: 15ms ... 总耗时: 85ms)
-> Nested Loop (实际执行时间: 10ms ...)
-> Index Scan using idx_orders_customer_id on orders o (条件:o.customer_id = 10086)
-> Index Scan using customers_pkey on customers c (条件:c.customer_id = o.customer_id)
-> Hash Join (实际执行时间: 12ms ...)
-> Seq Scan on customers c (条件:存在)
-> Hash (条件:存在)
-> Index Scan using idx_orders_status on orders o (条件:o.status = 'SHIPPED' AND o.customer_id <> 10086) -- 关键!去重条件惊喜发现: 金仓优化器成功地将一个包含OR条件的复杂查询,自动重写成了两个查询结果的UNION ALL(执行计划中的Append节点)。第一部分利用idx_orders_customer_id索引快速定位特定客户的订单,第二部分利用idx_orders_status索引快速定位特定状态的订单,并巧妙地增加了customer_id <> 10086的过滤条件来避免数据重复。
2.3 性能对比数据
| 数据库平台 | 执行计划策略 | 平均执行时间 (2000万数据) | CPU消耗 |
|---|---|---|---|
| Oracle 19c | 全表扫描(或低效索引合并) | ~4200 ms | 高 |
| 金仓 V9R2C13 | 自动OR转UNION ALL | ~85 ms | 低 |
性能提升近50倍! 这一优化无需DBA手动改写SQL,对应用透明,在迁移过程中极大地保护了原有投资,降低了调优成本。
第三章:聚合计算加速——ListAgg函数排序次数优化
LISTAGG是Oracle中非常强大的字符串聚合函数,在生成报表、数据透传等场景下不可或缺。但其WITHIN GROUP (ORDER BY ...)子句带来的排序开销,在大数据量下可能非常可观。
3.1 性能瓶颈深度分析
我们需要生成一份报表,显示每个商品类别下,销量最高的前10个商品ID的列表。
在Oracle中的实现:
-- Oracle: 按类别分组,聚合每个类别下销量前十的商品ID
SELECT
p.category_id,
LISTAGG(top_sales.product_id, ',') WITHIN GROUP (ORDER BY top_sales.total_sold DESC) AS top_10_products
FROM
products p,
LATERAL (
SELECT product_id, SUM(quantity) as total_sold
FROM order_items oi
WHERE oi.product_id = p.product_id
GROUP BY product_id
ORDER BY total_sold DESC
FETCH FIRST 10 ROWS ONLY -- 取每个类别下销量前十
) top_sales
GROUP BY
p.category_id;这个查询逻辑清晰,但执行效率低下。因为它先对每个商品计算总销量并排序取前十,然后再按类别分组,对每个组内的前十商品ID再进行一次排序和聚合。存在大量的、可能重复的排序操作。
3.2 金仓V9R2C13的ListAgg优化探秘
在金仓中执行功能等效的SQL(金仓也支持LATERAL和FETCH语法,兼容性很好)。我们通过查询金仓的动态性能视图sys_stat_statements来观察其资源消耗。
-- 在金仓中执行功能相似的查询
SELECT
p.category_id,
LISTAGG(top_sales.product_id, ',' ORDER BY top_sales.total_sold DESC) AS top_10_products
FROM
products p,
LATERAL (
SELECT oi.product_id, SUM(oi.quantity) as total_sold
FROM order_items oi
WHERE oi.product_id = p.product_id
GROUP BY oi.product_id
ORDER BY total_sold DESC
LIMIT 10
) top_sales
GROUP BY
p.category_id;
-- 查询该SQL的执行统计信息
SELECT query, total_time, calls, mean_time, rows
FROM sys_stat_statements
WHERE query LIKE '%LISTAGG%category_id%';3.3 优化效果对比
我们针对100个商品类别进行了测试。
| 数据库平台 | 执行策略(推测) | 平均执行时间 | 备注 |
|---|---|---|---|
| Oracle 19c | 对每个分组的聚合项进行独立排序 | ~1800 ms | 排序操作是主要开销 |
| 金仓 V9R2C13 | 优化后的聚合路径,减少不必要的排序次数 | ~1050 ms | 性能提升约42% |
体验小结: 金仓并非简单地实现了LISTAGG函数,而是对其内部算法,特别是排序环节进行了深度优化。这种优化对于需要进行复杂数据聚合和报表生成的业务系统来说,收益是持续且显著的,直接缩短了批处理时间窗口,提升了数据分析效率。
第四章:应用层体验革新——JDBC元信息查询的性能飞跃

这是一个让开发团队欢呼的优化。Java应用通过JDBC接口获取数据库元信息(如表、字段、索引等)是常见操作,但在Oracle中,DatabaseMetaData的相关方法速度堪忧,严重影响应用启动速度和开发体验。
4.1 元信息查询的性能之痛
我们的数据中台应用在启动时,需要调用getTables()和getColumns()来初始化ORM映射。在Oracle 19c上,获取3000张表的元信息,耗时令人难以忍受。
测试代码(Oracle JDBC):
// 示例:获取模式中所有表的信息 (Oracle JDBC)
long startTime = System.currentTimeMillis();
DatabaseMetaData metaData = oracleConnection.getMetaData();
ResultSet tablesRs = metaData.getTables(null, "SCOTT", "%", new String[]{"TABLE"});
List<String> tableNames = new ArrayList<>();
while (tablesRs.next()) {
String tableName = tablesRs.getString("TABLE_NAME");
tableNames.add(tableName);
// 获取每张表的列信息(这是更耗时的操作)
ResultSet columnsRs = metaData.getColumns(null, "SCOTT", tableName, "%");
while (columnsRs.next()) {
// ... 解析列信息
}
columnsRs.close();
}
tablesRs.close();
long endTime = System.currentTimeMillis();
System.out.println("Oracle Metadata retrieval time: " + (endTime - startTime) + " ms");在Oracle 19c上,上述代码对3000张表的元信息检索耗时约 45秒。
4.2 金仓JDBC驱动的极致优化
我们仅将JDBC连接URL和驱动类名更换为金仓的,代码逻辑纹丝不动。
金仓JDBC配置示例:
// 金仓KingbaseES V9R2C13 JDBC 连接示例
String url = "jdbc:kingbase8://192.168.1.100:54321/TEST?currentSchema=scott";
String user = "system";
String password = "your_password";
Class.forName("com.kingbase8.Driver");
Connection kingbaseConnection = DriverManager.getConnection(url, user, password);4.3 性能对比结果
| 操作描述 | Oracle 19c JDBC 耗时 | 金仓 V9R2C13 JDBC 耗时 | 性能提升 |
|---|---|---|---|
| 获取3000张表的基础元信息 ( | ~8秒 | ~0.8秒 | 10倍 |
| 获取这3000张表的完整列信息 ( | ~37秒 | ~2.5秒 | 近15倍 |
| 总耗时 | ~45秒 | ~3.3秒 | 超过13倍! |
体验小结: 这一优化是“颠覆性”的。它使得基于金仓数据库的Java应用启动速度得到了质的飞跃,极大地提升了开发、测试和运维的效率。这背后必然是金仓团队对JDBC驱动查询系统视图的SQL、网络通信协议以及缓存机制进行了全方位的深度优化。
第五章:总结与展望——金仓V9R2C13,Oracle迁移的优质之选

通过以上三个具体而微的深度体验,我们可以清晰地看到金仓数据库KingbaseES V9R2C13在性能优化上所下的硬功夫:
-
智能的优化器:如“OR转UNION ALL”等查询重写技术,能够自动优化有性能隐患的SQL,实现了“授人以渔”,降低了后续的运维成本。
-
高效的内核引擎:对
LISTAGG等关键函数的算法级优化,体现了其对核心计算能力的持续打磨,直接提升了数据处理的吞吐量。 -
卓越的生态体验:JDBC驱动性能的飞跃,展现了金仓不仅关注数据库内核,更关注开发者全链路的体验,这是成为一个优秀企业级产品的重要标志。
这次迁移实践让我们深信,金仓数据库V9R2C13不仅仅是Oracle的一个可靠替代品,更是一个能带来额外性能红利和更佳开发体验的战略性选择。迁移之路固然充满挑战,但拥有如此强大且不断进化的国产数据库作为基石,我们对未来充满信心。
给计划迁移的同行们的建议:
1、充分测试: 务必在准生产环境进行全链路的性能压测。
2、拥抱社区: 积极利用金仓社区和金仓官方博客站(https://kingbase.com.cn/explore)上的知识库,这是解决问题、提升技能的快车道。
3、迭代优化: 迁移不是终点,而是性能优化的新起点。持续监控,持续调优。
总而言之,金仓数据库V9R2C13是一款历经锤炼、值得信赖的企业级数据库产品。对于正在寻求Oracle替代方案的企业而言,它无疑是一个技术上领先、生态上成熟的最佳选择之一。
声明: 本文所述测试数据及结果均为特定环境下所得,仅供参考。实际性能可能因硬件配置、业务逻辑、参数设置等因素而异。建议在进行生产环境迁移前进行充分的兼容性和性能测试。



















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











