



Redis并发以及实际运用
通常使用Redis的时候,在业务量很高的情况下都是使用了多服务端。也就是如下场景:
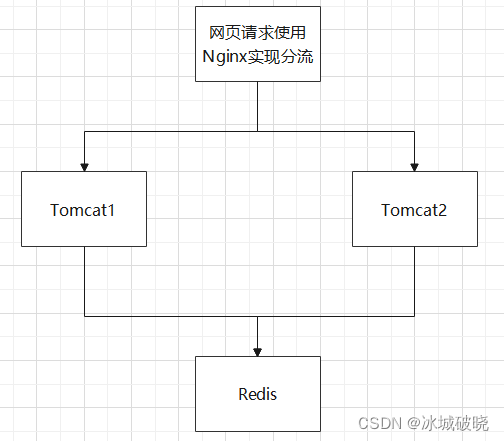
也就是多个服务器共用一个缓存Redis。那么在高并发情况下,传统的synchronized就无法实现控制并发的效果了。因为synchronizd无法跨进程同步控制,那么该如何解决?
分布式锁
我们可以转换思路,将锁控制的原理运用在Redis中,使用类似CAS的操作即可完成一个分布式锁的运用。
@Autowired
StringRedisTemplate stringRedisTemplate ;
public void addCount(){
String lockKey = "lock_key";
//在Redis中如果lockKey对应的value不存在则添加一个locakKey为Key,value为1的键值对,成功返回true表示加锁成功
Boolean b = stringRedisTemplate.opsForValue().setIfAbsent(lockKey , "1" , 30 , TimeUnit.SECONDS);
if( !b ){ System.out.println("error_code"); return; }
try{
/*
业务逻辑
*/
}finally{
//业务执行完删除,释放锁,放在finally中保证一定释放,防止抛出异常导致死锁
stringRedisTemplate.delete(lockKey);
}
}
以上则是一个简单的分布式锁,利用CAS和Redis串行化处理请求的机制,对Redis中做一个标记,如果添加成功则表示拿到锁,可以进行业务流程,否则就拿不到锁。最后在业务结束后删除标记释放锁。
这个锁存在很多很多问题,虽然使用了finally保证了锁的释放,但是,如果在try运行时系统宕机,那么依旧会出现死锁一段时间的情况。这还不算问题最严重的地方,如果中间业务逻辑使用的时间过长,在释放锁前,Redis因为时间到了自动解锁。那么并发问题会出现,而且并不是导致这两次请求出现问题,而是后续的请求都会出问题。因为A逻辑执行结束依旧会删除lockKey,也就是释放B线程新加的锁,导致C线程也能进行,B释放C的锁让D同步进行,直接崩盘了。
对于宕机和运行超时问题,宕机也就亏一点点运行时间,但是运行超时会影响数据正确性。为了解决运行超时,需要利用一个监视线程,每隔10s对当前线程是否持有锁进行一次判定,如果还拿着,就对Redis中的标记进行一个延时增长,也就是锁续命
使用这种方式,代码的逻辑需要很严密,所以实现起来非常困难,一般情况下,企业中通常使用已经封装好的分布式锁类库来进行操作,也就是导入Redisson。
Redisson
Redisson就是使用了上述的思路,对分布式锁有一个极为稳定的实现,把它当成ReentrantLock的使用方式,就可以很方便地使用了。
<!-- 导入分布式锁Redisson的依赖 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>
//向容器中添加Redisson分布式锁
@Bean
public Redisson redisson(){
Config config = new Config();
//此时为单机模式
//绑定Redis所在的IP和使用哪个DataBase,这里设置为第0个Database
config.useSingleServer().setAddress("redis://182.92.123.117:6379").setDatabase(0);
return (Redisson) Redisson.create(config);
}
@Autowired
Redisson redisson;
@RequestMapping("/useRedisson")
public String useRedisson(){
String lockKey = "Lock_Key";
RLock rLock = redisson.getLock(lockKey);
try{
//在这里没获取到锁的线程会进行阻塞
rLock.lock();
/*
业务逻辑
*/
}finally {
//在finally中释放锁
rLock.unlock();
}
}
这样就可以实现分布式锁
高并发优化
Redisson实现的分布式锁是将并发访问串行化,也就是通过阻塞的方式每次只能运行一个线程。这样效率会大大降低,如何进行优化?
使用ConcurrentHashMap底层所使用的的分段锁思想
假设我们进行一个商品秒杀活动,商品总共有200件,访问一次数量减1,不足则返回秒杀失败。在极大并发的情况下,单线程处理单秒几千几万次访问肯定是效率不够的,想要承受双11级别的并发,效率更是低的离谱。不妨我们可以将商品分段,分成10份,1份20个。对lockKey加一个下标,比如lockKey_0,lockKey_1 ..... lockKey_9。每个锁只锁住1份商品,也就是同时可以进行10个请求,阻塞时间极大幅度减少,运行效率提升了很多倍。
缓存数据库双写不一致
使用Redis时,一下代码块是常用的:
@RequestMapping("/update")
//不想用CachePut可以自定义Redis逻辑 AOP或者代码实现
@CachePut( cacheNames = "User" , key = " #result.email " )
public User updateUser(User user){
//数据库操作
return user;
}
此时并没有使用分布式锁,高并发情况下就会出现一下问题:
正常应该是以下流程
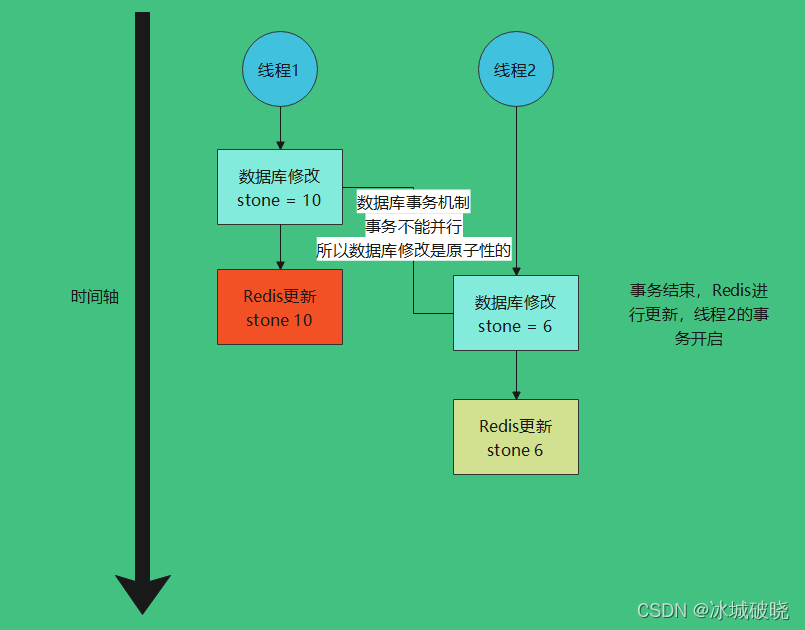
最终redis中结果为6。
高并发情况下的双写不一致:
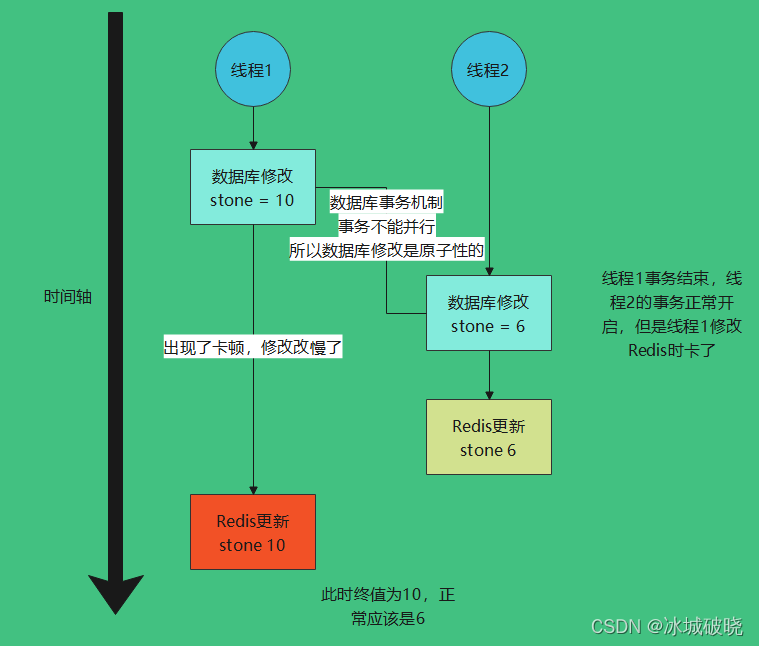
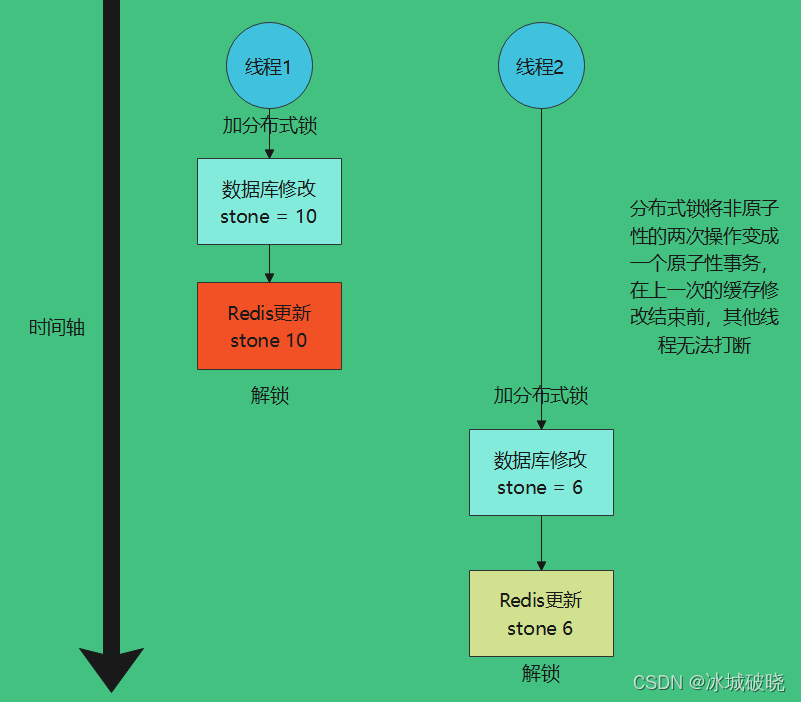
分布式锁可以解决双写不一致问题。
业务场景运用
抽奖
使用Set无需集合,将所有参与抽奖的用户装入这个集合,最后随机取出。
添加用户:sadd 集合名 用户ID
查看所有参与抽奖的用户:smembers 集合名
不放回抽取:srandmember 集合名 数量
放回抽取: spop 集合名 数量
关注推送
使用List
关注的人发消息,则对关注它的消息队列执行:lpush msg:{ID} 10018
查看消息:lrange msg:{ID} 0 4 拿出前5条消息
当一个人关注的人数较多怎么办呢?几百万粉丝一起推送的话,是不是处理量有点太大了。对此的策略是:没办法,只能这么玩,优化策略是对当前在线的粉丝进行优先推送,不在线的粉丝则慢慢推送。
点赞统计,浏览次数统计
set watchNum 1
inr watchNum
购物车
购物车可以使用HashMap,也就是哈希表,哈希表中存放(物品编号,数量)键值对。
添加商品:hset cart:用户编号 商品编号 1
增加数量:hincrby cart:用户编号 商品编号 1
商品总数:hlen cart:用户编号
删除商品:hdel cart:用户编号 商品编号
获取购物车所有商品:hgetall cart:用户编号

















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









