




 探讨单页应用框架如何解决位置传播、位置重置、加载耗时及错误保护等问题,介绍View.js框架的实现机制。
探讨单页应用框架如何解决位置传播、位置重置、加载耗时及错误保护等问题,介绍View.js框架的实现机制。
不需要 Npm 的单页应用框架:
位置传播
单页应用要解决的第一个问题,就是浏览位置的传播问题:
页面在通过 URL 传播打开时,浏览器展现的画面与传播前画面并不一致
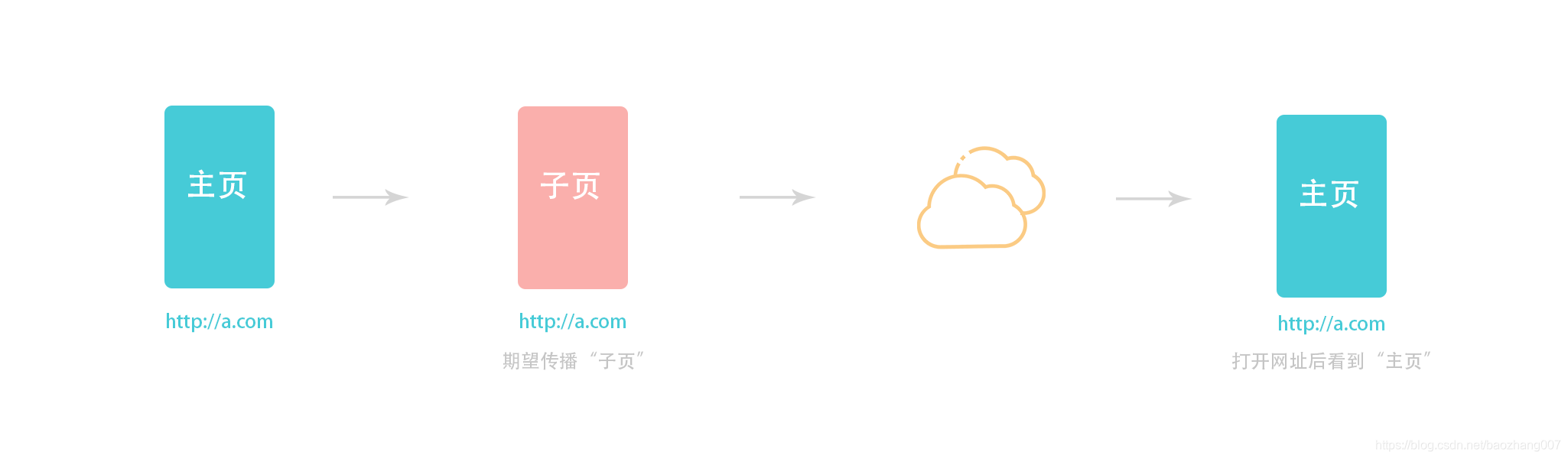
之所以会这样,是因为客户端做出的 “切换页面(单页应用中,切换页面通过切换显示的区块实现)” 操作,仅会在终端用户与程序的交互过程中,在事件监听句柄中被动发生,而并没有将切换页面关联的一系列操作封装成一种逻辑上的指令,使得指令再次发出时,相同视觉效果的变更会再次发生。例如:
btnObj.addEventListener("click", function(){
var subpageObj = document.querySelector(".page.subpage"),
currentActiveObj = document.querySelector(".page.active");
/**
* 页面切换至subpage
*
* 由于该操作是在事件监听句柄中发生的,因此subpage不会在页面装载完毕后自动呈现,
* 只能通过手动点击按钮才能呈现出来。此时subpage无法实现URL传播
*/
currentActiveObj.classList.remove("active");
subpageObj .classList.add("active");
});解决上述问题的第一步,是将页面与URL关联起来,使得URL能够表达页面位置。亦即,当页面主体内容发生变化时,将页面的位置信息借助锚点反馈至URL中。此时网页的传播效果如下图所示:

相关代码如下所示:
btnObj.addEventListener("click", function(){
var subpageObj= document.querySelector(".page.subpage"),
currentActiveObj = document.querySelector(".page.active");
/**
* 页面切换至subpage
*/
currentActiveObj.classList.remove("active");
subpageObj.classList.add("active");
/**
* 向URL中“写”位置,使得浏览位置能够随URL一起传播
*/
location.hash = "sub-page";
});由于执行了 “写位置” 操作,所以网页实现了其浏览位置能够跟随URL一起传播的能力。但由于缺乏传播后的反向 “读位置” 的能力,所以网页仍然无法在用户视觉层面上有效地解决位置传播问题。
此时,代码需要进一步完善为:
btnObj.addEventListener("click", function(){
var subpageObj= document.querySelector(".page.subpage"),
currentActiveObj = document.querySelector(".page.active");
/**
* 页面切换至subpage
*/
currentActiveObj.classList.remove("active");
subpageObj.classList.add("active");
/**
* 向URL中“写”位置,使得浏览位置能够随URL一起传播
*/
location.hash = "sub-page";
});
/* 从URL中读取位置,并根据位置呈现对应界面 */
document.addEventListener("DOMContentLoaded", function(){
var page = location.hash.substring(1);/* 去除字符:'#' */
var pageObj = document.querySelector(".page." + page);
pageObj.classList.add("active");
});
不仅要 “写”,还要 “读”,这一业务无关的代码逻辑通常遍布单页应用的大多数地方。如何以优雅透明地方式为开发者解决这一问题,便是单页框架要考虑的首要问题之一。
位置重置
由位置传播延伸出来的另一个问题,是如何应对 “不能传播页面位置” 的这一需求的问题:
无论传播前的浏览位置在哪里,当页面在通过 URL 传播打开时,浏览器均需要固定地呈现特定的某一个页面
这种需求通常出现在 “将提交动作分散在多个子页面完成,以降低用户的信息提供复杂度” 的场景下,比如注册:
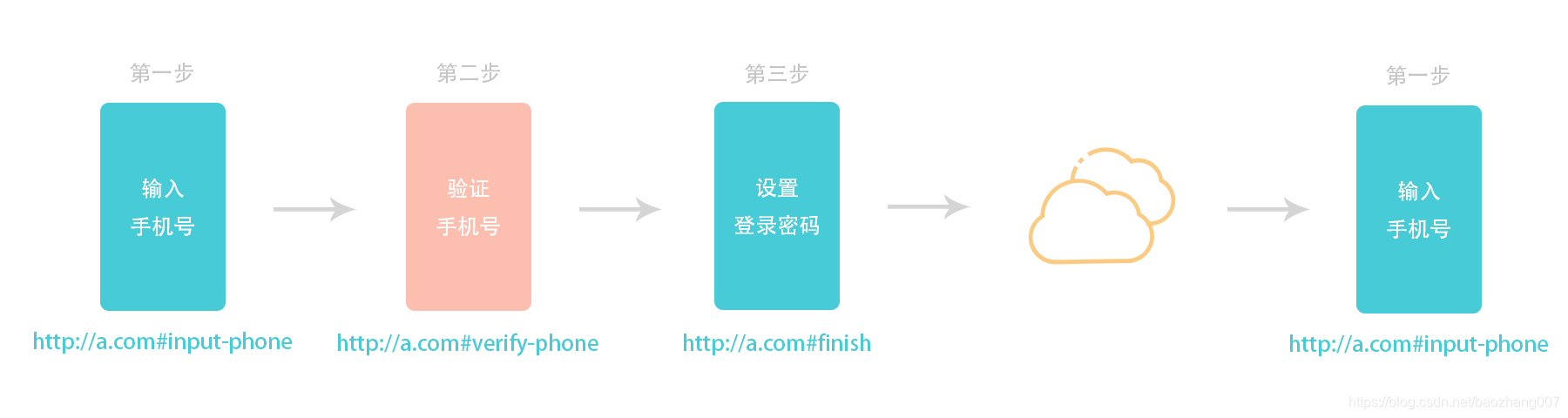
此时,无论传播前用户处于 第二步(verify-phone) 还是 第三步(finish),页面传播后浏览器均需要固定地呈现 第一步(input-phone)。而作为中间步骤的 第二步 和 第三步,其本身则是不能 “直接访问”的。
对此,View.js可以通过 设定视图不能直接访问 ,以及设定 回退视图 便可轻松实现。
加载耗时
由于单页应用预置了多个功能体, 因此页面打开时不可避免地要将所有功能体对应的样式和脚本下载至浏览器中。此时的页面资源加载情况如下图所示:

这些功能体的样式及脚本一般情况下在工程中独立存在。这也就意味着,如果不在发布环节做处理,代码的线上产品形态将等同于开发阶段的工程形态,那么当页面被访问时,浏览器将针对每个独立的资源分别加载。这无疑延长了页面的加载时长,变成了应用推广使用的一大绊脚石。
为了解决这一问题,同时尽可能地保持既有开发方式不变,我们需要引入 “发布” 环节。在发布环节,我们需要将样式和脚本等资源引用进行合并,使得页面源码中引用的多个资源在执行发布构建时最终能够被合并、压缩为一个资源,其效果如下图所示:
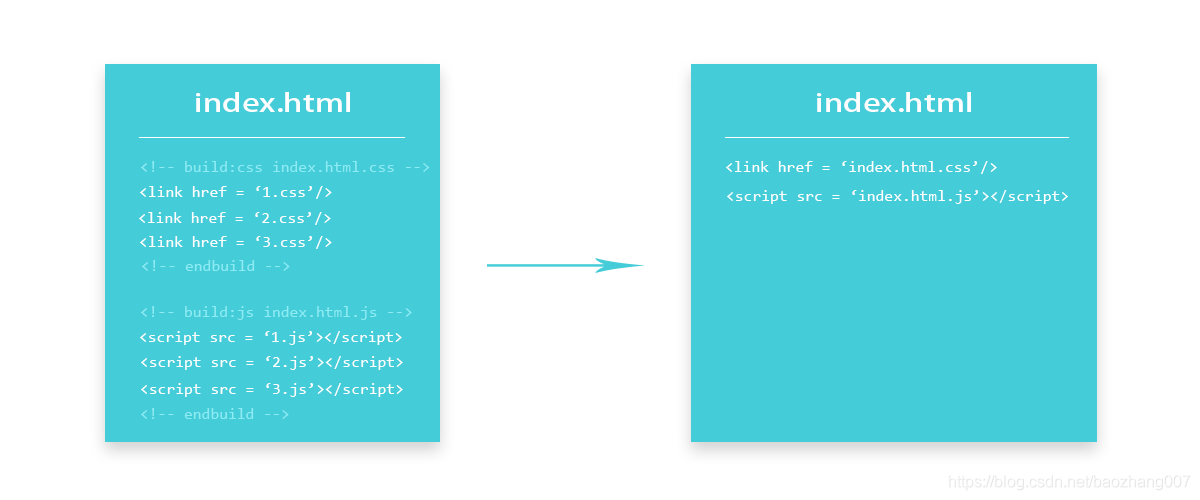
在不影响开发步骤的情况下,通过加入 <!-- build:js index.html.js --> 以及 <!-- build:css index.html.css --> 注释,借助 npm 插件:gulp-build-html 插件,便可以将 1.css,2.css 和 3.css 合并在一起生成 index.html.css,将 1.js,2.js 和 3.js 合并生成 index.html.js,同时自动调整html中的资源引用,将其变更为新生成的合并之后的文件。

有关 npm 插件:gulp-build-html 的更多说明,请开发者自行查阅,本文不再赘述。
错误保护
当我们通过构建脚本将多个脚本合并在一起的时候,如果没有添加防护措施,就会遇到 『错误影响范围扩大』 的问题。我们来看一看下面的代码:
/**
* 1.js
*/
var inputObj = document.querySelector("#page1 input");
console.log(a); // -> 抛出错误:Uncaught ReferenceError: a is not defined
inputObj.value = "1"; // 错误阻断了本行及后续脚本的顺序执行/**
* 2.js
*/
var a = "A";
console.log(a); // -> A在脚本合并之前,1.js 文件中的异常错误阻止了脚本的后续执行,2.js 文件中的所有脚本均可以正常执行。此时,错误的影响范围,是 1.js 文件中第 6 行及以后的脚本执行。
现在我们将脚本合并在一起:
/**
* all-in-one.js
*/
var inputObj = document.querySelector("#page1 input");
console.log(a); // -> 抛出错误:Uncaught ReferenceError: a is not defined
inputObj.value = "1"; // 错误阻断了本行及后续脚本的顺序执行
var a = "A"; // 错误阻断了本行及后续脚本的顺序执行
console.log(a); // 错误阻断了本行及后续脚本的顺序执行此时 2.js 中原本可以正常执行的的脚本将无法继续执行,而错误的影响范围,则是第 6 行之后所有脚本的顺序执行。
这一问题并没有什么好办法可以轻松解决。开发者可以手动地使用 try-catch 语法,通过包裹每个脚本的正文内容来规避上述问题。
上述几项问题,是开发单页应用要面临的多个主要问题,需要开发者在业务逻辑之外从框架层面去分析、解决。这是一项枯燥费时费力的事情,但不解决就永远绕不开,解决了就一劳永逸,为什么不呢?如果你不关心这些底层的实现机理,只是想要拿来为己所用,那么就放心地使用 View.js 吧。

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









