









 https://blog.youkuaiyun.com/bandaoyu/article/details/120485737
https://blog.youkuaiyun.com/bandaoyu/article/details/120485737概述
传统TCP/IP协议栈中,网卡先将数据DMA拷贝到内核空间的缓冲区,再由CPU将经过协议栈处理的数据拷贝到用户空间。
那么为什么不能放用户空间呢?网卡知道放到内核空间的哪个位置,是因为协议栈已经提前告知网卡缓冲区的地址。
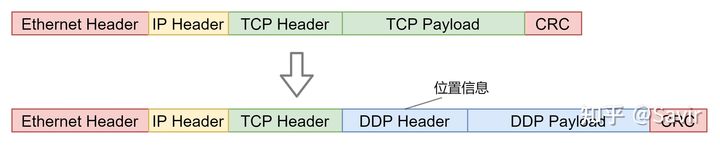
iWARP是在现有TCP/IP协议栈基础上实现RDMA技术,TCP/IP协议早已形成标准,不可能修改现有协议字段,增加DDP,既在TCP基础(或者是SCTP)上加一层,DDP的报文头中,携带了能够帮助网卡识别用户应用程序缓冲区的位置信息。
正文
原文:16. RDMA之DDP(Direct Data Placement) - 知乎
本文欢迎转载,转载请注明出处。
最近在研究iWARP的实现,就先写一下它的各层协议吧,iWARP的综述篇可能会晚于各层协议完成。
Direct Data Placement,简称为DDP,是iWARP协议栈的核心成员。DDP协议在TCP/SCTP之上实现了了RDMA技术中的零拷贝,即在通信过程中,使接收端的硬件可以直接把收到的数据放置到用户空间的Buffer,从而避免多次在Buffer间的拷贝数据对CPU产生的开销。
本文的主要目的是帮助大家快速且容易的了解DDP,内容主要是基于RFC4296和RFC 5041完成的,更多细节请参考原文。阅读本文前建议温习一下本专栏的基础概念篇。如有疑问或有错误需要更正,欢迎在评论区留言。
概述
我们先来看一下DDP试图解决什么样的问题:
每次数据在内存中的拷贝,都需要CPU一边通过总线从内存中读取数据,一边通过总线向内存中的另外一处写入数据。所以至少需要占用2倍于网卡带宽的CPU负载和3倍于网卡带宽的内存带宽(设备DMA写入一次,CPU读写各一次),因此有必要实现零拷贝技术来解放CPU和内存的带宽。
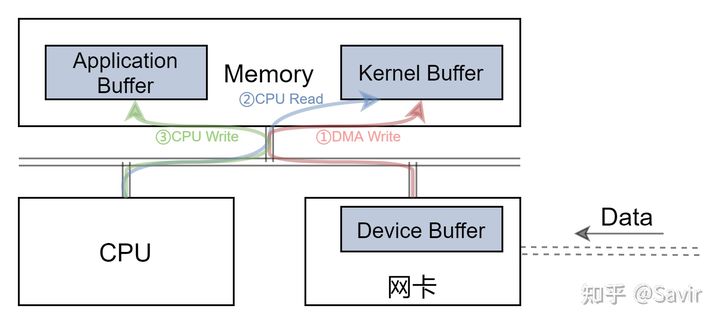
同一份数据,被DMA拷贝了一次(网卡-->驱动内存),CPU拷贝了一次(驱动内存-->应用内存)
Infiniband技术的RDMA Write/Read操作已经有了零拷贝的实现,是通过在报文中携带VA和R_Key的方式来实现的。接收端的硬件通过接收报文中的R_Key找到内存的VA-PA(虚拟地址-物理地址)转换表,然后把报文中的VA转换为PA,最后直接把Payload放到内存的对应位置中。

RDMA Extended Transport Header (RETH)
然而Infiniband使用的是全新设计的协议栈,硬件无法与现有网络兼容。之前我们讲过,如果用户想要从以太网切换到IB,那么需要把网卡、交换机、路由器和光缆等设备全部更换,将是很大的一笔开销。
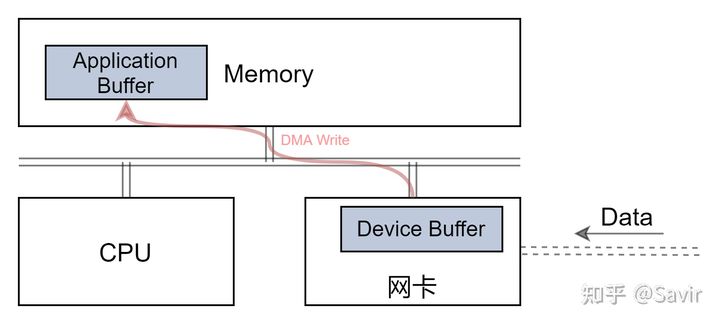
DMA技术在以太网卡中早已普及,即网卡收到消息后,可以在CPU不参与数据拷贝的情况下,就可以直接将数据放到指定内存区域中。
在传统的TCP/IP协议栈中,网卡要先将数据通过DMA拷贝到内核空间的缓冲区中,再由CPU将经过协议栈处理的数据拷贝到用户空间。
既然网卡可以直接将数据放到内核空间,那么为什么不能放用户空间呢?本质上只是地址不同罢了,之所以网卡知道放到内核空间的哪个位置,是因为协议栈已经提前告知网卡缓冲区的地址。同理,只要网卡有办法获取到用户空间内存地址对应的物理地址,就可以直接把数据放到用户空间了,也就是实现了不需要CPU参与的零拷贝:
iWARP的目标是在现有TCP/IP协议栈基础上实现RDMA技术,而DDP这一层的主要功能就是实现零拷贝。因为TCP/IP协议早已形成标准,不可能修改现有协议字段,所以DDP实现零拷贝的方案就是在TCP基础(或者是SCTP)上加一层,作为其负载。而DDP的报文头中,携带了能够帮助网卡识别用户应用程序缓冲区的位置信息。
DDP作为中间层,本身是不限制上层和下层协议的。只是在iWARP协议栈中,DDP向上为RDMAP服务,向下承接TCP(中间有一层很“薄”的MPA,我们在后文介绍)或者SCTP:
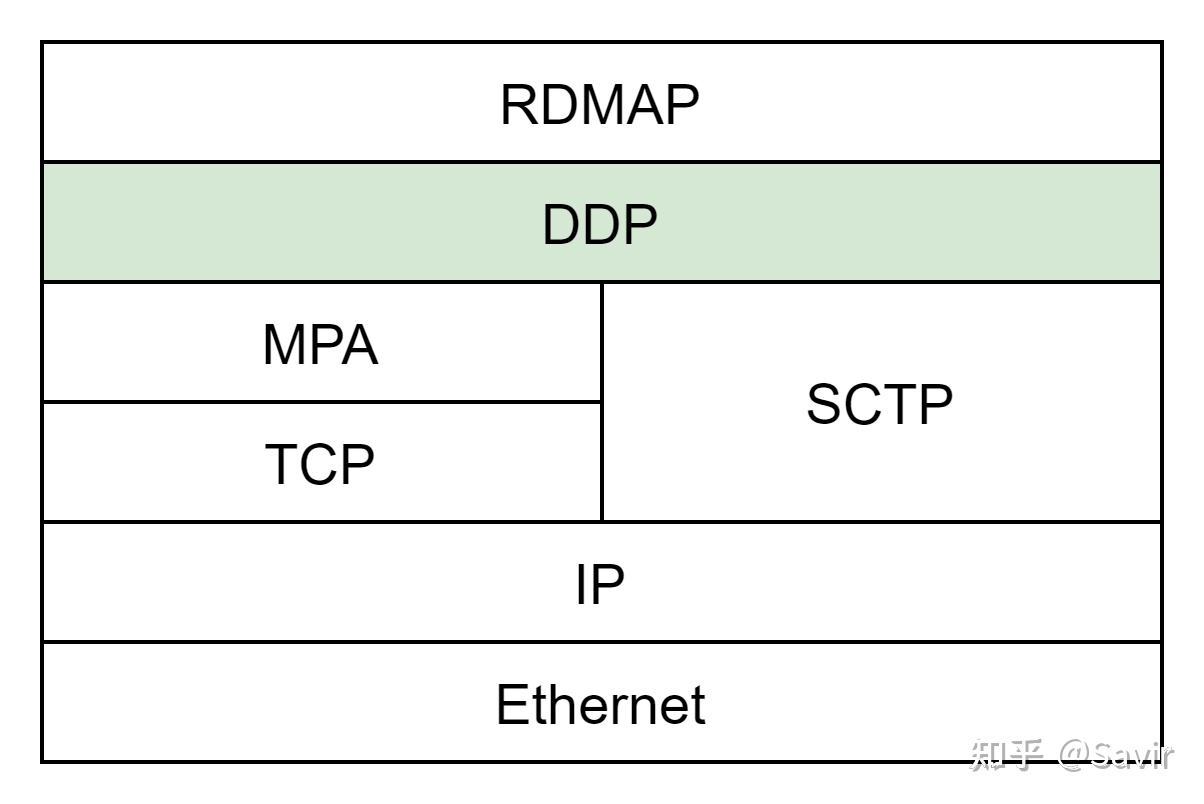
iWARP协议栈
术语
为了方便后文的讲解,我们先来对一些属术语进行说明。
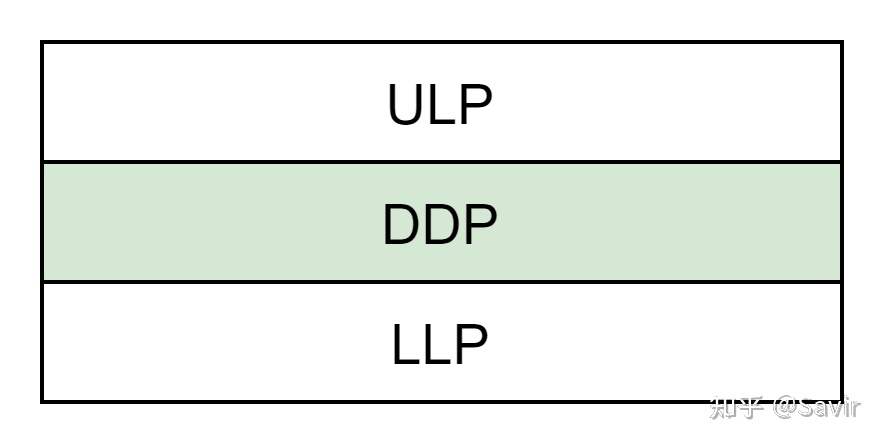
ULP
Upper Layer Protocol,上层协议。顾名思义,就是在DDP协议之上的其他协议,最常见的是iWARP协议栈中的RDMAP层。
RDMA Consortium 和 IBTA 主导了RDMA,RDMAC是IETF的一个补充,它主要定义的是iWRAP和iSER,IBTA是infiniband的全部标准制定者,并补充了RoCE v1 v2的标准化。应用和RNIC之间的传输接口层(software transport interface)被称为Verbs。IBTA解释了RDMA传输过程中应具备的特性行为,而并没有规定Verbs的具体接口和数据结构原型。这部分工作由另一个组织OFA(Open Fabric Alliance)来完成,OFA提供了RDMA传输的一系列Verbs API。OFA开发出了OFED(Open Fabric Enterprise Distribution)协议栈,支持多种RDMA传输层协议。
OFED中除了提供向下与RNIC基本的队列消息服务,向上还提供了ULP(Upper Layer Protocols),通过ULPs,上层应用不需要直接到Verbs API对接,而是借助于ULP与应用对接,常见的应用不需要做修改,就可以跑在RDMA传输层上。
LLP
Lower Layer Protocol,下层协议。跟ULP的含义相反,指的是DDP层之下的协议,最常见的是TCP和SCTP。
RNIC
指的是支持RDMA技术的网卡(RDMA enbled Network Interface Controller)。iWARP协议中一般称网卡为RNIC,而Infiniband和RoCE一般称为HCA(Host Channel Adapter)。
Node
指的是网络中的物理设备,即网络中的一个节点。一个Node可以包含多个RNIC。
Peer
我们将相互之间建立了连接的两个支持DDP协议的实体称为Peer,这个实体一般指的是用户应用程序。Peer一定是成对存在的,链路两端分别称为Local Peer和Remote Peer。
Node/Peer是两个不同层级的概念,Node是物理实体,Peer是协议实体。一个Node上可以有多个Peer。
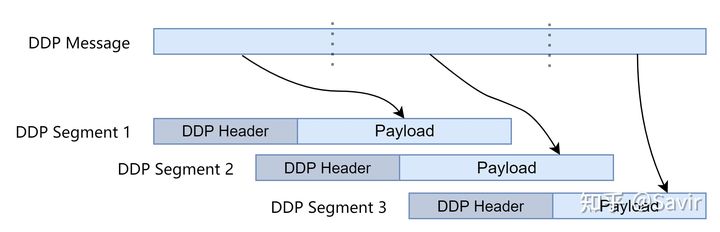
DDP Message
来自于ULP的数据,因为LLP的限制,这个Message可能会被切分成多个块,每个块都是一个DDP Segment。这些Segment中的数据最终会在接收端被提取出来还原成原来的Message。
DDP Segment
Message切分后产生的多个DDP分段。每个Segment都包含Header和Payload部分。Header部分包含的是控制信息,Payload就是实际的数据。
它们之间的关系如下图所示:
Data Sink
指接收数据的Peer,而不是接收DDP消息的Peer。比如在上层是RDMAP时,RDMA Read操作的发起方是最终接收数据的一方,所以是Data Sink;如果是RDMA Write操作,响应方是数据的接受者,所以它是Data Sink。
Data Source
指发送数据的Peer。
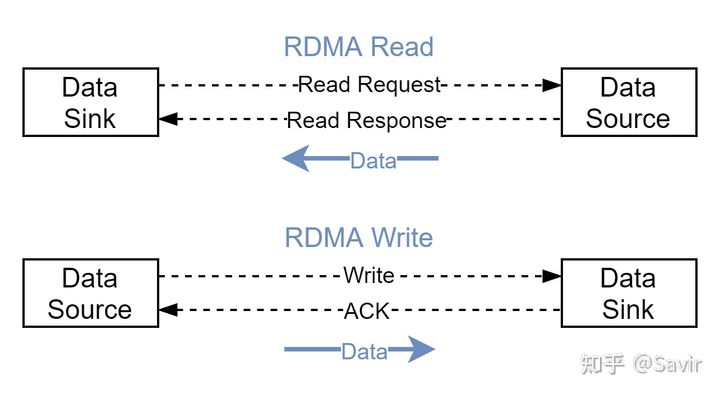
Data Sink和Data Source
Steering Tag (转向标签)
简称为STag,是指向Data Sink(Data Sink)的一片内存区域的标识符。通过STag,RNIC可以找到对应的内存的物理地址,并且对其进行读写。这个概念跟Infiniband协议中的R_Key和L_Key很像,只不过iWARP中的通信双方对于一片内存使用相同的STag,而没有区分本地访问和远端访问。
在注册指定的一片内存缓冲区之后,会产生一个STag,用于本地和远端用户访问这片内存。这个注册的过程是由ULP实现的,如果ULP是RDMAP,那么这个步骤就是注册MR的动作。注册MR的过程中,硬件会记录STag和内存位置的关系,然后驱动程序将STag返回给ULP。
Data Source的ULP可以将注册MR过程中产生的STag下发给硬件,以使其能够直接访问本地用户Buffer(比如post recv时下发给硬件的WR中指定的Buffer)。也可以把STag发送给对端,对端可以把这个STag携带在报文中,用于指定本端的一个Buffer。
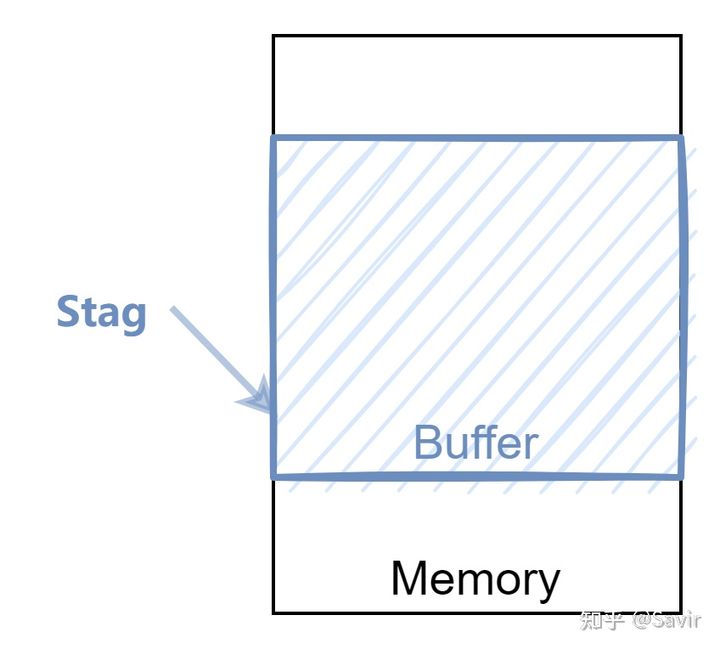
Advertisement
指的是将STag等地址信息告知对端的行为。这个行为是由ULP控制的,具体发送哪些信息,以什么格式发送都由上层决定。通常在通信准备阶段,Local Peer将一块内存区域注册到硬件,产生Stag等信息之后,将这些信息Advertise给Remote Peer。

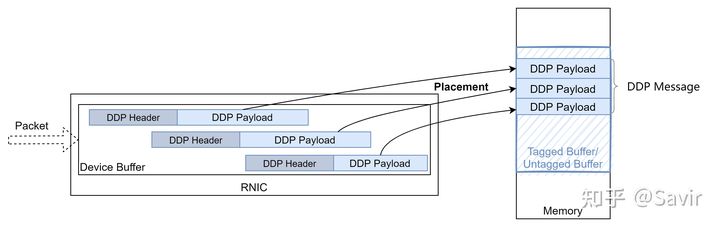
Placement
指的是RNIC根据DDP Header的信息把收到的DDP segment的Payload放到Buffer中的行为。
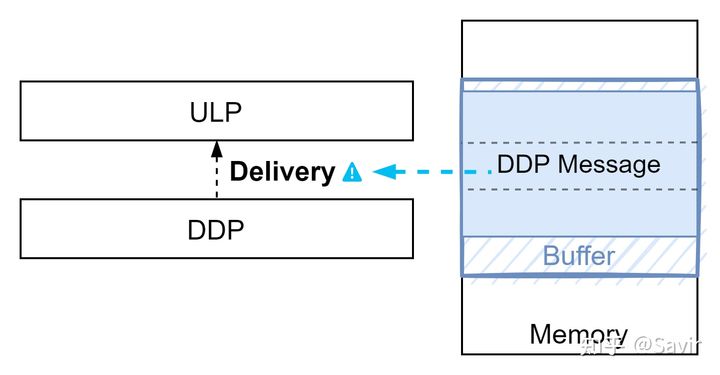
Delivery
通知ULP数据已经就绪的行为,即告诉ULP数据已经组装完毕,可以取走使用了。在一个DDP Message的所有Segment都放置完毕后,即已经在Buffer中还原出完整的数据后,DDP会通知ULP。
Buffer Model
根据数据接收端如何存放收到的数据,DDP中定义了两种接收缓冲区的类型:
Tagged Buffer Model
还记得IB规范中描述的RDMA Write操作和Read操作吗?Tagged Buffer Model类似于Infiniband规范中所描述的RDMA Write/Read操作。
ULP可以将STag以Socket/CM等方式发送给对端(即上文提到的Advertisement操作)。这样Data Source就可以通过在DDP Header中携带STag,来指定想要写入或者读取的Data Sink的内存区域。Data Sink的硬件通过STag找到内存中的目的地,从而可以在CPU不参与的情况下搬移数据。
因为DDP的Message可能会被下层的协议分成多个Segment,所以每个DDP分段都要在Header中携带STag。另外由于每个分段可能不按顺序到达对端,所以对端还需要额外的信息把这些分段拼接起来。DDP采用的方式是在Header中携带偏移信息TO(Tagged Offset),接收端的硬件可以通过这些偏移信息,一段一段的把每个DDP Segment的Payload放到STag指向的Buffer中的指定位置(即上文所说的Placement)。当一个消息的所有分段都被放到正确的位置之后,Message也就在接收端的内存被完整的还原了出来。
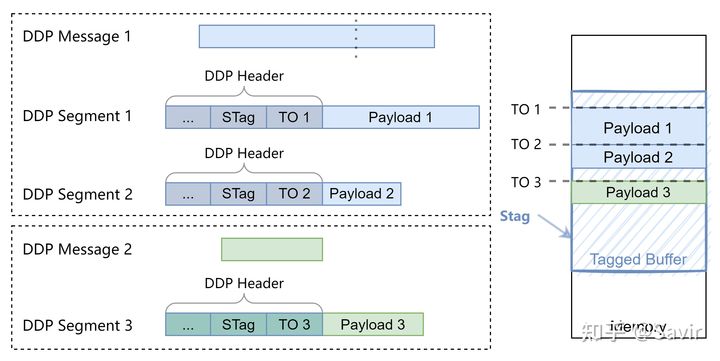
ULP并不知道从Tagged Buffer的哪个位置开始取数据,即上图中Message 1的起始位置TO 1或者Message 2的起始位置TO 3,它们也被称为Initial TO。ULP需要通过某种方式得到这个TO 1,根据RFC 5041中的描述,有几种解决办法:
- 如RDMAP协议一样,增加一些交互逻辑,提前知会对方这个偏移。
- 固定从Buffer的起始地址开始存放数据:即通信的双方约定好,每个消息都固定使用Initial TO = 0。
- 通过额外的方式告知:即发送Tagged DDP Message之后,紧接着发送一个Untagged DDP Message(下文介绍)来告知对端Initial TO。
Untagged Buffer Model
DDP中的Untagged Buffer Model,类似于IB规范中的Send-Recv操作中的接收方式。它并不会用STag来指定对端的特定缓冲区,这也是它被称为“Untagged”的原因。
这种模型下,Data Sink提前准备好了一些接收队列,这些队列中各存放了一些接收Buffer。Data Source不会在Header中携带STag,而是指定了队列号,这样Data Sink的RNIC收到数据后,就会从指定的队列中取出一个Buffer,把数据放到其中。不同的队列可以用于传递不同的信息,比如一个队列用来接收ULP的数据,另一个队列用来接收ULP的控制信息。
Untagged Buffer Model同样面临着分段后重组的问题,所以也需要在每个Segment中携带偏移信息,Untagged模型下的偏移信息被称为MO(Message Offset)。但是跟Tagged Buffer Model不同,它最终数据放到哪里是由接收端决定的,而且一个接收队列中有很多个Buffer。而同一组消息,是不可能放到不同的Buffer中的,因此需要将一个Message的不同Segment关联起来。DDP设计采用了队列号QN+消息序号MSN(Message Sequence Number)的方式来指定唯一的接收Buffer,这样一个Message的不同Segment就可以被还原到同一个缓冲区中了。
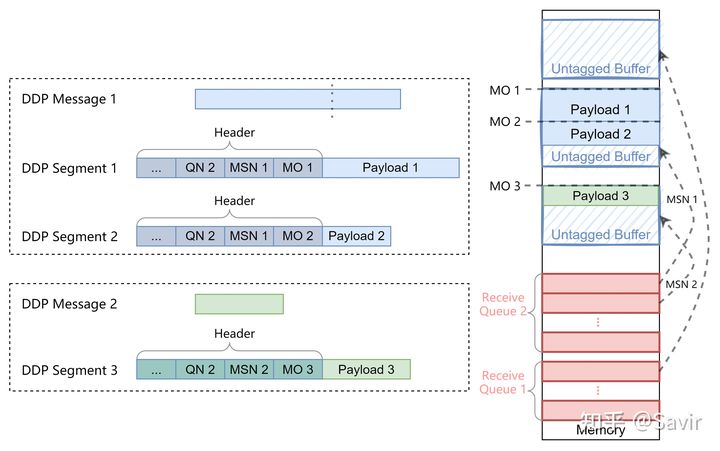
除了上面的描述之外,RFC 5041还对DDP的这两种模型做了另外的规定:
每个Untagged Buffer只能给一个DDP Message从0开始使用,而每个Tagged Buffer都可以给多个DDP Message共享使用,并且可以从任意位置开始存放数据。在上面两张图中,我也体现了这个规则。
我们来总结一下Tagged和Untagged Buffer Model的差异:
| Tagged Buffer | Untagged | |
|---|---|---|
| 接收Buffer | 用Tag指定使用哪个接收Buffer(发送端指定) | 按照接收顺序依次放到队列的接收缓冲区中(接收端指定) |
| 发送前准备 | 接收端ULP需要通知发送端ULP缓冲区的信息 | 不需要准备,可随时发起(需要考虑流控) |
| 偏移 | 从tagged buffer的任意位置开始 | 只能从0开始 |
| 多DDP消息 | 允许使用同一个ULP Buffer | 需要为每个DDP消息准备一个ULP Buffer |
报文格式
下面来看一下DDP协议的报文包含哪些字段,以及它们的含义和作用。本小节是RFC 5041第4章的翻译和再整理,建议读者先阅读原文以获得更精确的描述。
大家可以从Wireshark官网获取抓好的报文:
https://gitlab.com/wireshark/wireshark/-/wikis/SampleCaptures#infiniband
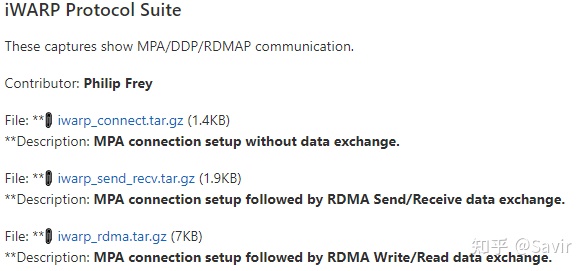
建议选择iwarp_rdma.tag.gz,因为里面包含了Tagged/Untagged Buffer Model两种情况。
DDP Header
依据Buffer Mode的不同,DDP Header有两种格式,但是这两种格式有几个公共域段:

前两个字节是给MPA(Marker Protocol data unit Aligned framing)预留的,在iWARP协议栈中它是TCP和DDP的中间层。如果LLP是STCP,那么就不需要预留这两个字节。我们会在以后的文章中介绍。
- T - Tagged flag: 1bit
这个标志位用来标识是哪种Buffer模型。值为1时表示Tagged Buffer Model,值为0时表示Untagged Buffer Model。硬件是依据这一个bit来决定如何解析后面的域段的。 - L - Last flag: 1bit
用于标识一个Message的最后一个Segment。上文中我们介绍过,一个DDP Message会被拆分成多个Segment,只有最后一个Segment的这个标志位会被置1。- 对于发送端来说,置了这个标志的Segment必须是在同属于一个Message的Segment中的最后一个下发给LLP。
- 对于接收端来说,如果收到了置了此标志位的Segment,必须在同属于一个Message的Segment的Payload都已经完成Placement和所有之前的Message都处理完毕之后通知ULP数据已经可用(Delivery)。
- Rsvd - Reserved: 4 bits
保留域段,必须为0。 - DV - DDP Version: 2 bits
DDP版本。为以后的扩展性考虑,目前只有一个DDP版本,所以恒为1。
Tagged Buffer Model
Tagged Buffer Model的Header总长度为14个字节。

- RsvdULP - Reserved for use by the ULP: 8 bits
ULP保留域段。这个域段是由ULP定义的,DDP不关心其含义,只需要保证一个Message的每个Segment的该域段保持一致和不变就可以了。在Data Sink,该域段会被原封不动的传递给ULP。 - STag - Steering Tag: 32 bits
前文已经介绍过,用来指定一个Data Sink的Tagged Buffer。DDP需要保证一个Message的每个Segment的该域段保持一致和不变。 - TO - Tagged Offset: 64 bits
上文也已经介绍过,用来表示Payload在Tagged Buffer中从Buffer的起始地址到最终数据的存放地址的偏移。
Untagged Buffer Model
总长度为18字节。

- RsvdULP - Reserved for use by the ULP: 40 bits
虽然跟Tagged Buffer Model中的作用相同,但是这里扩展到了5个字节,并且RFC 5041中补充了一段:
Data Sink端的DDP实现不需要确认一个DDP Message的每个Segment的此域段是否都相同,并且可以选择任何一个Segment的Rsvd ULP传递给ULP。
具体为什么加这句话还没有想明白,可能跟上层有关系。
- QN - Queue Number: 32 bits
上文中介绍过,指的是Data Sink端的Untagged Buffer队列的序号。 - MSN - Message Sequence Number: 32 bits
DDP Message的序列号。必须从1开始,每次递增1。当到达0xFFFFFFFF之后,重新变为0。每个Message都只能对应一个Untagged Buffer,所以MSN+QN能够唯一确定一个Untagged Buffer。 - MO - Message Offset: 32 bits
上文中介绍过,表示从QN和MSN确认的Untagged Buffer的起始位置到消息目的地址的偏移。不难想到,第一个Segment的MO一定为0。
DDP Payload
DDP Header后面紧跟的就是Payload,没有什么需要特别注意的。
实验
因为Wireshark提供的示例太简单,都是不分段的DDP消息,建议大家使用支持iWARP的网卡或者使用虚拟机+Soft-iWARP跑一些更复杂的业务来做实验。
本文接下来的实验是通过虚拟机+Soft-iWARP实现的。iWARP和Soft-iWARP的详情我将在以后的文章中介绍,目前仅给出简单的配置过程。
环境配置请参考《RoCE & Soft-RoCE》这篇文章的“如何做实验”这一章节。差异点仅在于rxe需要改为siw(Soft-iWARP)。
为了避免干扰,如果读者的环境中已经配置了RXE,那么请使用下述命令删除Soft-RoCE设备:
sudo rdma link delete rxe_0然后加载siw驱动:
sudo modprobe siw添加siw设备:
sudo rdma link add siw_0 type siw netdev ens33此时我们用ibv_devices就能看到新添加的siw设备了:

虚拟机两端都配置好了之后,就可以跑perftest测试了。执行之前请先在宿主机打开wireshark,并选择对应的虚拟网卡。
因为RDMA Read的交互相对更复杂,所以我们在两个虚拟机执行的是ibv_read_bw(ibv_send_bw执行会报错,原因还未搞清楚):
ib_write_bw -d siw_0 -R -n 5 -s 1500
ib_write_bw -d siw_0 -R -n 5 -s 1500 192.168.217.128其中,-R表示使用CM建链(Socket建链不通,原因未知);-n 5表示跑5轮测试,毕竟是个测试性能的工具,循环次数越多,结果越可信。因为我们只关心报文,所以取了perftest迭代次数的最小值5;-s是消息长度,也就是用户数据的长度,取1500我是为了能够演示把payload切成多个DDP的数据包,其他值亦可。
所以我们这次跑的测试的内容是:使用CM建链,client端从server端使用RDMA Read操作读回长度为1500的数据,循环5次。

执行完毕后我们来看一下抓包结果,我们只关注其中的DDP/RDMA协议。
Send
取一个Send操作的DDP Segment,首先我们可以看到自上而下是从Ethernet层到DDP/RDMAP层的清晰的层次关系:
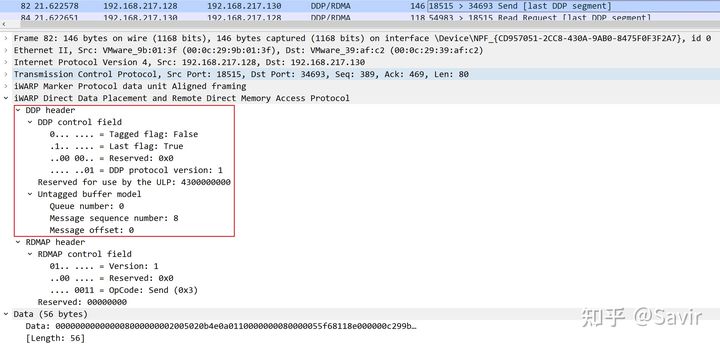
这个DDP消息是用来交换双方的信息的,我们不关注具体内容,只看它的Header。从其中我们可以得到以下信息:
- 这是一个Untagged Buffer Model的报文
- 是整个DDP Message的最后一个Segment
- DDP协议版本是1
- 接收队列的QN是0
- 消息序列号是8,说明之前0号队列已经接受了7个消息了
- 消息偏移是0,说明数据会放到Buffer的头部(也说明这个Message只有1个Segment)
RDMAP和MPA的内容我们会在以后的文章中讲解,目前不用关心。
RDMA Read
首先来看Client端发给Server的RDMA Read Request的DDP Message:
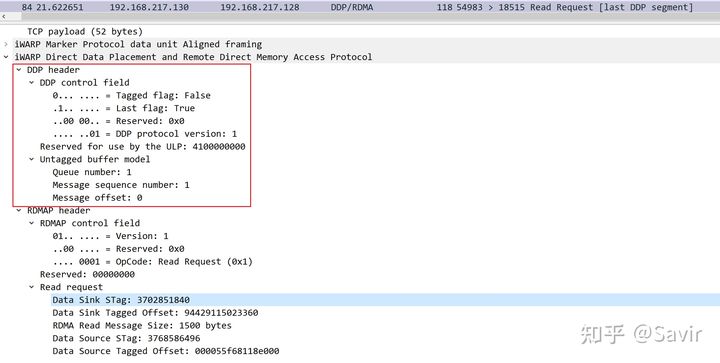
还是只看DDP Header部分,发现这也使用了Untagged Buffer,并且只有一个Segment,就不每个字段都解释了。Read Request本身不携带用户数据,可以看到下面的RDMAP Header中携带的是两端的Buffer的信息。
然后我们来看紧跟其后的RDMA Read Request的DDP Message:

首先比较明显的是,这个Message包含两个Segment:
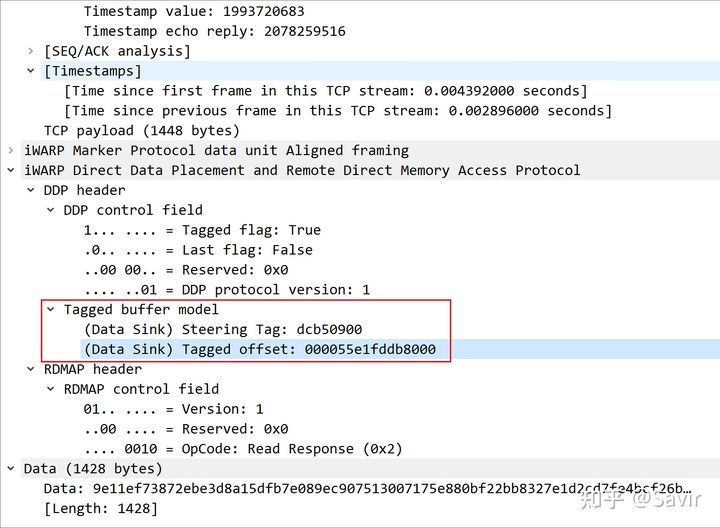
Segment 1
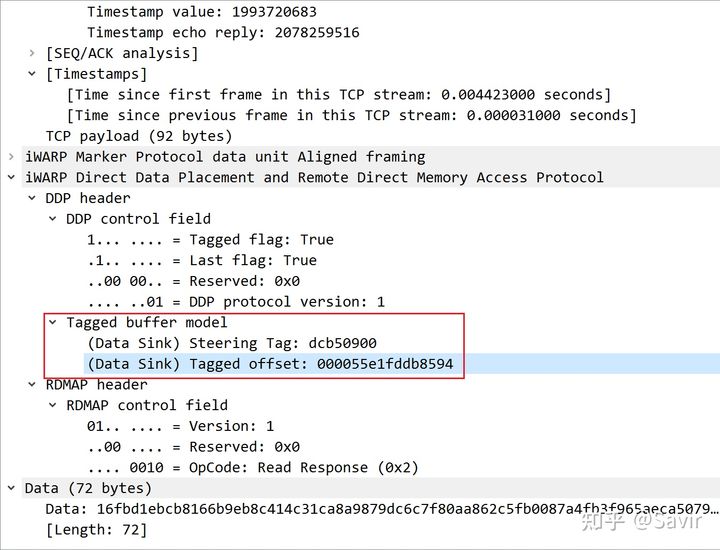
Segment 2
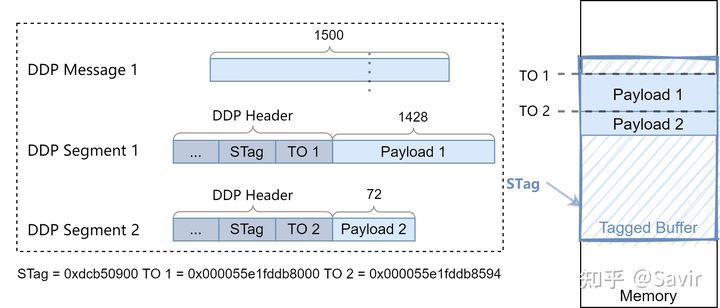
它们使用的是Tagged Buffer Model,使用相同的STag,TO偏移相差0x594(1428)。
我们重点来看一下这个TO是怎么来的。
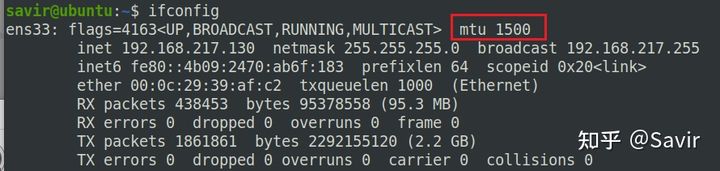
环境中两端虚拟机网卡的MTU都是1500,说明Ethernet层之上的内容,需要切割成1500字节为单位的单元。因为要包含各层的Header以及校验信息,所以最终的Payload肯定不能是1500。
只需要用1500减去各种控制信息,我们就可以知道负载的长度:
1500 - 20 - 32 - 2- 14 - 4 = 1428
这里的TCP Header中包含了可选项Timestamp,所以长度不是20字节,而是32字节。

所以第一个DDP Segment只能承载1428字节的Payload,剩余的72个字节要放到第二个Segment中。
另外我们从上面的抓包结果我们也可以看出,正如RFC 5042中指出的那样,DDP Untagged Buffer Model通常都用于传递一些控制信息,数据读写更多的还是使用Tagged Buffer Model。
除了上述内容外,RFC 5041还介绍了DDP流的建立和销毁、错误检测和安全机制等内容。我将在RDMAP的文章中一并讲解。
好了,本文就到这里,下一篇打算介绍iWARP和Soft-iWARP或者RDMAP。
参考资料
[1] RFC 5041
[2] RFC 5042
[3] Understanding iWARP. https://www.intel.com/content/dam/support/us/en/documents/network/sb/understanding_iwarp_final.pdf

















 4063
4063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









