



大部分取自 数据库原理知识梳理 - 知乎
sql语法大全:SQL 语法 | 菜鸟教程
重要概念梳理
1.三级模式:外模式,模式,内模式
抽象:
数据库模式(三级模式+两级映射)_JAVA和人工智能的博客-优快云博客_数据库三级模式
形象:
补充:
DML常用于外模式,而DDL常用于模式
DML(data manipulation language):数据操作语言。它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言。
DDL(data definition language):数据定义语言。DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。
DCL:数据控制语言。用来授予和撤销用户对数据的操作权限,由动词 grant, revoke 组成
2.范式:1NF 2NF 3NF BCNF
使用范式可以使数据库的表更加规范化
目前关系数据库有六种范式:满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多要求的称为第二范式(2NF),其余范式以次类推。
一般说来,数据库只需满足第三范式(3NF)就行了。
第一范式(1NF)
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
第一范式为:数据库表中的字段都是单一属性的,不可再分。
例如:这是符合规则的
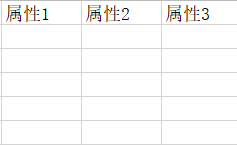
而这样是不符合规则的
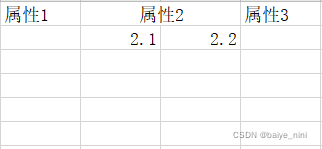
第二范式(2NF)
①满足第二范式(2NF)必须先满足第一范式(1NF)。
②第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主关键字或主键、主码。
③第二范式(2NF)要求实体的属性完全依赖于主关键字。
假定选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),关键字为组合关键字(学号, 课程名称),因为存在如下决定关系:
(学号, 课程名称) → (姓名, 年龄, 成绩, 学分)这个数据库表不满足第二范式,因为存在如下决定关系:
(课程名称) → (学分)
(学号) → (姓名, 年龄)即存在组合关键字中的字段决定非关键字的情况。
由于不符合2NF,这个选课关系表会存在如下问题:
(1) 数据冗余:同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。
(2) 更新异常:若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。
(3) 插入异常:假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号"关键字,课程名称和学分也无法记录入数据库。
(4) 删除异常:假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。
把选课关系表SelectCourse改为如下三个表:
学生:Student(学号, 姓名, 年龄);
课程:Course(课程名称, 学分);
选课关系:SelectCourse(学号, 课程名称, 成绩)。这样的数据库表是符合第二范式的, 消除了数据冗余、更新异常、插入异常和删除异常。
所有单关键字的数据库表都符合第二范式
第三范式(3NF)
①满足第三范式(3NF)必须先满足第二范式(2NF)。
②第三范式就是属性不依赖于其它非主属性。说的专业点,就是非主属性对任一候选主属性不会产生传递函数依赖。
假定学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),关键字为单一关键字"学号",因为存在如下决定关系:
(学号) → (姓名, 年龄, 所在学院, 学院地点, 学院电话)这个数据库是符合2NF的,但是不符合3NF,因为存在如下决定关系:
(学号) → (所在学院) → (学院地点, 学院电话)即存在非关键字段"学院地点"、"学院电话"对关键字段"学号"的传递函数依赖。
这样的表同样会产生数据冗余、更新异常、插入异常和删除异常。
把学生关系表分为如下两个表:
学生:(学号, 姓名, 年龄, 所在学院);
学院:(学院, 地点, 电话)。这样的数据库表是符合第三范式的,消除了数据冗余、更新异常、插入异常和删除异常。
达成3NF范式,并不证明表的逻辑完全没有bug,只是达到了一般数据库表的最低要求。
三.索引,视图,触发器,事务,存储过程
3.1索引
①用户无法看到索引,它们只能被用来加速搜索/查询。
②更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引本身也需要更新。
③主键,外键必须要建立索引。另外,常出现在where中的属性也可以建立索引。
在表上创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name
ON table_name (column_name)在表上创建一个唯一的索引。不允许使用重复的值:唯一的索引意味着两个行不能拥有相同的索引值。
CREATE UNIQUE INDEX index_name
ON table_name (column_name)3.2视图
视图是虚拟的表,是基于 SQL 语句的结果集的可视化的表。与普通的表一样,可以对视图进行curd。
/*建立视图*/
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
/*更新视图*/
create or replace view 视图名
as
查询语句;
/*或着*/
alter view 视图名
as
查询语句;
/*删除视图*/
DROP VIEW view_name关于视图详细的说明:
 https://blog.youkuaiyun.com/weixin_47421889/article/details/106968175
https://blog.youkuaiyun.com/weixin_47421889/article/details/1069681753.3触发器
触发器是一种特殊类型的存储过程。
触发器主要是通过事件进行触发被自动调用执行的。而存储过程可以通过存储过程的名称被调用。(存储过程在3.5)
sql2005中,触发器有DDL,DML两种。
DML触发器分为:
1、 after触发器(之后触发)。仅定义在表
a、 insert触发器
b、 update触发器
c、 delete触发器
2、 instead of 触发器 (之前触发)。可以定义在表,视图
触发器有两个特殊的表:插入表(instered表)和删除表(deleted表)。Inserted表的数据是插入或是修改后的数据,而deleted表的数据是更新前的或是删除的数据。
这两张是逻辑表也是虚表。
系统在内存中创建这两张表,不会存储在数据库中。而且两张表的都是只读的,只能读取数据而不能修改数据。
这两张表的结果总是与被改触发器应用的表的结构相同。
当触发器完成工作后,这两张表就会被删除。
/*建立触发器基本框架*/
create trigger trigger_name
on {table_name|view_name}
{After|Instead of} {insert|update|delete}
as
触发器执行条件,如if(select 状态 from 商品,inserted where 商品.pid = inserted.pid)=1
begin
触发器执行动作
end
/*1.建立instead of-delete触发器*/
create trigger trigger_学生_Delete
on 学生
instead of Delete
as
begin
select 学号, 姓名 from deleted
end
/*当执行
delete from 学生 where 学号 = 4
会发现delete未起作用,原因在于触发器阻止了delete操作,
而是执行了select 学号, 姓名 from deleted*/
/*2.建立after-insert触发器*/
create trigger trigger_订单_insert
on 订单
after insert
as
if (select 状态 from 商品,inserted where 商品.pid = inserted.pid)=1
begin
print 'the goods is being processed'
print 'the order cannot be committed'
rollback transaction --回滚,避免加入
end
/*修改触发器*/
alter trigger trigger_name
on {table_name|view_name}
{After|Instead of} {insert|update|delete}
as 相应T-SQL语句
/*4.删除触发器*/
drop trigger trigger_name
3.4事务
一个事务中可以包含多个DML语句,一个DDL语句或者一个DCL语句。
事务是保持逻辑数据一致性与可恢复性,必不可少的利器。
事务中的语句要么全部执行,要么全部不执行。
在SQL Server中事务被分为3类常见的事务:
- 自动提交事务:是SQL Server默认的一种事务模式,每条Sql语句都被看成一个事务进行处理,你应该没有见过,一条Update 修改2个字段的语句,只修该了1个字段而另外一个字段没有修改。 如上节的触发器2.after-insert代码块中,after insert一句中的insert就是一个事务,触发器使用了Rollback Transaction回滚事务,避免了insert这一事务的执行。
- 显式事务:由Begin Transaction开启事务开始,由Commit Transaction 提交事务、Rollback Transaction 回滚事务结束。
- 隐式事务:使用Set IMPLICIT_TRANSACTIONS ON 将将隐式事务模式打开,不用Begin Transaction开启事务,当一个事务结束,这个模式会自动启用下一个事务,只用Commit Transaction 提交事务、Rollback Transaction 回滚事务即可
---开启事务
begin tran
--错误捕捉机制,看好啦,这里也有的。并且可以嵌套。
begin try
--语句正确
insert into lives (Eat,Play,Numb) values ('猪肉','足球',1)
--Numb为int类型,出错
insert into lives (Eat,Play,Numb) values ('猪肉','足球','abc')
--语句正确
insert into lives (Eat,Play,Numb) values ('狗肉','篮球',2)
end try
begin catch
select Error_number() as ErrorNumber, --错误代码
Error_severity() as ErrorSeverity, --错误严重级别,级别小于10 try catch 捕获不到
Error_state() as ErrorState , --错误状态码
Error_Procedure() as ErrorProcedure , --出现错误的存储过程或触发器的名称。
Error_line() as ErrorLine, --发生错误的行号
Error_message() as ErrorMessage --错误的具体信息
if(@@trancount>0) --全局变量@@trancount,事务开启此值+1,他用来判断是有开启事务
rollback tran ---由于出错,这里回滚到开始,第一条语句也没有插入成功。
end catch
if(@@trancount>0)
commit tran --如果成功Lives表中,将会有3条数据。
--表本身为空表,ID ,Numb为int 类型,其它为nvarchar类型
select * from lives
3.5存储过程
上文中提到,触发器是特殊的存储过程。那么存储过程是什么呢?
存储过程Procedure是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。
存储过程的优点:由于存储过程在创建时即在数据库服务器上进行了编译并存储在数据库中,所以存储过程运行要比单个的SQL语句块要快。同时由于在调用时只需用提供存储过程名和必要的参数信息,所以在一定程度上也可以减少网络流量、简单网络负担。
存储过程有系统存储过程和用户自定义存储过程。
/*建立存储过程*/
create proc | procedure pro_name
[{@参数数据类型} [=默认值] [output],
{@参数数据类型} [=默认值] [output],
....
]
as
SQL_statements
/*调用存储过程(无参数的)*/:
call [procedure pro_name]
/*调用存储过程(有参数的)*/
call [procedure pro_name](@参数1, @参数2, @参数3)存储过程的详细讲解:SQL Server 存储过程 - hoojo - 博客园 https://www.cnblogs.com/hoojo/archive/2011/07/19/2110862.html
https://www.cnblogs.com/hoojo/archive/2011/07/19/2110862.html
四.并发操作,排他锁,共享锁
并发操作会引起三类问题:
- 丢失更新:写写冲突,加排它锁X
- 读“脏”数据:写读冲突,加共享锁S
- 不可重复读:读写冲突
加锁原则:
拿MySql的InnoDB引擎来说,对于insert、update、delete等操作。会自动给涉及的数据加排他锁;
对于一般的select语句,InnoDB不会加任何锁,事务可以通过以下语句给显示加共享锁或排他锁。
共享锁:又称为读锁,获得共享锁的事务,可以查看但无法修改和删除数据。其他事务只能再加共享锁。
在查询语句后面增加LOCK IN SHARE MODE,Mysql会对查询结果中的每行都加共享锁。
SELECT ... LOCK IN SHARE MODE;
排他锁:又称为写锁、独占锁,获得排他锁的事务,既能读数据,又能修改数据。其他事务不能加任何类型的锁。
在查询语句后面增加FOR UPDATE,Mysql会对查询结果中的每行都加排他锁
SELECT ... FOR UPDATE;
五.表连接方式
待更新-

















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









