




 本文介绍了机器学习的过程,包括模型选择、训练与验证。对比了深度学习与经典机器学习的区别,并指出深度学习能解决维度诅咒问题。同时,讨论了SVM的局限性,如手动设计特征和处理大数据集的能力不足。感知机和人工神经网络作为深度学习的基础也得到了提及。
本文介绍了机器学习的过程,包括模型选择、训练与验证。对比了深度学习与经典机器学习的区别,并指出深度学习能解决维度诅咒问题。同时,讨论了SVM的局限性,如手动设计特征和处理大数据集的能力不足。感知机和人工神经网络作为深度学习的基础也得到了提及。
PyTorch深度学习实践学习笔记(1)——b站刘二大人
机器学习的过程:从数据集中把算法找出来
1)找出模型;
2)拿数据做训练;
3)验证模型。
基于规则的系统:输入——手动设计程序——输出;
经典的机器学习:输入——手动选取特征——建立映射函数关系——输出;
表示学习:(提取Features)

维度诅咒:input中feature数量多,维度变高,对数据的需求量会增大,工作量大。
降维:n维空间——3维空间
[3×1]=[3×n][n×1] ——找出3×n矩阵
深度学习:(训练过程是对整个模型进行训练,不分开)

SVM问题
1)手工设计功能的限制;
2)不能很好地处理大数据集;
3)越来越多的应用程序需要处理非结构化数据。
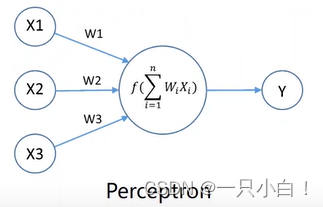
感知机与人工神经网络


















 1867
1867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









