



 本文探讨了在MySQL中如何高效地对数据进行分组并选取每个分组的第N条记录,对比了传统方法与使用set变量的性能差异,通过实例展示了10万数据量下的优化效果。
本文探讨了在MySQL中如何高效地对数据进行分组并选取每个分组的第N条记录,对比了传统方法与使用set变量的性能差异,通过实例展示了10万数据量下的优化效果。
查询思路:
很多时候想在使用group by时想查询group by的每一组中的第N条数据,而取这些数据时往往按如下方式去执行则很慢
SELECT * FROM test main WHERE (SELECT COUNT(1) FROM test sub WHERE main.uid = sub.uid AND main.gid > sub.gid ) < 3;
按如上方式,对于数据10000左右的表就已经很吃不消。
或已拼接结构的方式
SELECT t.a,t.b
,substring_index( group_concat( IFNULL(t.c,0)ORDER BY t.itime DESC ), ",", 3 ) c
,substring_index( group_concat( t.itime ORDER BY t.itime DESC ),",", 3) time
FROM t t GROUP BY t.a ,t.b;
等等这些单存对sql来说并不是想要的方案,效率太慢,
如下,是借用mysql的set变量来处理,10w的数据效率还不错,就贴出来了。
在如下结果集中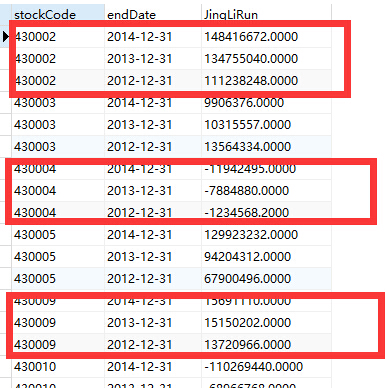
标记好的结果
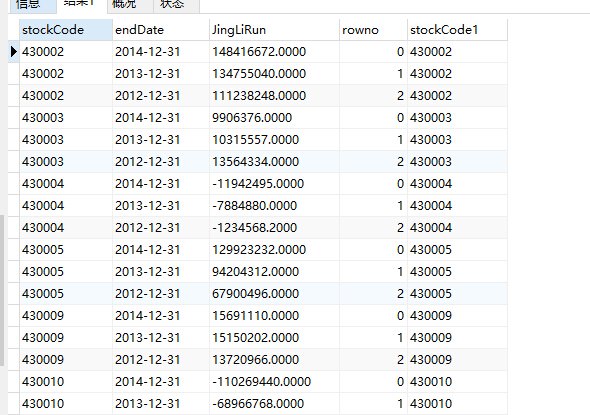
sql语句(为取其中的某一类型)
set @rowNO = 0;-- 定义序列变量 set @codeTemp = '';-- 定义每组区别变量 select * from ( select i.* ,-- 字段值 if(@codeTemp=stockCode,@rowNO := @rowNo+1,@rowNO := 0) AS rowno,-- 赋值序列 @codeTemp:=stockCode as stockCode1 -- 赋值区别 from ( select i.stockCode,i.endDate,i.JingLiRun from income_statements i WHERE i.endDate like '%-12-31' order by stockCode,i.endDate desc -- 可自定义的临时表数据 ) i ) i where i.rowno = 1 -- 取每组第N条
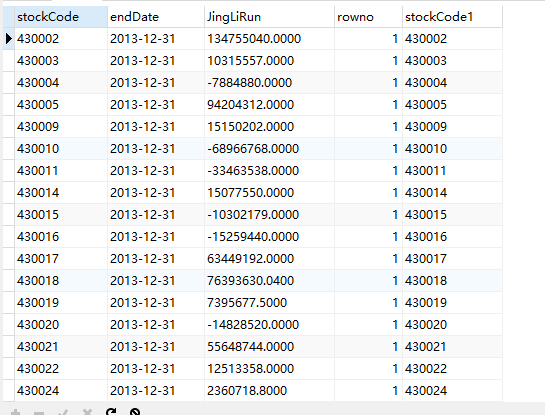
如有更好的欢迎分享

















 174万+
174万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









