






淘宝页面是JS动态页面,需要selenium模仿chrome访问淘宝.
新建项目
scrapy startproject taobao
cd taobao
scrapy genspider example www.taobao.com
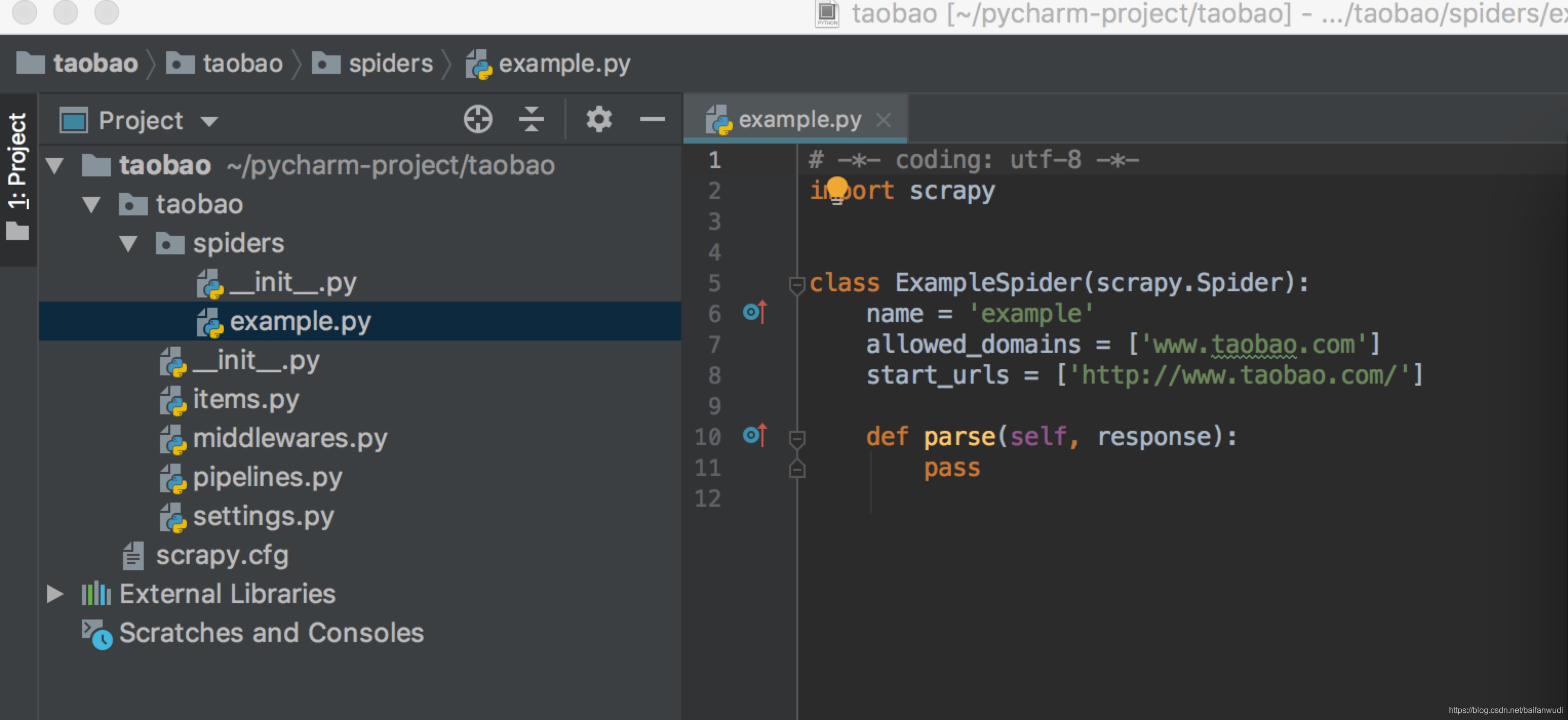
结构图下图:
安装seleniumpip install -U selenium并下载chromediver
编写middleware.py文件中TaobaoDownloaderMiddleware类;
增加
from scrapy import signals
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import TimeoutException
....
class TaobaoDownloaderMiddleware(object):
def __init__(self):
options = Options()
options.add_argument('--headless') # 使用无头谷歌浏览器模式
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
self.driver = webdriver.Chrome(chrome_options=options, executable_path='/opt/driver/chromedriver')
def __del__(self):
self.driver.close()
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
try:
print("Chrome driver begin....")
self.driver.get(request.url)
html = self.driver.page_source
return HtmlResponse(url=request.url, body=html.encode('utf-8'), encoding='utf-8', request=request)
except TimeoutException:
return HtmlResponse(url=request.url, request=request, encoding='utf-8', status=500)
finally:
print('Chrome driver end...')
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
这里面调用了chromedirver,executable_path=’/opt/driver/chromedriver’是为下载好的chromediver路径。process_request就是模仿浏览器去解析js,返回html。
在setting.py中
#取消注销
DOWNLOADER_MIDDLEWARES = {
'taobao_crawler.middlewares.TaobaoCrawlerDownloaderMiddleware': 543,
}
#增加
FEED_EXPORT_ENCODING ='utf8'
KEYWORDS = ['zara']
MAX_PAGE = 2
修改example.py文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from urllib.parse import quote
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['www.taobao.com']
# start_urls = ['http://www.taobao.com/']
base_url = 'https://s.taobao.com/search?q='
def start_requests(self):
for keyword in self.settings.get("KEYWORDS"):
for page in range(1, self.settings.get("MAX_PAGE") + 1):
url = self.base_url + quote(keyword)
yield Request(url=url, callback=self.parse, meta={'page': page}, dont_filter=True)
def parse(self, response):
from scrapy.shell import inspect_response
inspect_response(response, self)
在终端运行
scrapy crawl example
然后再输入
response.xpath('//div[@id="mainsrp-itemlist"]//div[@class="items"][1]//div[contains(@class, "item")]').get()
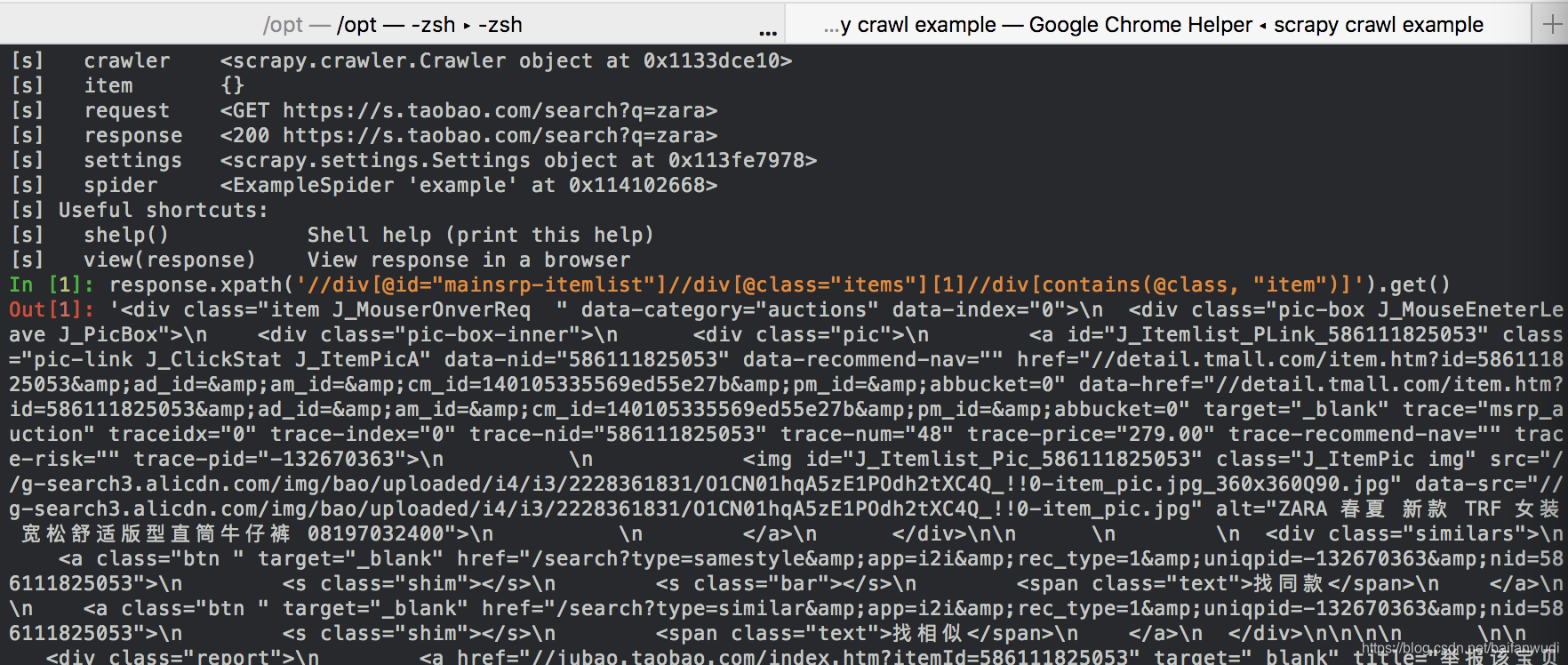
这样就可以类似于
scrapy shell https://s.taobao.com/search?q=zara解析,
如果直接敲scrapy shell这个命令,是无法解析js的。
必须按上面方法测试xpath对不对。
编辑items.py文件
import scrapy
from scrapy import Field
class TaobaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
price = Field()
title = Field()
shop = Field()
id = Field()
link = Field()
再次修改example.py文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from urllib.parse import quote
from taobao.items import TaobaoItem
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['www.taobao.com']
# start_urls = ['http://www.taobao.com/']
base_url = 'https://s.taobao.com/search?q='
def start_requests(self):
for keyword in self.settings.get("KEYWORDS"):
for page in range(1, self.settings.get("MAX_PAGE") + 1):
url = self.base_url + quote(keyword)
yield Request(url=url, callback=self.parse, meta={'page': page}, dont_filter=True)
def parse(self, response):
# from scrapy.shell import inspect_response
# inspect_response(response, self)
products = response.xpath(
'//div[@id="mainsrp-itemlist"]//div[@class="items"][1]//div[contains(@class, "item")]')
for product in products:
item = TaobaoItem()
item['price'] = ''.join(product.xpath('.//div[contains(@class, "price")]//strong//text()').getall()).strip()
item['title'] = ''.join(product.xpath('.//div[contains(@class, "title")]//text()').getall()).strip()
item['shop'] = ''.join(product.xpath('.//div[contains(@class, "shop")]//text()').getall()).strip()
item['link'] = product.xpath('.//div[contains(@class, "title")]//@href').get()
item['id'] = product.xpath('.//div[contains(@class, "title")]//@id').get()
yield item
终端运行命令
scrapy crawl example -o content.json
结果如下
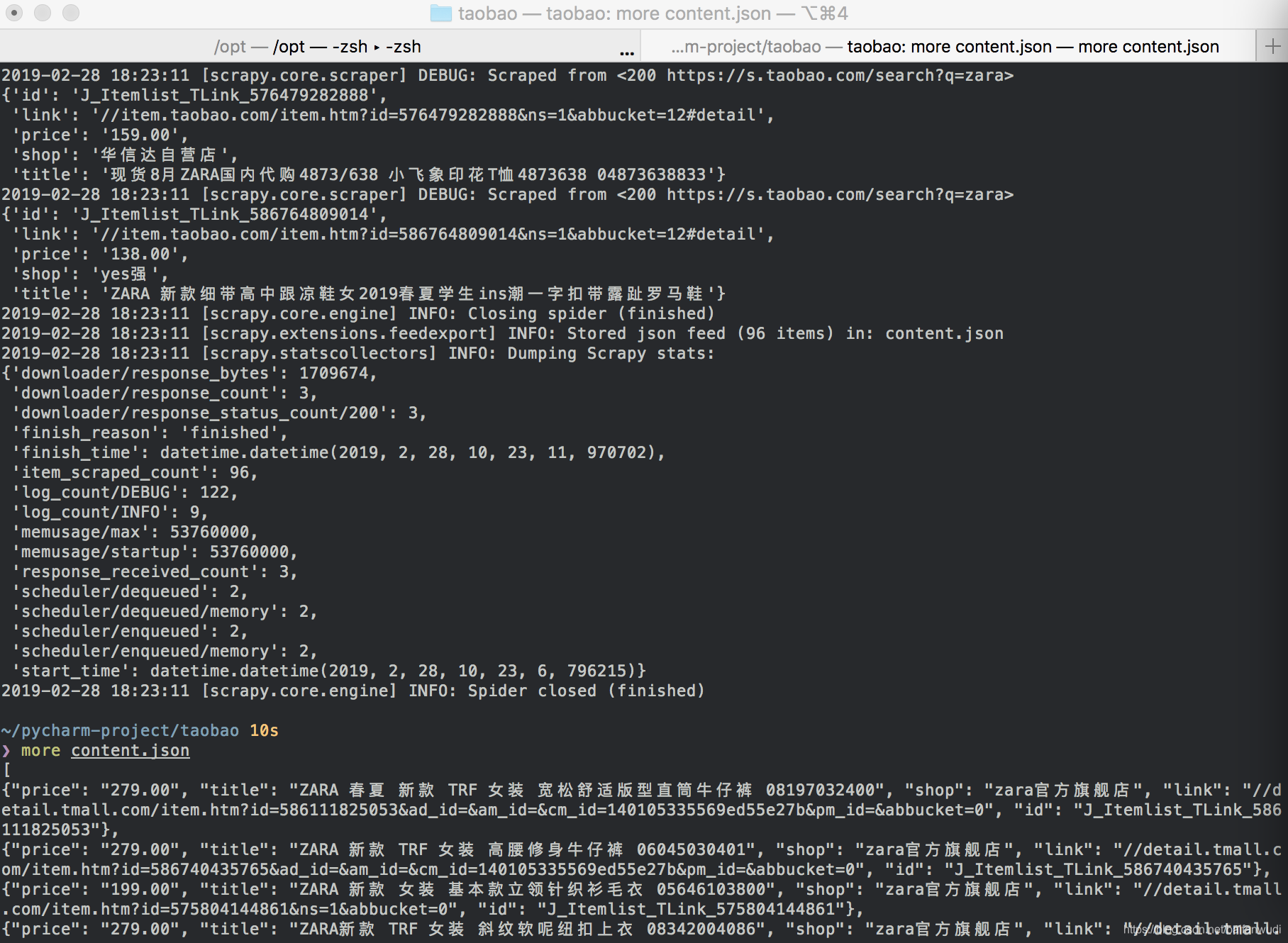
如果想保存到数据到DB,可以修改pipeline.py这里不做详述。
参考文档:
https://www.jianshu.com/p/3bada860f60c
https://blog.youkuaiyun.com/zhusongziye/article/details/80342781
https://www.jianshu.com/p/d64b13a2322b

















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









