




 本文介绍了如何在Hadoop 3.2.1和Hive 3.1.3环境中,通过Hive SQL操作对数据进行字段切割并计算各类别的占比。作者详细展示了如何使用explode函数、计数和比例计算,最后给出了完整的代码示例。
本文介绍了如何在Hadoop 3.2.1和Hive 3.1.3环境中,通过Hive SQL操作对数据进行字段切割并计算各类别的占比。作者详细展示了如何使用explode函数、计数和比例计算,最后给出了完整的代码示例。
数据:A,B,C,D,E
将数据按照 ‘,’ 分割,求每个类型的占比
测试环境:Hadoop 3.2.1,Hive 3.1.3
一、数据准备
- 创建一张表,并添加数据
# 创建表
create table if not exists test(field1 varchar(100));
# 插入数据
insert into table test values('Action,Adventure,Fantasy,Science Fiction'),('Adventure,Fantasy,Action'),('Action,Adventure,Crime');
| test.field1 |
|---|
| Action,Adventure,Fantasy,Science Fiction |
| Adventure,Fantasy,Action |
| Action,Adventure,Crime |
二、切割成一列
select explode(split(field1, ',')) as f1 from test;
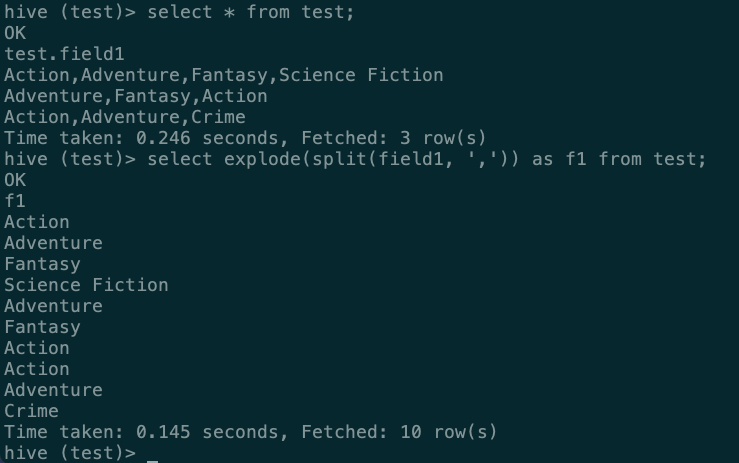
- 从结果来看,已经切出来了,下面做占比统计
三、占比统计
1. 添加常数列
- 这里我用的方法是添加一列常数列,然后做 sum 统计每个类型出现的次数
with temp as (
select explode(split(field1, ',')) as f1 from test
)
select f1, 1 as num from temp;
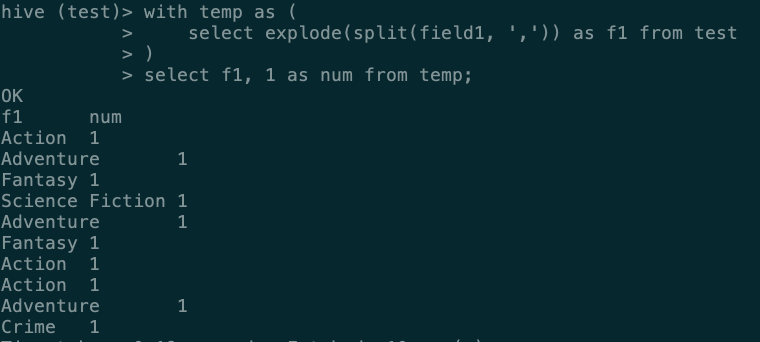
2. 统计出现次数
- 用 sum 来统计出现的次数,然后使用一个子查询获取总条数,给后面统计占比用
with temp as (
select explode(split(field1, ',')) as f1 from test
)
select f1, sum(num) as total, (select count(*) from temp) as cnt
from (
select f1, 1 as num from temp
) t1
group by f1;
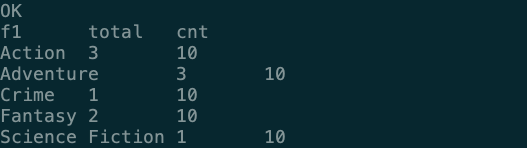
3. 统计占比
- 直接相除得到结果
with temp as (
select explode(split(field1, ',')) as f1 from test
)
select f1, round((total/cnt) * 100, 2) as per
from (
select f1, sum(num) as total, (select count(*) from temp) as cnt
from (
select f1, 1 as num from temp
) t1
group by f1
) t2;

四、最终代码
- 加个 ’ % ’
with temp as (
select explode(split(field1, ',')) as f1 from test
)
select f1, concat(round((total/cnt) * 100, 2), '%') as per
from (
select f1, sum(num) as total, (select count(*) from temp) as cnt
from (
select f1, 1 as num from temp
) t1
group by f1
) t2;

- 结果就是这样,目前想到的方法就是这样,有更好的方法可以一起交流交流

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









