




目录
CTC
聊到CTC(Connectionist Temporal Classification),很多人的第一反应是ctc擅长单行验证码识别:

ctc可以提高单行文本识别鲁棒性(不同长度不同位置 )。今天David 9分享的这篇文章用几个重点直观的见解把ctc讲的简洁易懂,所以在这里就和大家一起补一补ctc 。
ctc算不上一个框架,更像是连接在神经网络后的一个归纳字符连接性的操作:
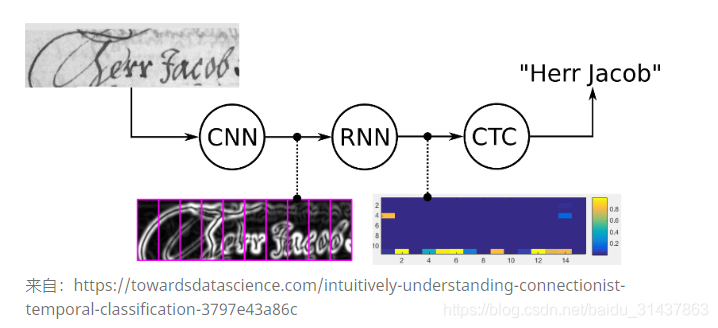
cnn提取图像像素特征,rnn提取图像时序特征,而ctc归纳字符间的连接特性。
CTC的好处:
因手写字符的随机性,人工可以标注字符出现的像素范围,但是太过麻烦,ctc可以告诉我们哪些像素范围对应的字符:

如上图标注“t”的位置出现t字符,标注o的区域出现o字符。是的就是这样简单,ctc会总结出上述标注规律,不用人工标注,你所要做的只是提供loss函数做模型训练。
CTC是如何工作的?
ctc的编码有一个地方需要注意即是对重复字符的处理,如上述例子中的“to”, 如果真实字符串是“too”,而编码时也为“to”,就会和真实字符串“to”混淆。
所以在重复字符处要引入一个占位符号“-” 。下面是一些例子:

然后,ctc会计算loss ,从而找到最可能的像素区域对应的字符。事实上,这里loss的计算本质是对概率的归纳:
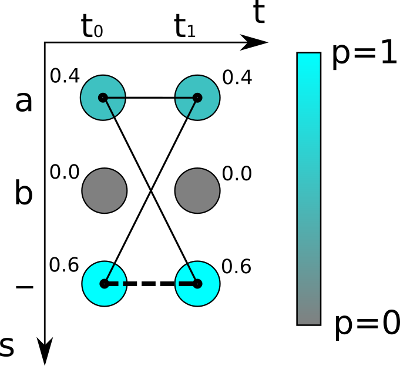
如上图,对于最简单的时序为2的(t0t1)的字符识别,可能的字符为“a”,“b”和“-”,颜色越深代表概率越高。对于真实字符为空即“”的概率为0.6*0.6=0.36
而真实字符为“a”的概率不只是”aa” 即0.4*0.4 , 实时上,“aa”, “a-“和“-a”都是代表“a”,所以,“a”的概率为:
0.4*0.4 + 0.4 * 0.6 + 0.6*0.4 = 0.16+0.24+0.24 = 0.64
所以“a”的概率比空“”的概率高!通过对概率的计算,就可以对之前的神经网络进行方向传播更新。
最后,ctc的解码也是根据概率获得最高的那条路径:
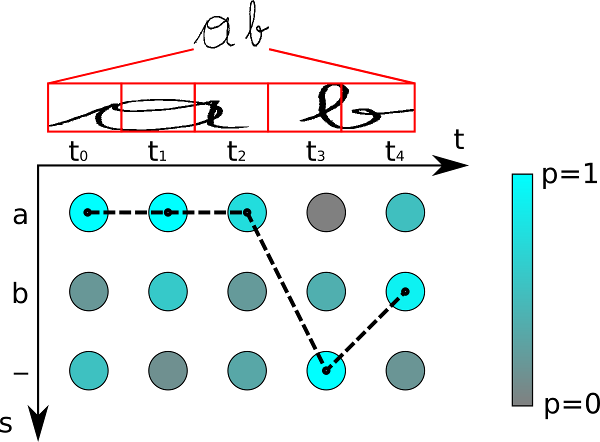
传统的语音识别是要知道每一帧的数据是对应哪个发音因素,比如下图中的,知道哪几帧对应哪个标签后,才能有效的训练,在训练数据之前需要对语音做语音对齐预处理。
采用CTC作为损失函数的声学模型训练,是一种完全端到全的声学模型训练,不需要预先对其数据,只需要输入序列和一个输出序列即可训练。这样不需要对数据对齐--标注,并i企鹅CTC直接输出序列预测的概率。
既然CTC的方法是关心一个输入序列到一个输出序列的结果,那么它只会关心预测输出的序列是否和真实的序列是否接近(相同),而不会关心预测输出序列中每个结果在时间点上是否和输入的序列正好对齐。

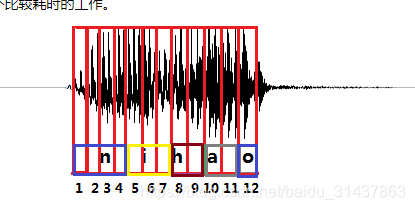
CTC引入了blank(该帧没有预测值),每个预测的分类对应的一整段语音中的一个spike(尖峰),其他不是尖峰的位置认为是blank。对于一段语音,CTC最后的输出是spike(尖峰)的序列,并不关心每一个音素持续了多长时间。
如图2所示,拿前面的nihao的发音为例,进过CTC预测的序列结果在时间上可能会稍微延迟于真实发音对应的时间点,其他时间点都会被标记会blank。
RNN+CTC
OCR识别也可以采用RNN+CTC的模型来做,将包含文字的图片每一列的数据作为一个序列输入给。RNN+CTC模型,输出是对应的汉字,因为要好多列才组成一个汉字,所以输入的序列的长度远大于输出序列的长度。而且这种实现方式的OCR识别,也不需要事先准确的检测到文字的位置,只要这个序列中包含这些文字就好了。
CTC是一种损失函数,它用来衡量输入的序列数据经过神经网络之后,和真实的输出相差有多少。
比如输入一个200帧的音频数据,真实的输出是长度为5的结果。 经过神经网络处理之后,出来的还是序列长度是200的数据。比如有两个人都说了一句nihao这句话,他们的真实输出结果都是nihao这5个有序的音素,但是因为每个人的发音特点不一样,比如,有的人说的快有的人说的慢,原始的音频数据在经过神经网络计算之后,第一个人得到的结果可能是:nnnniiiiii...hhhhhaaaaaooo(长度是200),第二个人说的话得到的结果可能是:niiiiii...hhhhhaaaaaooo(长度是200)。这两种结果都是属于正确的计算结果,可以想象,长度为200的数据,最后可以对应上nihao这个发音顺序的结果是非常多的。CTC就是用在这种序列有多种可能性的情况下,计算和最后真实序列值的损失值的方法。
详细描述如下:
训练集合为S={(x1,z1),(x2,z2),...(xN,zN)}S={(x1,z1),(x2,z2),...(xN,zN)}, 表示有NN个训练样本,xx是输入样本,zz是对应的真实输出的label。一个样本的输入是一个序列,输出的label也是一个序列,输入的序列长度大于输出的序列长度。
对于其中一个样本(x,z)(x,z),x=(x1,x2,x3,...,xT)x=(x1,x2,x3,...,xT)表示一个长度为T帧的数据,每一帧的数据是一个维度为m的向量,即每个xi∈Rmxi∈Rm。 xixi可以理解为对于一段语音,每25ms作为一帧,其中第ii帧的数据经过MFCC计算后得到的结果。
z=(z1,z2,z3,...zU)z=(z1,z2,z3,...zU)表示这段样本语音对应的正确的音素。比如,一段发音“你好”的声音,经过MFCC计算后,得到特征xx, 它的文本信息是“你好”,对应的音素信息是z=[n,i,h,a,o]z=[n,i,h,a,o](这里暂且将每个拼音的字母当做一个音素)。
ytk(k=1,2,3,...n,t=1,2,3,...,T)ykt(k=1,2,3,...n,t=1,2,3,...,T)表示在tt时刻,发音为音素kk的概率,其中音素的种类个数一共nn个, kk表示第kk个音素,在一帧的数据上所有的音素概率加起来为1。即:
![]()
这个过程可以看做是对输入的特征数据xx做了变换NwNw:(Rm)T→(Rn)T(Rm)T→(Rn)T,其中NwNw表示RNN的变换,ww表示RNN中的参数集合。
过程入下图所示:

以一段“你好”的语音为例,经过MFCC特征提取后产生了30帧,每帧含有12个特征,即x∈R30×14x∈R30×14(这里以14个音素为例,实际上音素有200个左右),矩阵里的每一列之和为1。后面的基于CTC-loss的训练就是基于后验概率yy计算得到的。
参考:
https://xiaodu.io/ctc-explained/


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











