




一、引言
四天前我发了一篇关于“从百度搜索结果抓取标题、链接、内容,并保存到xlsx文件中”的网络爬虫学习日志,算是在网络爬虫这个技术分支上走出了第一步。
我同事提出的爬虫软件需求包含了几个主要的新闻网站,只解决了爬取百度搜索的结果还不够,我还需再接再厉。这两天我将目光转向了新浪,琢磨其怎么从新浪新闻搜索中抓取搜到的结果的相关数据。新浪新闻搜索的实现技术与百度又有些不同,刚开始我还只能抓取第一页的内容,不过有了之前的知识积累,再加上不断的从网上搜索相关的资料,总算解决了问题,实现了将新浪新闻搜索到的所有新闻的标题、链接、内容、来源、时间都抓取下来的目标。经过多次测试,感觉抓取效果比之前从百度抓取要好,不光能把所有结果都抓取下来,还能通过设置参数实现对不同时间范围内的新闻进行搜索,这正是我同事需要的功能。
二、功能实现
(一)用到的库
本日志代码用到了两个库:requests、BeautifulSoup。用于发送请求获取数据和对数据进行分析,至于将抓取的结果保存到xlsx文件中,之前的日志中已经有相关的代码了,这里就不再重复了。
(二)网页数据分析
打开新浪新闻中心首页,在首页右上角的搜索框输入关键字,点搜索后跳转到了新浪网的新闻搜索页面。
刚开始使用网页浏览器的“开发者工具”对页面进行分析,比较顺利的找出了标题、链接、内容、来源、发布时间所在的节点信息。
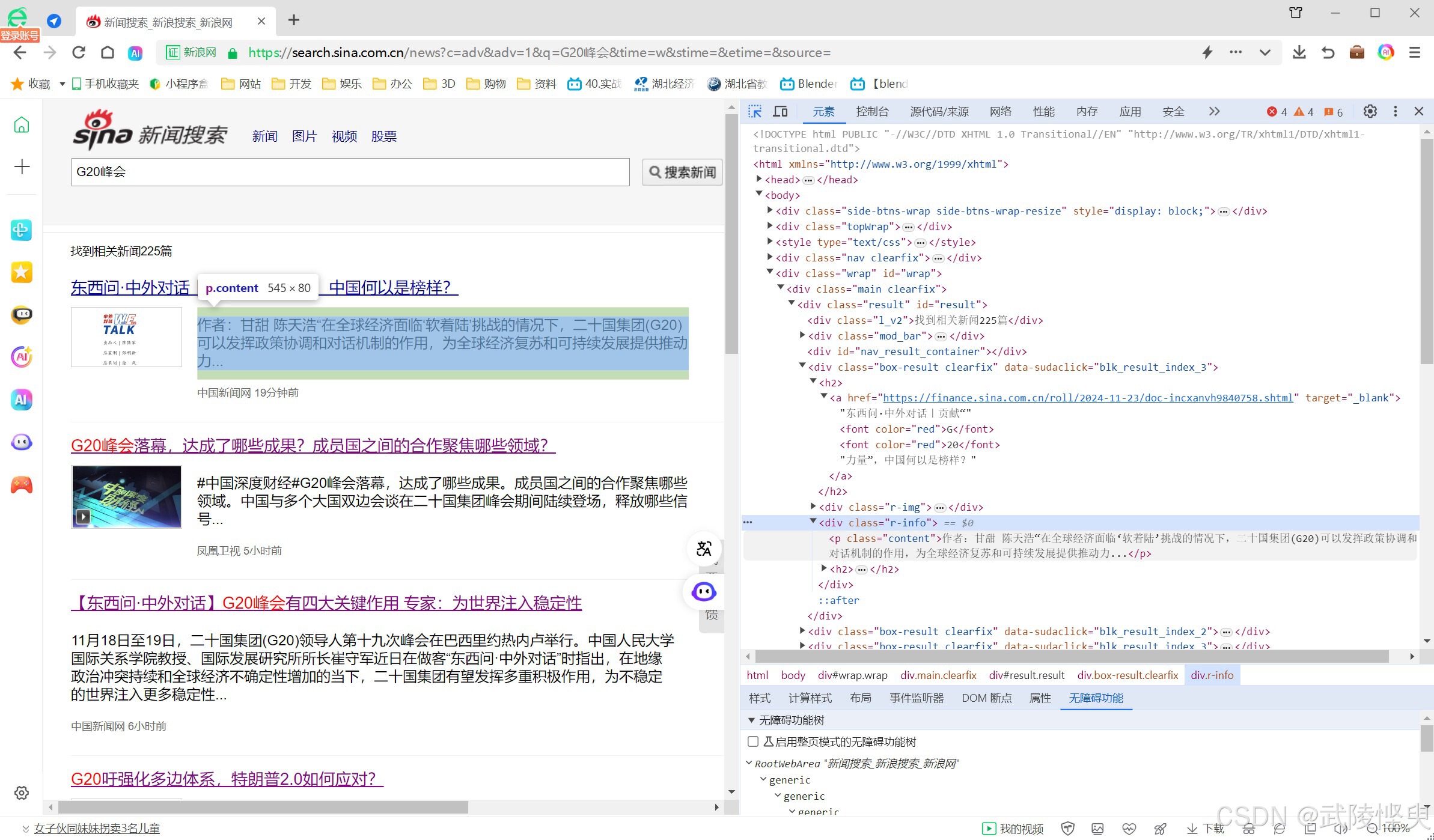
(找标题、链接、内容等信息比较容易)
但,点第2页、第3页...浏览器的网址栏显示的网址始终是“https:// search.sina.com.cn/news” ,这与百度的情况不一样(百度的网址会发生变化,可以通过观察网址发现规律)。接着我又对页面下方的其它页的跳转按钮进行了分析,一看是有规律的,但我尝试了将其中的几个参数添加到浏览器的网址栏中点更新,没有获得期待的效果。这就意味着,我没有找到网址的编写规律。
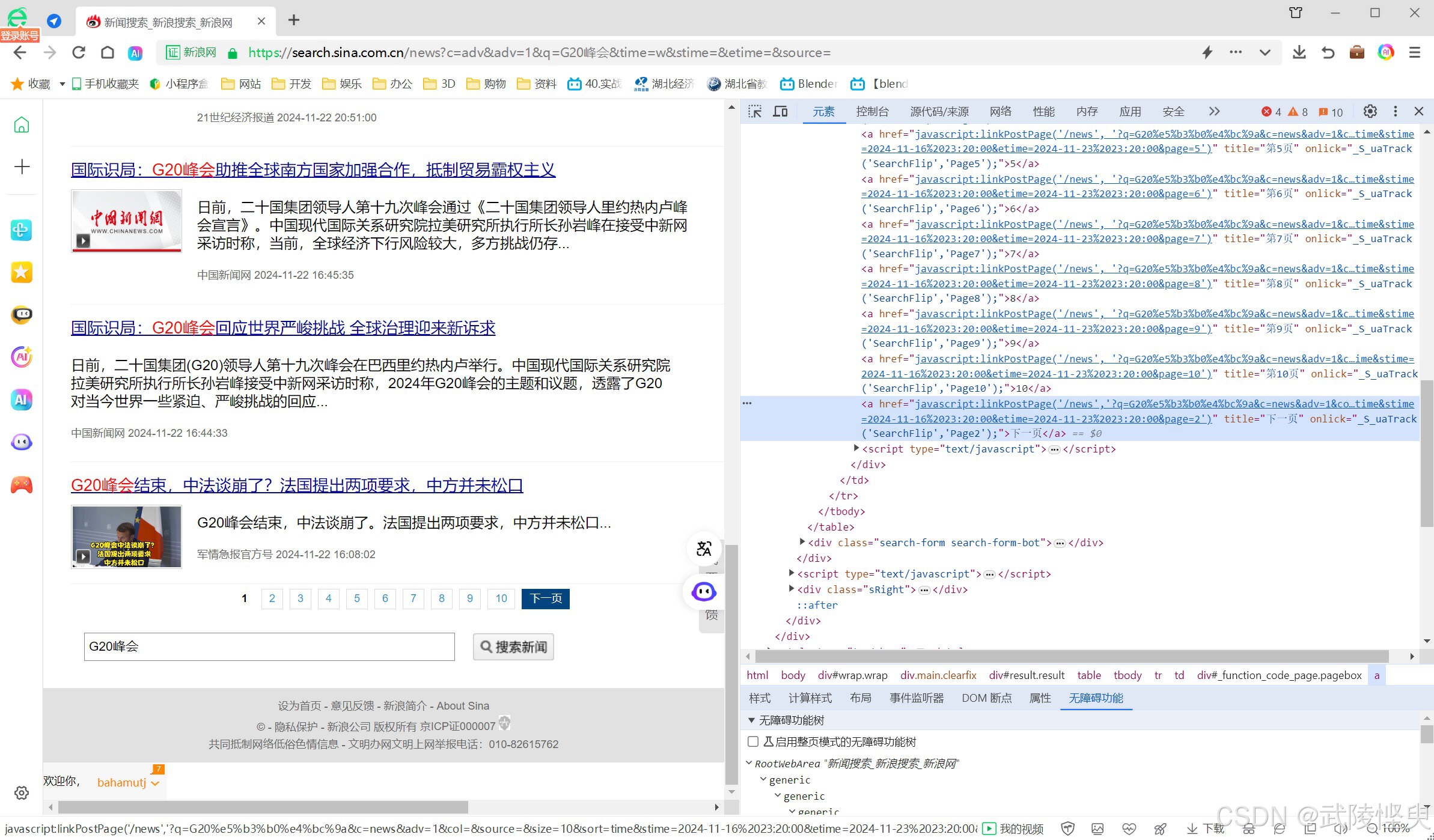
(试图从页面下方的各页跳转链接中找规律,不过水平有限,没成功)
自己研究不出来,就只能上网找了。我在网上搜索了一通,虽然找到了一些资料,但要么不能解决我遇到的问题,要么就是几年前的资料,看了一两遍,一时没看懂。这让我只能实现对第一页的内容进行抓取,与目标有很大出入。我只能暂时搁置,去研究其它网站的数据爬取。
过了一天,我又转回来研究新浪网的新闻搜索抓取。这次,我注意到了“搜索新闻”按钮右边有个“高级搜索”按钮,点击进去后发现多了时间范围和媒体两个参数。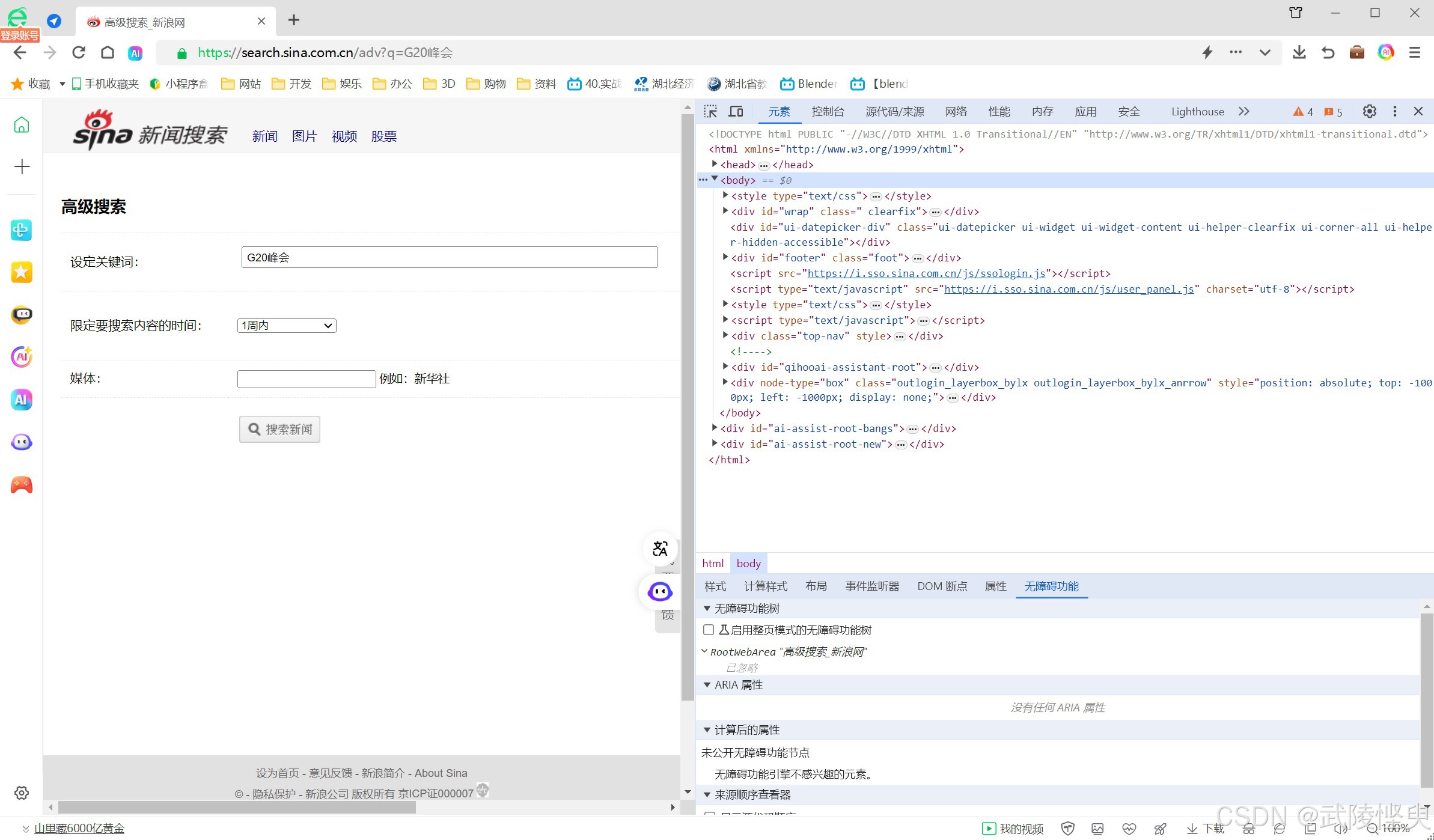
我尝试改了一下时间范围,将设置从“不限”改成了“1周内”,点“搜索新闻”按钮。这个时候结果发生了变化,同时网址栏中显示的网址也发生了变化。与之前的网址相比多了以下的内容:
“?c=adv&adv=1&q=G20峰会&time=w&stime=&etime=&source=”
看到这些字符串,我感觉有戏了。
我先是通过“高级搜索”摸索进行不同参数的设置找出了time参数和source参数的规律,之后又尝试修改上面的参数,发现adv参数就是“高级搜索”模式的开关。这个时候再回过头看页面下方的各页跳转链接,明白了stime和etime的功能,另外这个时候添加page参数,终于可以获取到其它页面的内容了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 156
156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











