




 本文档记录了使用ELK(Elasticsearch, Logstash, Kibana)堆栈配合filebeat收集Java应用日志的全过程。在三台服务器上部署Elasticsearch集群,一台服务器上安装Logstash、Kibana和Head插件,两台生产环境服务器安装filebeat。详细步骤包括设置hosts、安装JDK、Elasticsearch集群配置、Logstash与Kibana安装、filebeat配置以及采集结果的验证。"
115109933,10768685,排序数组中的查找:顺序法与二分法,"['算法', '二分法']
本文档记录了使用ELK(Elasticsearch, Logstash, Kibana)堆栈配合filebeat收集Java应用日志的全过程。在三台服务器上部署Elasticsearch集群,一台服务器上安装Logstash、Kibana和Head插件,两台生产环境服务器安装filebeat。详细步骤包括设置hosts、安装JDK、Elasticsearch集群配置、Logstash与Kibana安装、filebeat配置以及采集结果的验证。"
115109933,10768685,排序数组中的查找:顺序法与二分法,"['算法', '二分法']
前言
此文章是我在生产环境下搭建ELK日志系统的记录,该日志系统主要是采集Java日志,开发人员能通过kibanaWeb页面查找相关主机的指定日志;对于Java日志,filebeat已做多行合并、过滤行处理,更精准的获取需要的日志信息,关于ELK系统的介绍,这里不再赘述。
更多信息可以访问官方网站查询:
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
Logstash:
https://www.elastic.co/cn/products/logstash
Kibana:
https://www.elastic.co/cn/products/kibana
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
环境
| 主机服务类型 | 主机名 | 内存 | 服务 |
|---|---|---|---|
| es1 | test-machine | 32G | elasticsearch、logstash、kibana |
| es2 | 926prod | 8G | elasticsearch |
| es3 | replmysql | 4G | elasticsearch |
| web1 | template-centos7 | 16G | filebeat |
| web2 | template-centos7 | 16G | filebeat |
ELK使用的版本均为6.4.3,在下面的搭建中提供了下载地址。三台elasticsearch搭建集群处理,可靠传输。logstash、kibana搭建在同一台服务器中,资源足够不影响服务。两台web服务器为生产环境下的主机,安装filebeat软件来采集日志数据,传输至logstash服务器。
步骤
1、设置hosts
[root@test-machine /root]#cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.146 testmachine
192.168.1.60 926prod
192.168.1.62 replmysql
[root@test-machine /root]#scp /etc/hosts 926prod:/etc/hosts
[root@test-machine /root]#scp /etc/hosts replmysql:/etc/hosts
2、安装javaJDK
jdk版本需要时1.8及以上
[root@test-machine /root]#yum -y install java
[root@test-machine /root]#java -version
openjdk version "1.8.0_191"
[root@926prod /root]#yum -y install java
[root@926prod /root]#java -version
openjdk version "1.8.0_191"
[root@replmysql /root]#yum -y install java
[root@replmysql /root]#java -version
openjdk version "1.8.0_191"
3、安装elasticsearch(三台机器相同操作)
下载——安装——启动服务
[root@test-machine ~]#curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.3.tar.gz
[root@test-machine ~]#tar -xvf elasticsearch-6.4.3.tar.gz
[root@test-machine ~]#mv elasticsearch-6.4.3 /usr/local/
[root@test-machine ~]#useradd elasticsearch
[root@test-machine ~]#cd /usr/local/elasticsearch-6.4.3/
[root@test-machine bin]#chown -R elasticsearch:elasticsearch /usr/local/elasticsearch-6.4.3/
修改配置文件:
[root@test-machine /root]#grep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: sunaw-cluster
node.name: test-machine
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.1.146
discovery.zen.ping.unicast.hosts: ["testmachine", "replmysql", "926prod"]
http.enabled: true
http.cors.enabled: true
http.cors.allow-origin: "*"
# 注意node.name、network.host字段,三台机填入各自的名字和ip地址
启动服务:
[root@test-machine bin]#su elasticsearch
[elasticsearch@test-machine bin]$nohup ./elasticsearch &
[elasticsearch@test-machine bin]$exit
[root@test-machine ~]#ss -ntulp | grep -E "9200|9300"
tcp LISTEN 0 128 127.0.0.1:9200 *:* users:(("java",pid=27279,fd=190))
tcp LISTEN 0 128 127.0.0.1:9300 *:* users:(("java",pid=27279,fd=183))
※在启动elasticsearch过程中可能会遇到一下问题:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决:
[root@test-machine /root]#sysctl -w vm.max_map_count=262144
[root@test-machine /root]#vim /etc/sysctl.conf
vm.max_map_count=262144
启动后可以在浏览器中查看服务状态和集群状态:
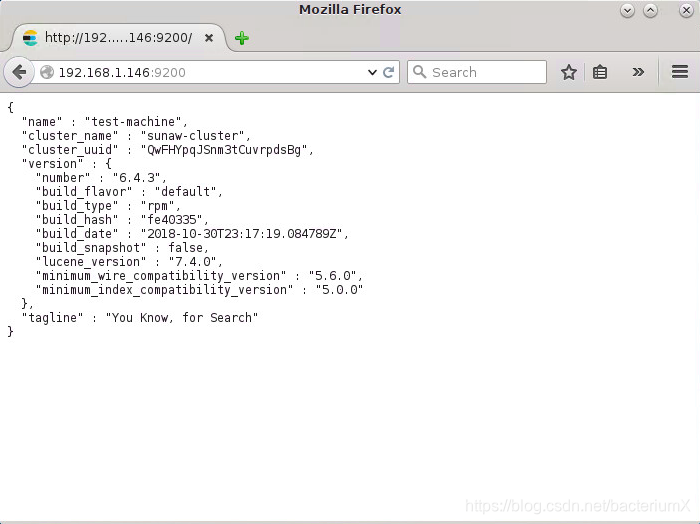
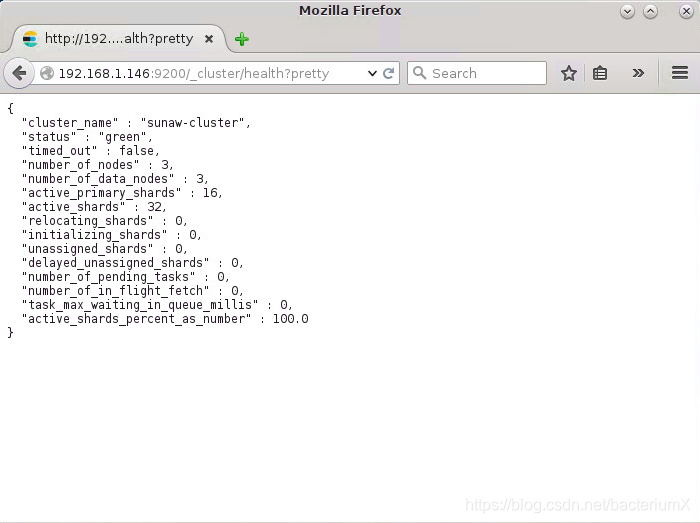
http://localhost:9200
http://localhost:9200/_cluster/health?pretty,观察status为‘green’和number of nodes为‘3’,说明三个elasticsearch已经组成集群。
4、安装head插件
head插件安装,只需要在一台机器安装就可以,ES5.0以上不支持plugin安装,所以这里笔者启动一个服务来安装head插件。
安装node.js环境:
[root@test-machine /root]#wget https://nodejs.org/dist/v10.13.0/node-v10.13.0-linux-x64.tar.xz
[root@test-machine /root]#tar -xf node-v10.13.0-linux-x64.tar.xz -C /usr/local/
[root@test-machine /root]#vim /etc/profile
……
export NODEJS_HOME=/usr/local/node-v10.13.0-linux-x64
export PATH=$PATH:$NODEJS_HOME/bin
[root@test-machine /root]#source /etc/profile
[root@test-machine /root]#npm -v
6.4.1
安装head插件:
[root@test-machine /root]#git clone https://github.com/mobz/elasticsearch-head
[root@test-machine /root]#cd elasticsearch-head/
[root@test-machine /root]#chown -R elasticsearch:elasticsearch /root/elasticsearch-head/
[root@test-machine /root]#npm install -g grunt-cli
[root@test-machine /root]#npm install
[root@test-machine /root]#npm install phantomjs-prebuilt@2.1.16 --ignore-scripts
[root@test-machine /root]#nohup grunt server &
[root@test-machine /root]#ss -ntulp | grep 9100
tcp LISTEN 0 128 *:9100 *:* users:(("grunt",pid=26754,fd=18))
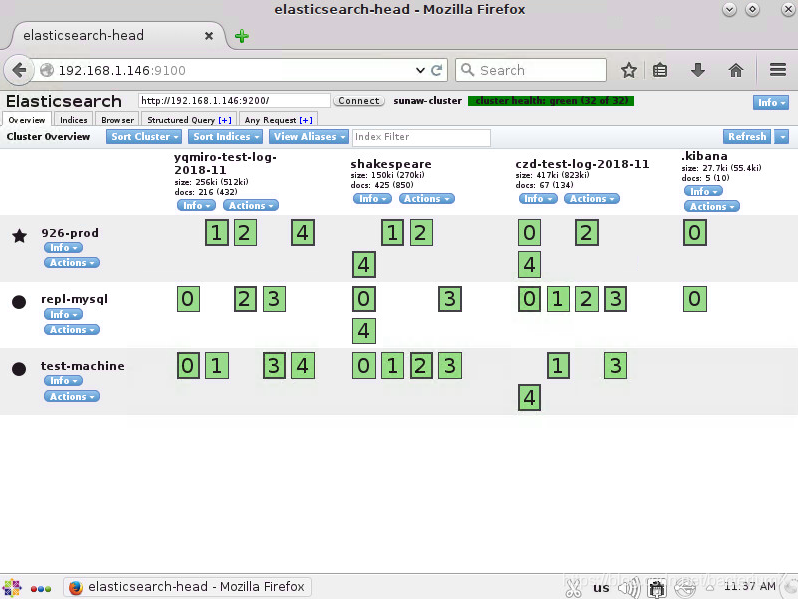
head插件监听在9100端口,浏览器访问http://localhost:9100可以看到连接到elasticsearch集群的副本状态
5、安装logstash
logstash安装,一台机器上安装即可:
[root@test-machine /root]#wget https://artifacts.elastic.co/downloads/logstash/logstash-6.4.3.rpm
[root@test-machine /root]#yum -y install logstash-6.4.3.rpm
编辑配置文件,测试能否将信息传入elasticsearch
[root@test-machine /root]#vim /etc/logstash/logstash.conf
input{
stdin{}
}
output{
elasticsearch{
hosts => ["192.168.1.146:9200","192.168.1.60:9200","192.168.1.62:9200"]
}
stdout { codec => rubydebug }
}
指定配置文件启动logstash服务,启动服务后直接在终端键入测试信息,然后回车:
[root@test-machine /root]#/usr/share/logstash/bin/logstash --config.test_and_exit -f /etc/logstash/logstash.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties
[2018-11-21T11:57:23,564][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
Configuration OK
[2018-11-21T11:57:27,561][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
[root@test-machine /root]#/usr/share/logstash/bin/logstash -f /etc/logstash/logstash.conf
……
[2018-11-21T11:50:11,976][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2018-11-21T11:50:12,268][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
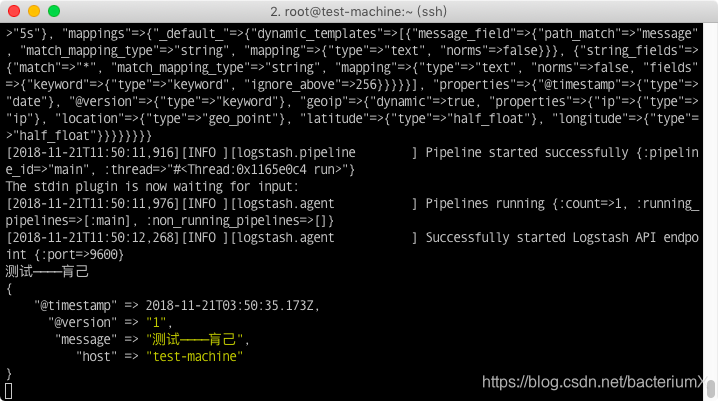
测试————肓己
可以在终端中看到输出的信息:
head插件中可以看到信息:
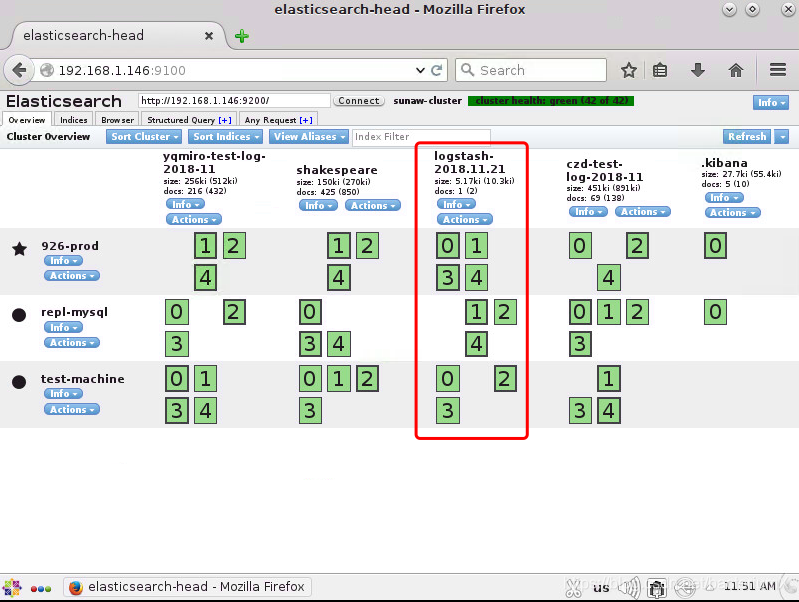
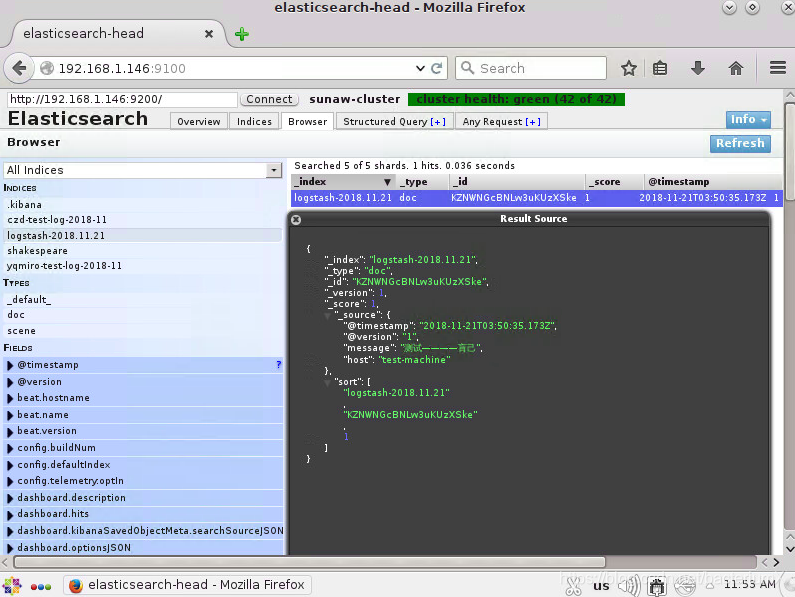
6、安装kibana
kibana 安装,一台机器安装即可:
[root@test-machine /root]#wget https://artifacts.elastic.co/downloads/kibana/kibana-6.4.3-x86_64.rpm
[root@test-machine /root]#yum -y install kibana-6.4.3-x86_64.rpm
修改配置文件
[root@test-machine /root]#vim /etc/kibana/kibana.yml
[root@test-machine /root]#grep -v "^#" /etc/kibana/kibana.yml | grep -v "^$"
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.1.146:9200"
kibana.index: ".kibana"
kibana.defaultAppId: "discover"
elasticsearch.pingTimeout: 1500
elasticsearch.requestTimeout: 30000
elasticsearch.startupTimeout: 5000
启动服务:
[root@test-machine /root]#systemctl start kibana
[root@test-machine /root]#systemctl status kibana
● kibana.service - Kibana
Loaded: loaded (/etc/systemd/system/kibana.service; disabled; vendor preset: disabled)
Active: active (running) since Thu 2018-11-15 16:19:40 CST; 5 days ago
Main PID: 24972 (node)
CGroup: /system.slice/kibana.service
└─24972 /usr/share/kibana/bin/../node/bin/node --no-warnings /usr/share/kibana/bin/.....
启动服务后,kibana监听在5601端口,访问http://localhost:5601可以在浏览器中配置和管理
设置索引:
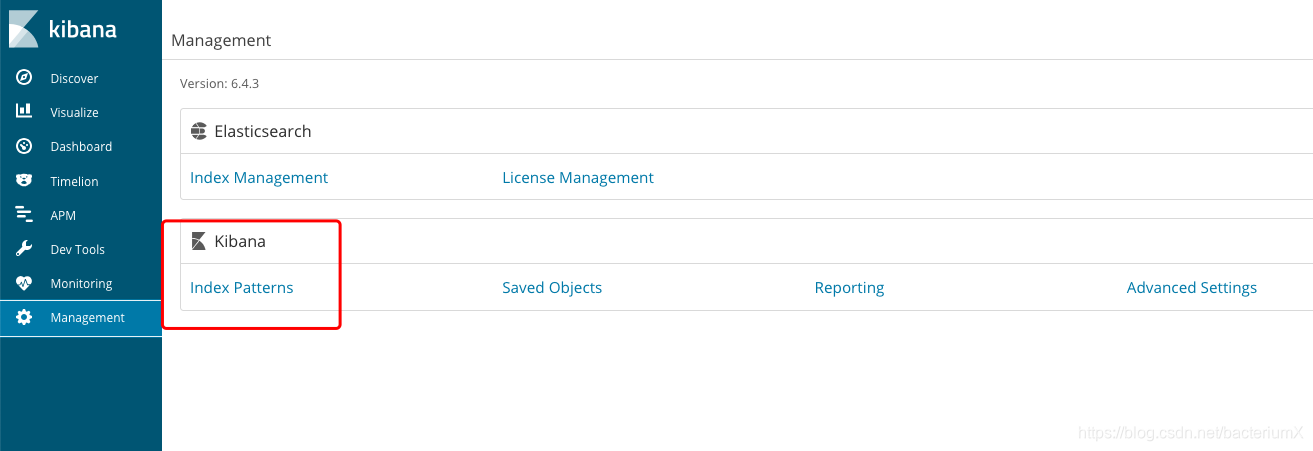
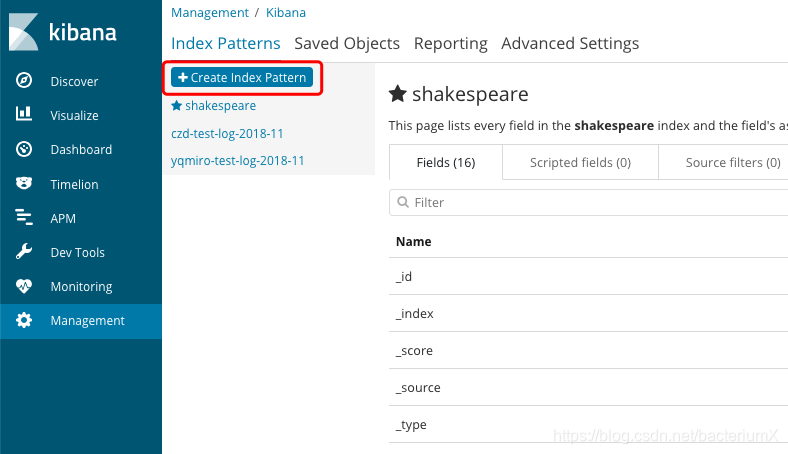
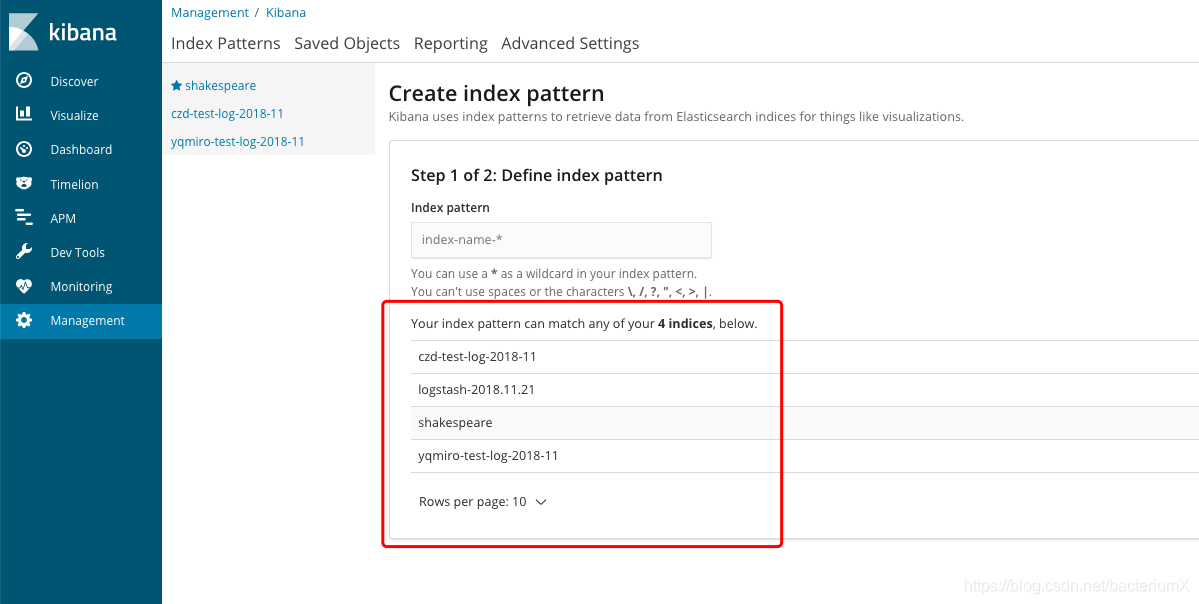
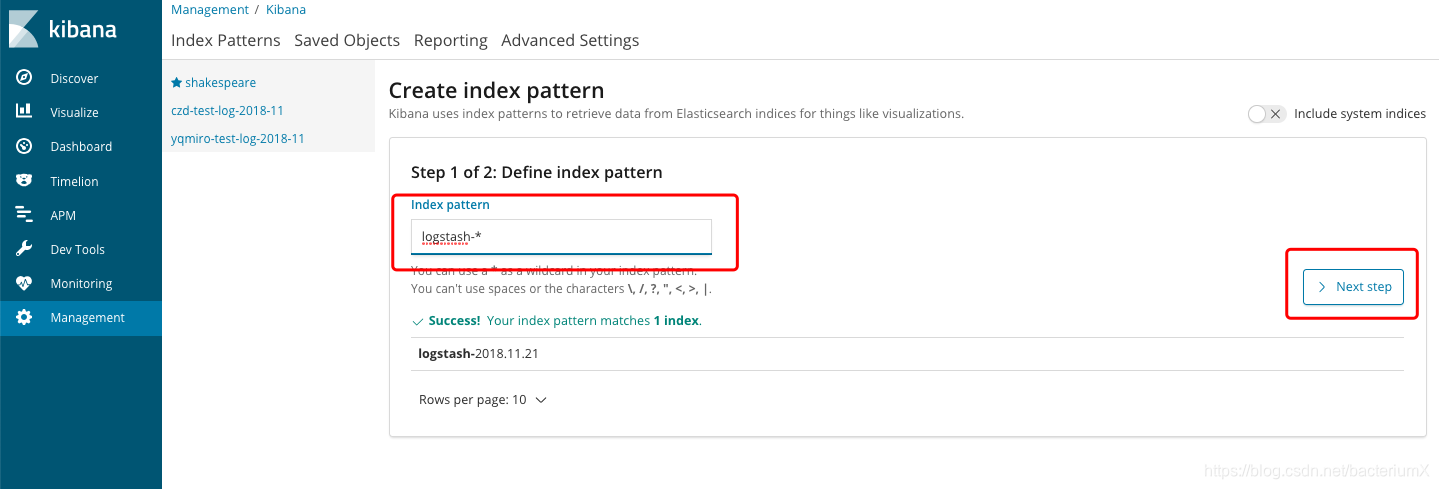
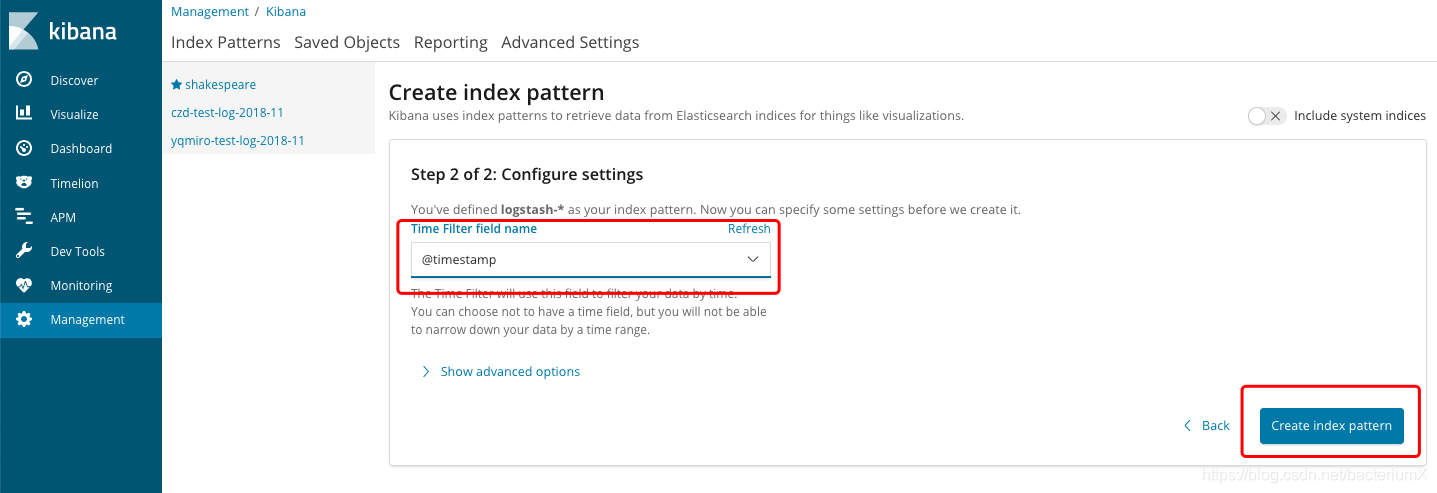
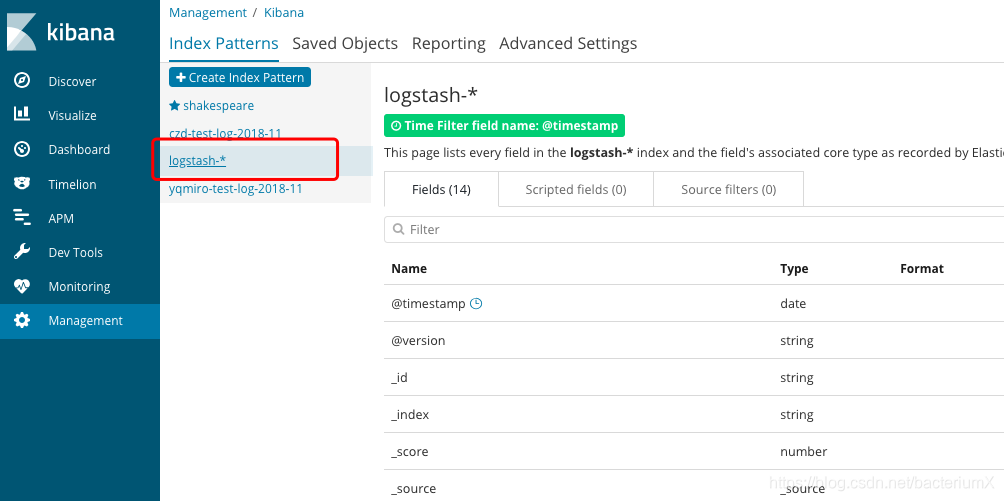
设置完索引后查看数据: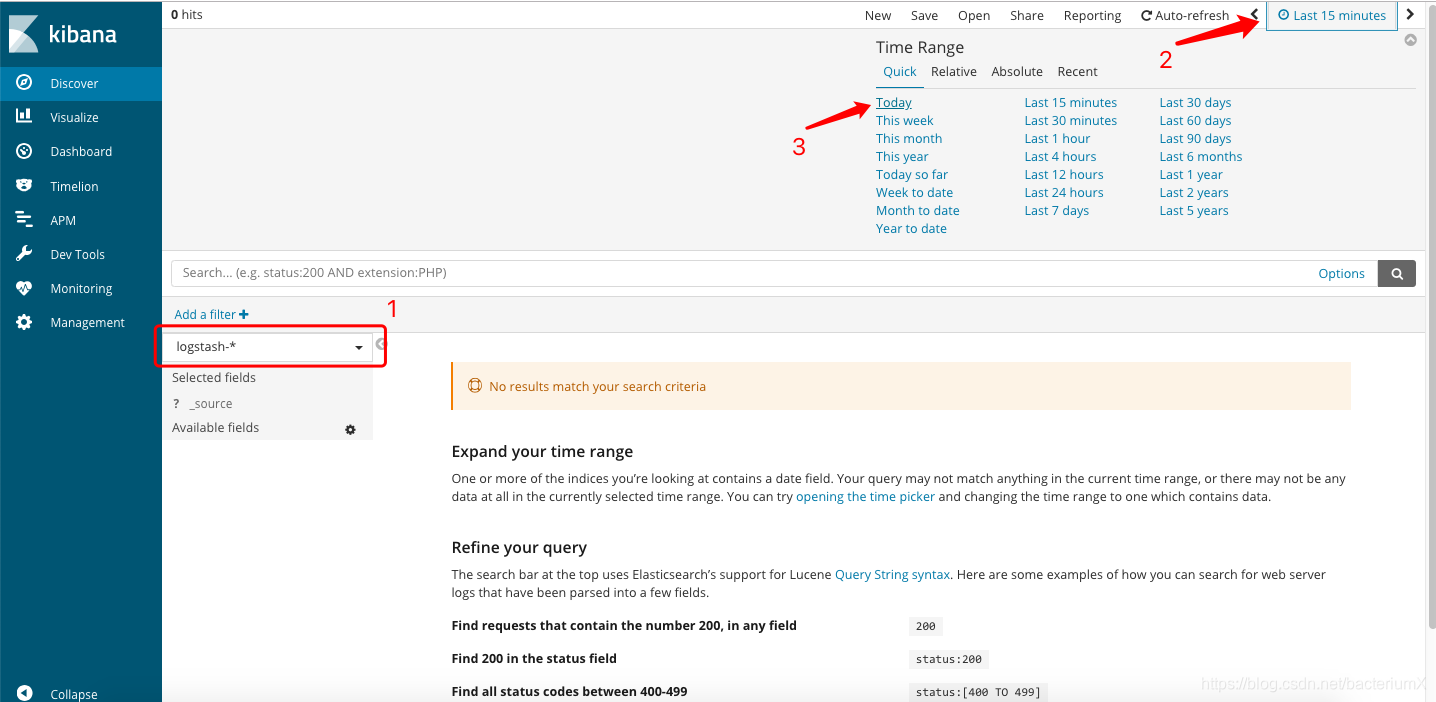
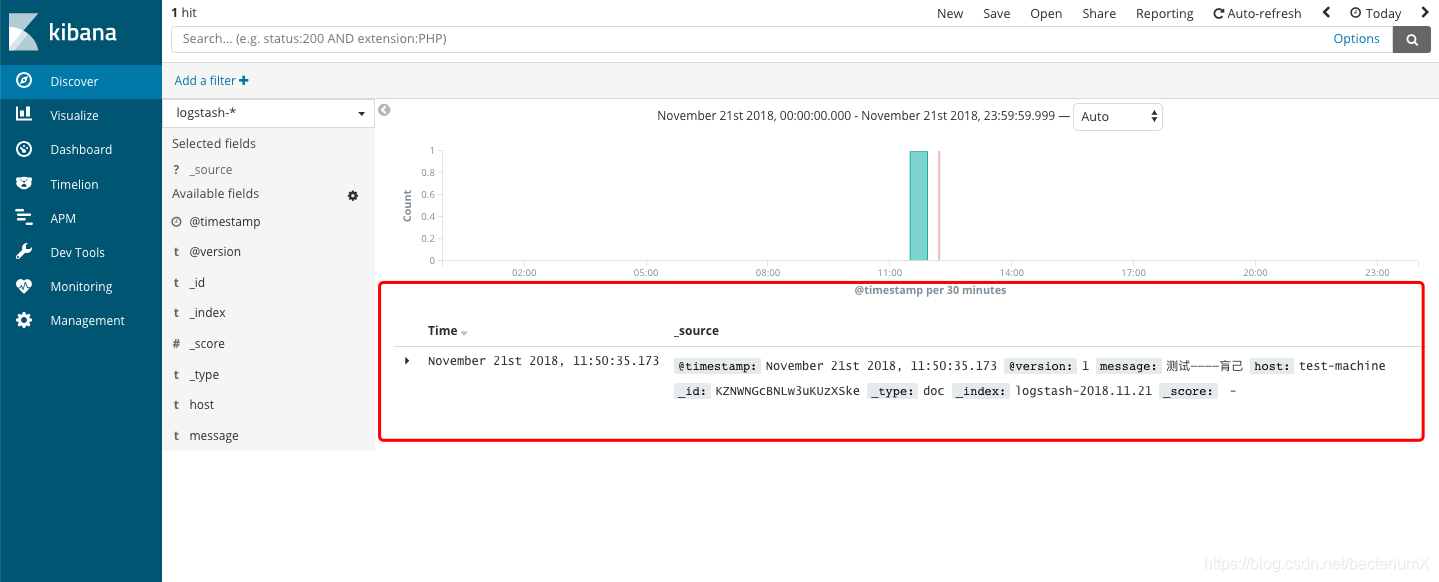
7、安装filebeat
两台web主机安装filebeat,编辑配置文件,先不要启动服务。
web主机1:
[root@template-centos7 /root]#curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.4.3-x86_64.rpm
[root@template-centos7 /root]#yum -y install filebeat-6.4.3-x86_64.rpm
[root@template-centos7 /root]#vim /etc/filebeat/filebeat.yml
[root@template-centos7 /root]#grep -v "#" /etc/filebeat/filebeat.yml |grep -v "^$"
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/logs/sunaw_czd/czd.log
document_type: czd-log
fields:
tag: czdtest
logtype: czdtest
exclude_lines: [".*c.b.mybatisplus.mapper.SqlHelper.*"]
multiline.pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})'
multiline.negate: true
multiline.match: after
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash:
hosts: ["192.168.1.146:5044"]
web主机2:
[root@926-test /root]#grep -v "#" /etc/filebeat/filebeat.yml |grep -v "^$"
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/logs/jiuerliu.log
document_type: jiuerliu-log
fields:
tag: yqmirotest
logtype: yqmirotest
exclude_lines: [".*c.b.mybatisplus.mapper.SqlHelper.*"]
multiline.pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})'
multiline.negate: true
multiline.match: after
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash:
hosts: ["192.168.1.146:5044"]
在logstash主机新建filebeat配置文件,并启动服务:
logstash配置
[root@test-machine /root]#cat /etc/logstash/filebeat.conf
input {
beats {
port => 5044
type => "logs"
#codec => "json"
}
}
output {
if [fields][logtype] == "czdtest"{
elasticsearch {
hosts => [ "192.168.1.146:9200","192.168.1.60:9200","192.168.1.62:9200"]
index => "czd-test-log-%{+YYYY-MM}"
}
}
if [fields][logtype] == "yqmirotest"{
elasticsearch {
hosts => [ "192.168.1.146:9200","192.168.1.60:9200","192.168.1.62:9200"]
index => "yqmiro-test-log-%{+YYYY-MM}"
}
}
stdout { codec => rubydebug }
}
[root@test-machine /root]#/usr/share/logstash/bin/logstash -f /etc/logstash/filebeat.conf
[2018-11-21T12:29:21,462][INFO ][org.logstash.beats.Server] Starting server on port: 5044
[2018-11-21T12:29:21,479][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2018-11-21T12:29:21,856][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
lostash启动后,再去两台web主机中启动filebeat:
[root@template-centos7 /root]#systemctl start filebeat
[root@template-centos7 /root]#systemctl status filebeat
● filebeat.service - Filebeat sends log files to Logstash or directly to Elasticsearch.
Loaded: loaded (/usr/lib/systemd/system/filebeat.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2018-11-21 12:31:15 CST; 7s ago
Docs: https://www.elastic.co/products/beats/filebeat
Main PID: 11079 (filebeat)
Memory: 7.4M
CGroup: /system.slice/filebeat.service
└─11079 /usr/share/filebeat/bin/filebeat -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -pat...
Nov 21 12:31:15 template-centos7 systemd[1]: Started Filebeat sends log files to Logstash or directly to Elasticsearch..
Nov 21 12:31:15 template-centos7 systemd[1]: Starting Filebeat sends log files to Logstash or directly to Elasticsearch....
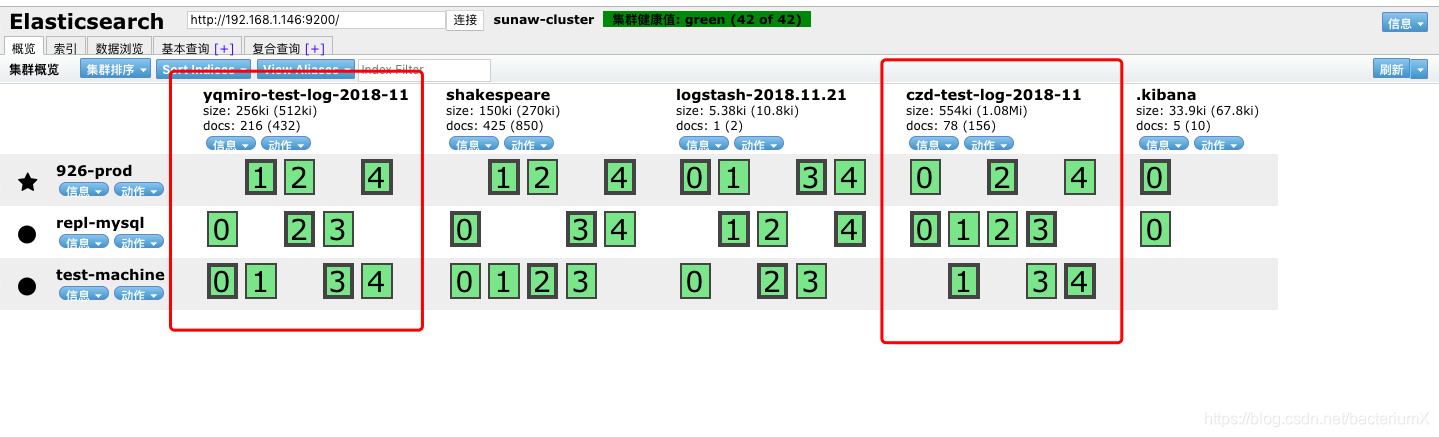
8、采集结果查看
head插件和kibanaWeb界面能查看到采集的数据:
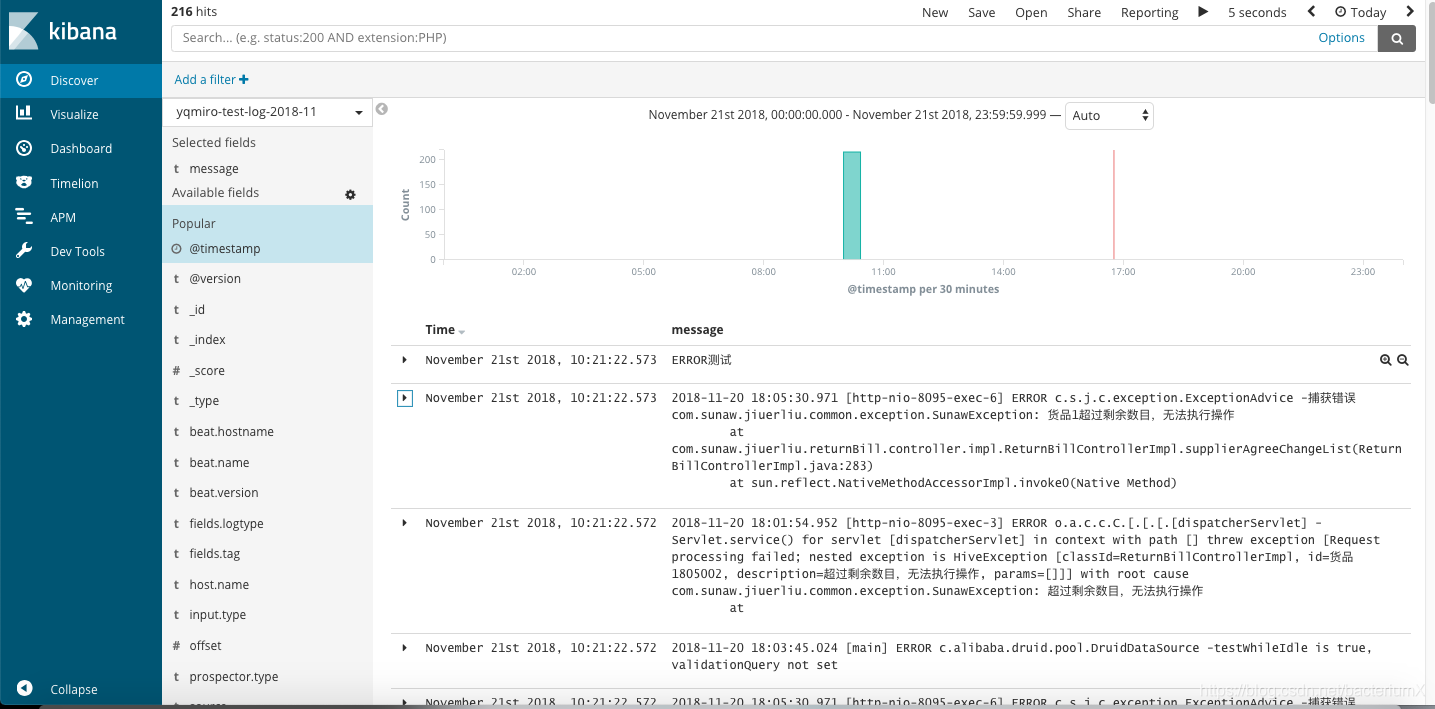
展开message能查看到详细信息:
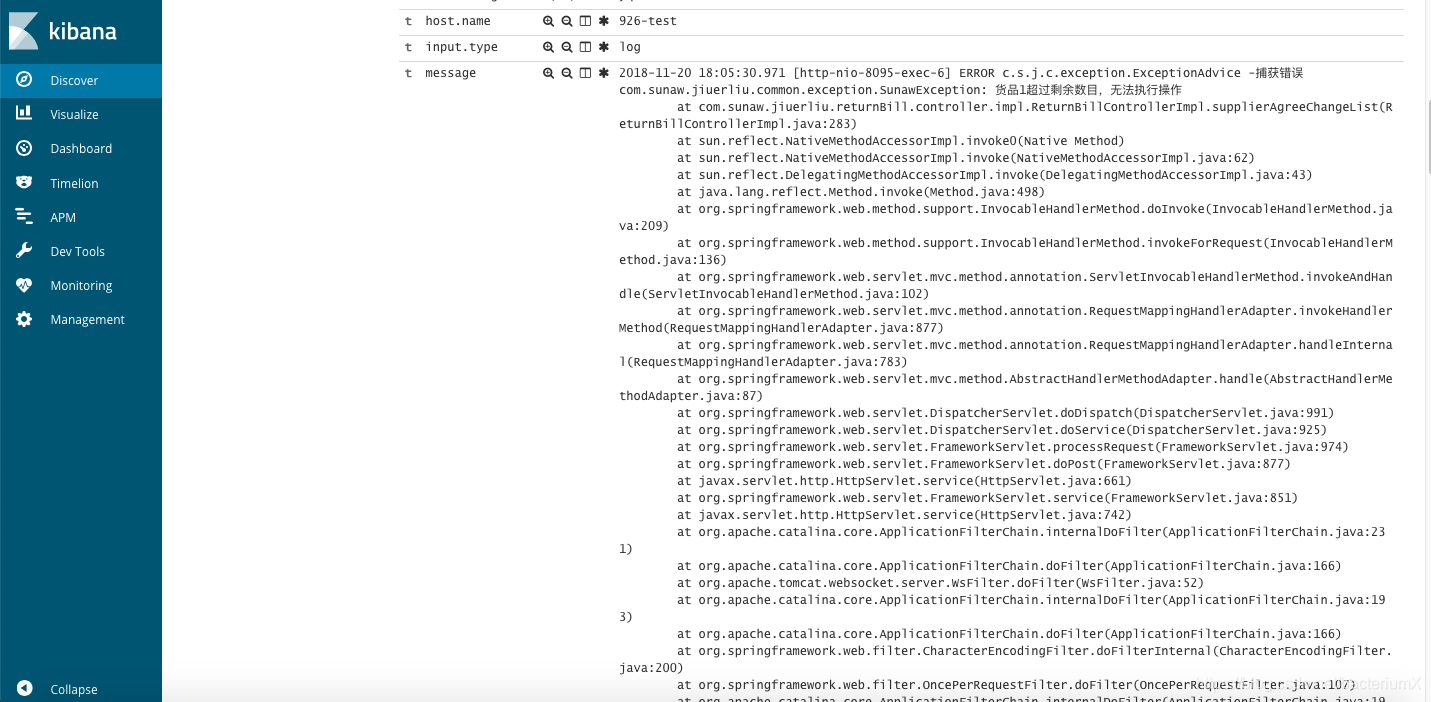
至此,ELK+filebeat采集java日志的搭建过程结束。

















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









