




原文:Building effective agents \ Anthropic (2024年12月20日)
過去一年,我們與來自各行各業的多個團隊合作,這些團隊致力於構建基於大型語言模型(LLM)的代理系統。經驗表明,最成功的實現並不是使用複雜框架或專門庫,而是採用了簡單且可組合的模式。
在本文中,我們分享了與客戶合作以及我們自身構建代理系統的經驗,並向開發者提供有關打造高效代理的實用建議。

什麼是代理(Agents)?
“代理”可以有多種定義。一些客戶將代理定義為能夠自主運行的系統,這些系統可以在長時間內獨立運行,並利用多種工具完成複雜任務。另一些客戶則將代理描述為遵循預定流程的更具規範性的實現方式。在 Anthropic,我們將所有這些變體歸類為代理系統(Agentic Systems),但我們在架構上對工作流和代理進行了重要區分:
- 工作流(Workflows) 是通過預定義的代碼路徑協調 LLM 和工具的系統。(Workflows are systems where LLMs and tools are orchestrated through predefined code paths.)
- 代理(Agents) 則是 LLM 動態指導其自身流程和工具使用的系統,並保持對任務完成方式的控制。(Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.)
以下,我們將詳細探討這兩種類型的代理系統。在附錄 1(“代理實踐 Agents in Practice”)中,我們描述了兩個領域,客戶在這些領域中使用此類系統獲得了特別的價值。
什麼時候該使用代理(以及什麼時候不該使用代理)
在使用 LLM 構建應用時,我們建議採用最簡單的解決方案,並僅在必要時增加複雜性。這可能意味著完全不構建代理系統。代理系統通常以延遲和成本為代價來換取更好的任務性能,因此您需要考慮這種權衡何時合理。
當需要更高的複雜性時:
- 工作流 為定義明確的任務提供了可預測性和一致性;
- 代理 則適用於需要靈活性和基於模型決策的任務,特別是在大規模場景下。
然而,對於許多應用,通過檢索和上下文示例優化單次 LLM 調用通常已經足夠。
何時以及如何使用框架
有許多框架可以簡化代理系統的實現,例如:
- LangChain 的 LangGraph;
- Amazon Bedrock 的 AI Agent 框架;
- Rivet,一個拖放式的 GUI LLM 工作流生成器;
- Vellum,另一個用於構建和測試複雜工作流的 GUI 工具。
這些框架通過簡化低層次任務(如調用 LLM、定義和解析工具以及鏈接調用)來幫助快速入門。然而,這些框架往往會引入額外的抽象層,可能掩蓋底層提示和響應,從而增加調試難度。此外,這些框架可能會誘使您添加不必要的複雜性,而實際只需簡單的設置即可。
我們建議開發者直接使用 LLM API:許多模式可以用幾行代碼實現。如果您確實使用框架,請確保了解底層代碼。對框架內部運行方式的錯誤假設是客戶出錯的一個常見原因。
請參閱我們的 Cookbook(食譜)了解一些示例實現。
構建塊 blocks、工作流 workflows 與代理 agents
在本節中,我們將探討我們在生產環境中觀察到的代理系統的常見模式。我們將從基礎的構建塊——增強型 LLM 開始,逐步增加複雜性,從簡單的組合工作流到自主代理。
構建塊:增強型 LLM(The augmented LLM)
代理系統的基本構建塊是通過檢索 Retrieval、工具 Tools 和內存 Memory 等增強功能增強的 LLM。當前的模型可以主動使用這些能力——生成自己的搜索查詢、選擇適當的工具以及確定需要保留的信息。
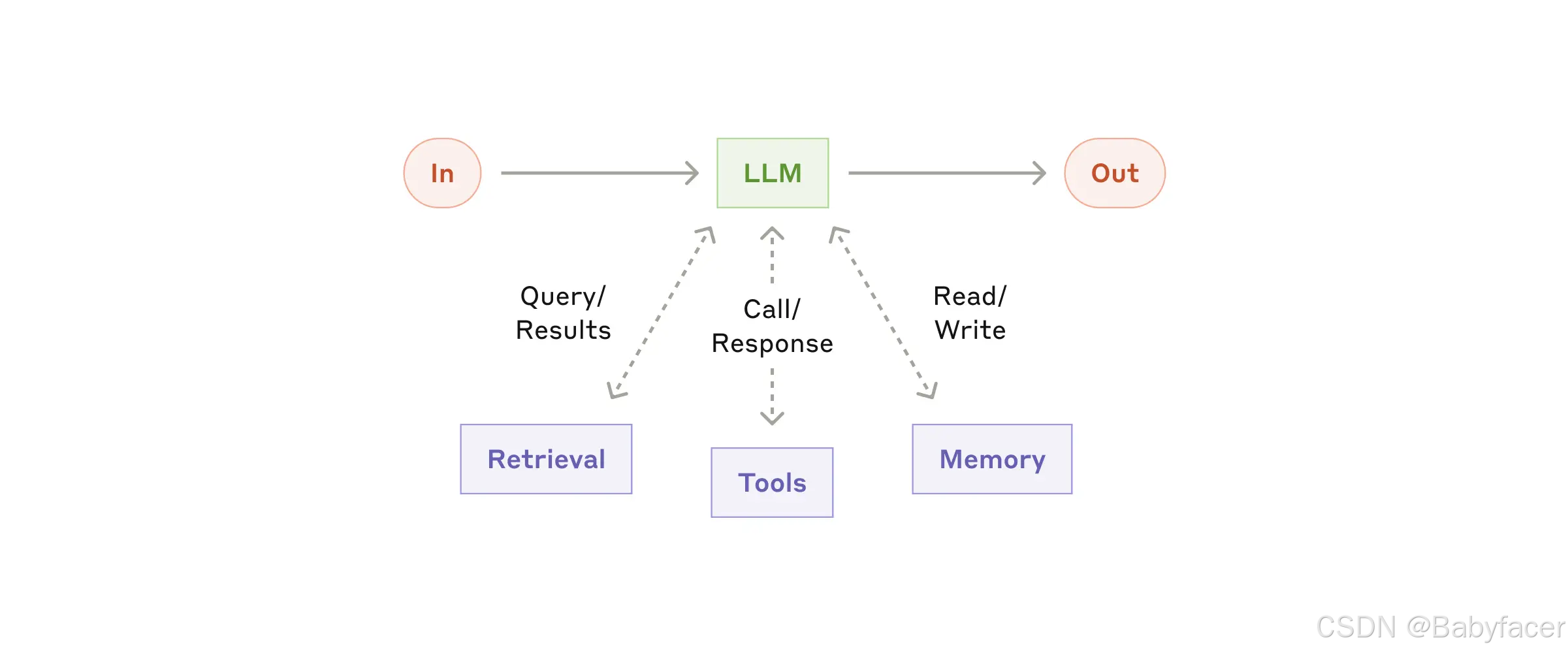
The augmented LLM
我們建議專注於兩個實現的關鍵方面:
- 根據您的特定用例定制這些能力;
- 確保它們為您的 LLM 提供一個簡單、文檔清晰的接口。
儘管有多種實現這些增強功能的方法,其中一個方法是通過我們最近發布的 Model Context Protocol (MCP協議),該協議允許開發者通過簡單的客戶端實現與日益增長的第三方工具生態系統集成。
在本文的其餘部分中,我們假設每次 LLM 調用都可以訪問這些增強功能。
工作流:提示鏈接(Prompt Chaining)
提示鏈接將一個任務分解為一系列步驟,其中每次 LLM 調用處理前一步的輸出。您可以在中間步驟添加程序化檢查(見下圖中的“gate”)以確保流程保持正軌。
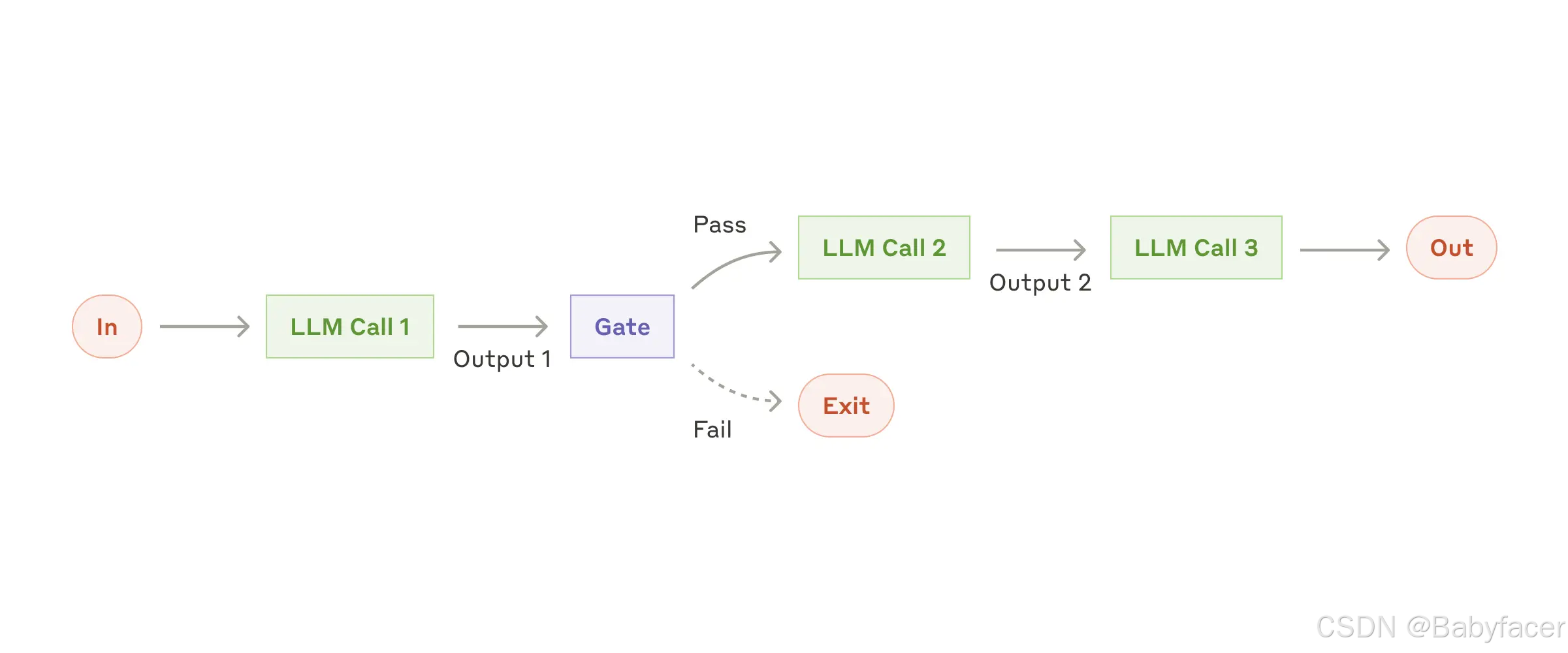
The prompt chaining workflow
什麼時候使用此工作流:此工作流適用於任務可以輕鬆且清晰地分解為固定子任務的情況。主要目的是用更高的準確性換取延遲,通過將每次 LLM 調用變成更簡單的子任務來實現。
適用示例:
- 生成營銷文案,然後將其翻譯成不同語言;
- 撰寫文檔大綱,檢查該大綱是否符合某些標準,然後根據大綱撰寫文檔。
工作流:路由
路由將輸入進行分類並引導至特定的後續任務。此工作流允許分離關注點並構建更專門的提示。如果沒有此工作流,優化某一類輸入可能會損害其他輸入的性能。
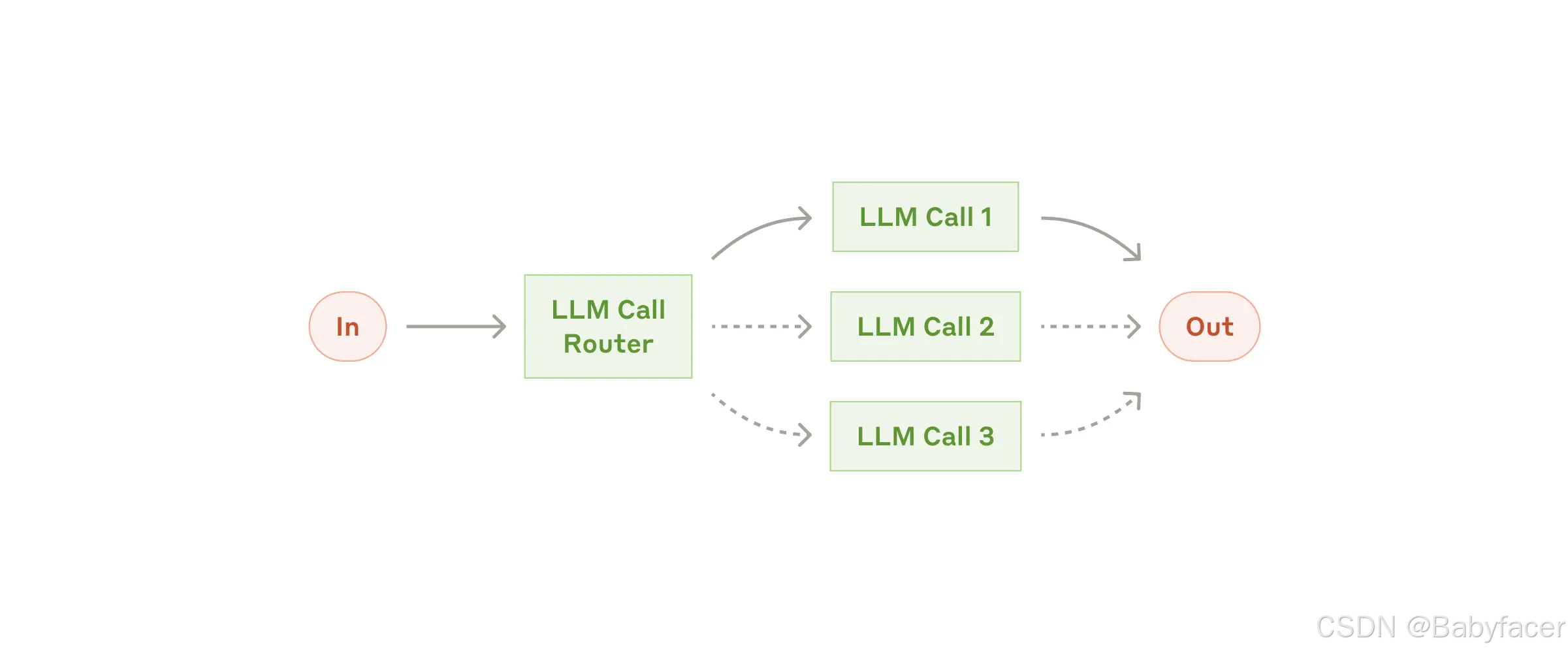
The routing workflow
什麼時候使用此工作流:路由適用於任務複雜且有明顯類別劃分的情況,並且分類可以準確完成(無論是通過 LLM 還是傳統分類模型/算法)。
適用示例:
- 將不同類型的客戶服務查詢(如一般問題、退款請求、技術支持)引導至不同的下游流程、提示和工具;
- 將簡單/常見問題路由至較小的模型(如 Claude 3.5 Haiku),而將困難/不常見問題路由至更高性能的模型(如 Claude 3.5 Sonnet),以優化成本和速度。
工作流:並行化(Parallelization)
LLM 有時可以同時處理任務,並以編程方式聚合其輸出。並行化有兩種主要變體:
- 分區(Sectioning):將任務分解為獨立子任務並行運行;
- 投票(Voting):多次運行相同任務以獲得多樣化輸出。
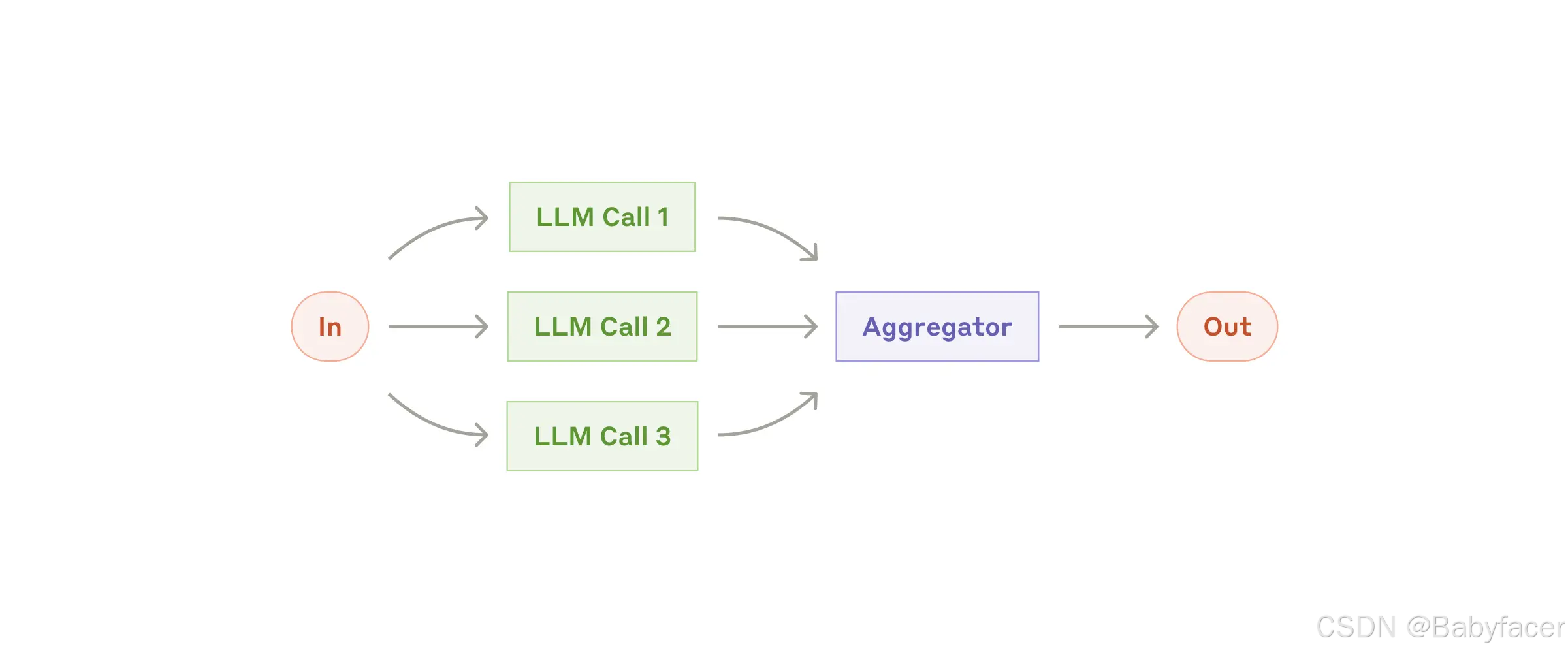
The parallelization workflow
什麼時候使用此工作流:並行化適用於可以並行化以加快速度的任務,或需要多種視角或嘗試以獲得更高信心結果的情況。對於涉及多個考量因素的複雜任務,通常每個考量因素由單獨的 LLM 調用處理效果更佳,因為這樣可以專注於每個具體方面。
適用示例:
分區:
- 實現防護措施,其中一個模型實例處理用戶查詢,另一個實例篩選不適當內容或請求。這種方法通常比讓同一 LLM 同時處理防護和核心響應更有效;
- 自動化 LLM 性能評估,每次 LLM 調用評估給定提示的不同方面性能。
投票:
- 審查代碼漏洞,幾個不同的提示審查代碼並在發現問題時進行標記;
- 評估一段內容是否不適當,通過多個提示評估不同方面,或設置不同投票門檻以平衡誤報和漏報。
工作流:協調員-工作者(Orchestrator-Workers)
在協調員-工作者工作流中,中心 LLM 動態分解任務,將其分配給工作者 LLM,並綜合其結果。
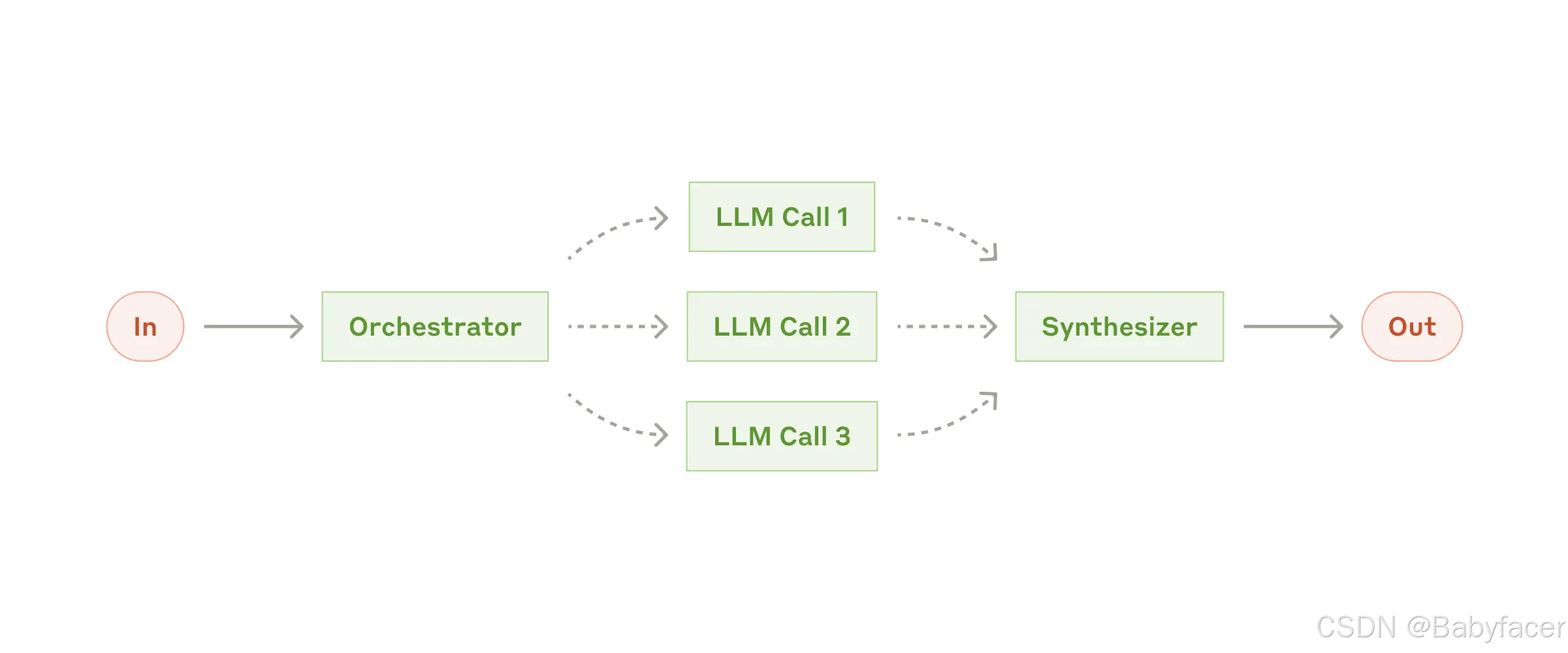
The orchestrator-workers workflow
什麼時候使用此工作流:此工作流適用於無法預測所需子任務的複雜任務(例如在編碼中,需要更改的文件數量和每個文件的更改方式可能取決於任務)。儘管其拓撲結構與並行化類似,但關鍵區別在於其靈活性——子任務不是預定義的,而是由協調員根據具體輸入動態確定。
適用示例:
- 編碼產品,每次需要對多個文件進行複雜更改;
- 搜索任務,涉及從多個來源收集和分析信息以找出可能相關的信息。
工作流:評估者-優化器(Evaluator-Optimizer)
在評估者-優化器工作流中,一次 LLM 調用生成響應,而另一次進行評估和反饋,形成一個循環。
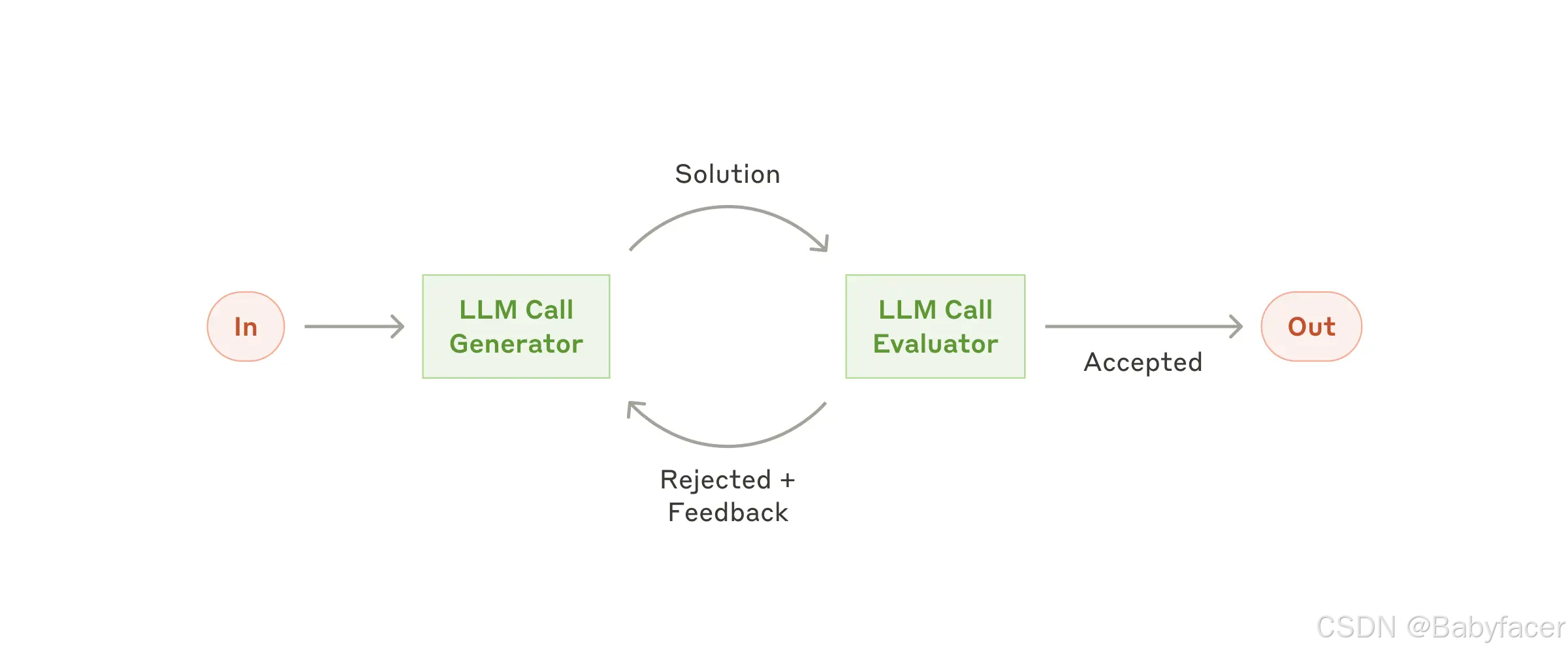
The evaluator-optimizer workflow
什麼時候使用此工作流:當存在明確的評估標準,且迭代改進可以提供可衡量的價值時,此工作流特別有效。兩個跡象表明此方法適用:
- 當人類表達反饋時,LLM 的響應可以顯著改進;
- LLM 本身能夠提供有用的反饋。這類似於人類作家創作精煉文檔時的迭代過程。
適用示例:
- 文學翻譯,涉及翻譯 LLM 可能最初未捕捉到的細微差別,但評估 LLM 可以提供有用的批評;
- 複雜的搜索任務,需多輪搜索和分析以收集全面信息,評估者判斷是否需要進一步搜索。
代理
隨著 LLM 在理解複雜輸入、推理和計劃、可靠使用工具以及從錯誤中恢復等關鍵能力上的成熟,代理正逐漸應用於生產中。代理的工作開始於用戶的命令或與用戶的互動討論。一旦任務明確,代理將計劃並自主運行,必要時返回用戶尋求更多信息或判斷。在執行過程中,代理在每個步驟中獲取環境的“真實數據”(如工具調用結果或代碼執行),以評估其進度。代理可在檢查點或遇到阻礙時暫停,等待人類反饋。任務通常在完成時終止,但也可以設置停止條件(如最大迭代次數)以保持控制。
代理可以處理複雜的任務,但其實現方式通常相對簡單。它們通常只是以環境反饋為基礎,在循環中使用工具的大型語言模型(LLMs)。因此,清晰且周到地設計工具集及其文檔是至關重要的。我們在附錄 2(工具的提示工程 Prompt Engineering your Tools )中詳細說明了工具開發的最佳實踐。
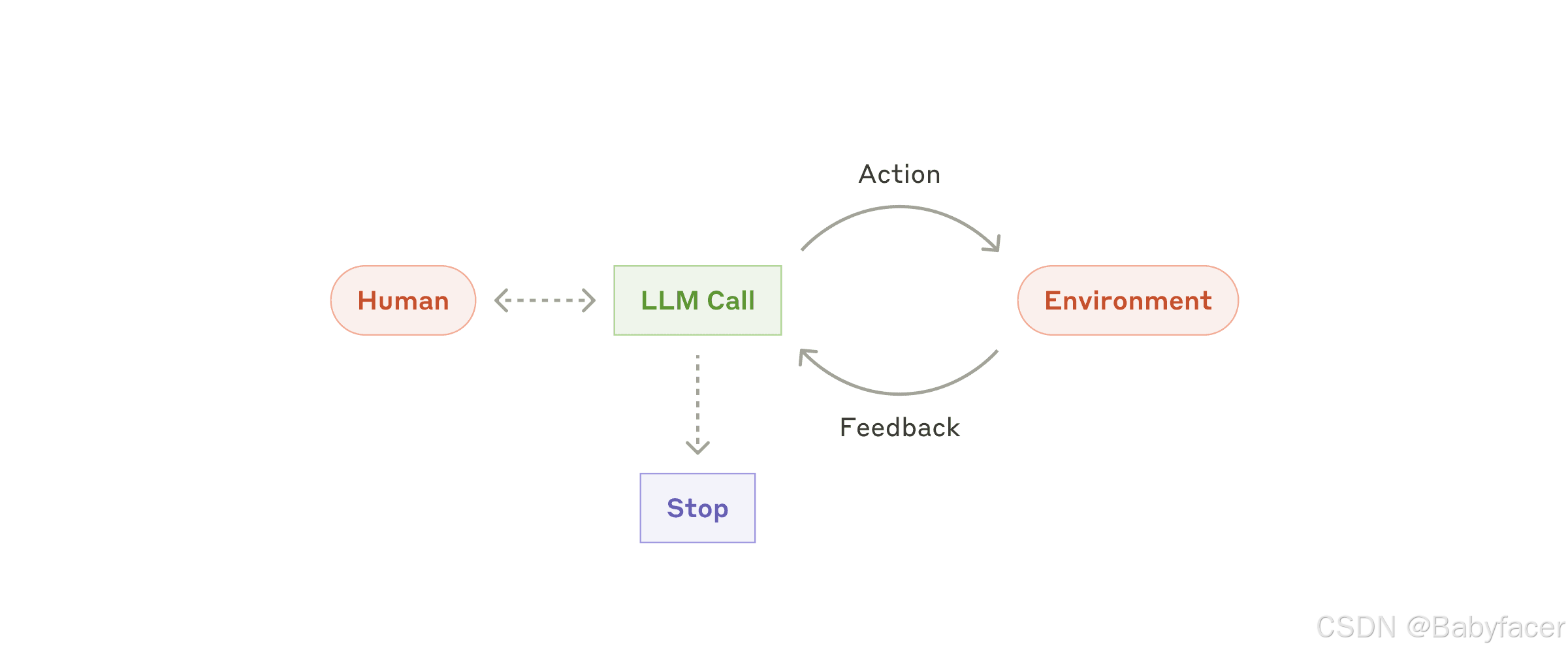
Autonomous agent
什麼時候使用代理:代理適用於開放式問題,無法預測所需步驟數,且無法硬編碼固定路徑的情況。LLM 可能需要多輪操作,因此您必須對其決策能力有一定信任。代理的自主性使其非常適合在受信環境中擴展任務。
適用示例:
以下是我們自身實現中的示例:
- 編碼代理 用於解決 SWE-bench 任務,這些任務涉及根據任務描述對多個文件進行編輯;
- 我們的“計算機使用”參考實現,其中 Claude 使用計算機完成任務。
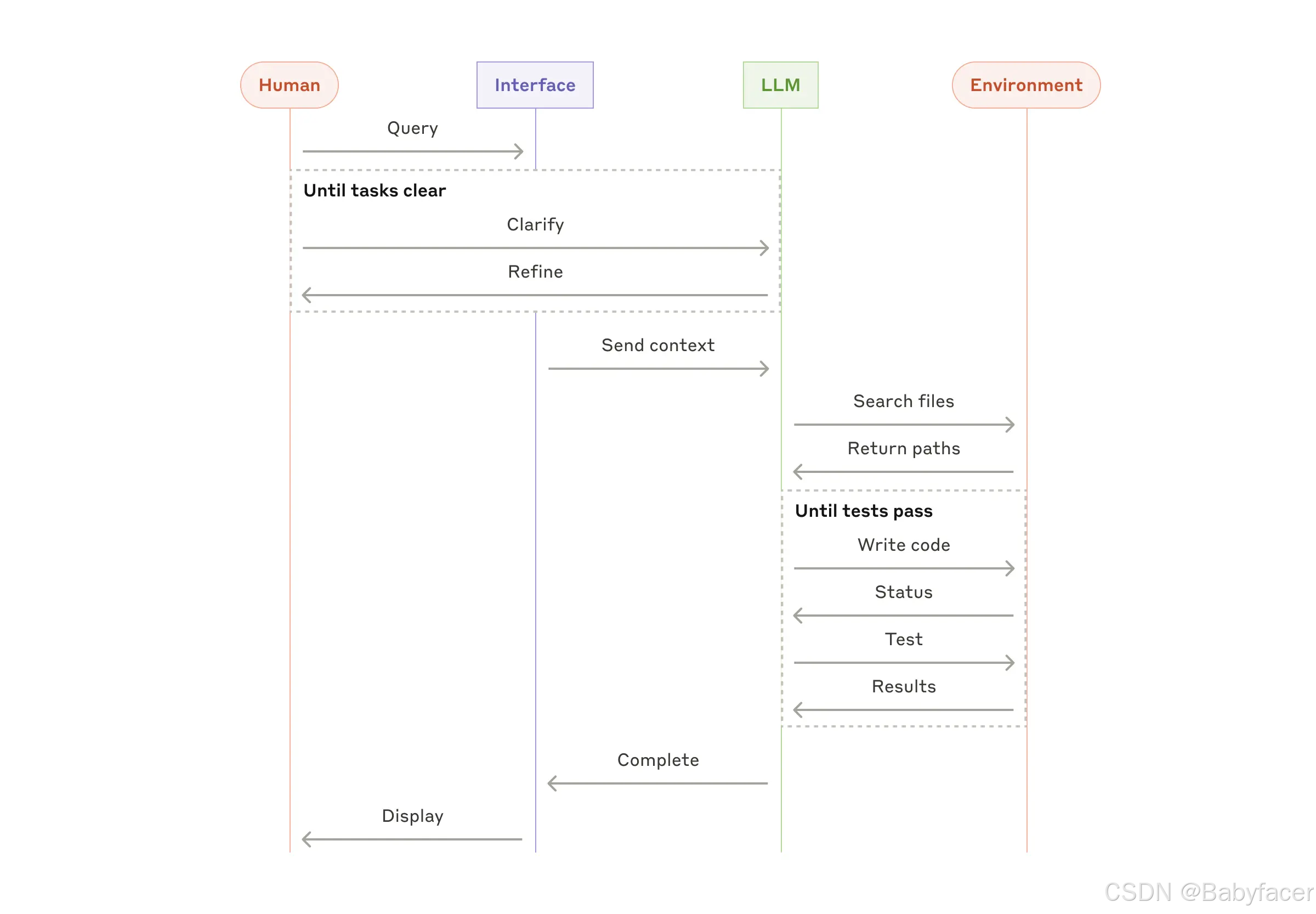
High-level flow of a coding agent
結合與定制這些模式
這些構建塊並非規範性指導,而是常見模式,開發者可以根據不同的用例進行調整和組合。如同任何 LLM 功能,成功的關鍵在於測量性能並迭代實現。我們重申:僅在複雜性能明顯改善結果時才應增加複雜性。
總結
在 LLM 領域,成功的關鍵不在於構建最複雜的系統,而在於構建適合您需求的系統(building the right system for your needs)。從簡單的提示入手,通過全面的評估進行優化,僅在更簡單的解決方案無法滿足需求時添加多步代理系統。
在實現代理時,我們遵循三個核心原則:
- 在代理設計中保持簡潔(Simplicity);
- 優先透明性(transparency),明確展示代理的計劃步驟;
- 通過完善的工具文檔和測試,精心設計代理-計算機接口(ACI)。
框架可以幫助您快速入門,但在進入生產階段時,不要猶豫去減少抽象層,並使用基本組件進行構建。通過遵循這些原則,您可以構建既強大又可靠、可維護且受用戶信任的代理。
致謝
本文由 Erik Schluntz 和 Barry Zhang 撰寫。本工作基於我們在 Anthropic 構建代理的經驗以及客戶分享的寶貴見解,我們深表感謝。
附錄 1:代理實踐(Agents in practice)
我們與客戶的合作揭示了兩個特別有前景的 AI 代理應用,展示了上述模式的實際價值。這兩個應用說明了代理如何在需要對話和行動、具有明確成功標準、支持反饋循環並允許人類監督的任務中發揮最大價值。
A. 客戶支持(Customer Support)
客戶支持結合了熟悉的聊天機器人界面與通過工具集成增強的能力。這是更開放式代理的自然適配,因為:
- 支持交互自然遵循對話流程,同時需要訪問外部信息和操作;
- 工具可集成以檢索客戶數據、訂單歷史和知識庫文章;
- 操作(如退款或更新票據)可通過編程處理;
- 成功可以通過用戶定義的解決方案明確衡量。
多家公司通過基於使用的定價模型(僅對成功解決方案收費)證明了這種方法的可行性,表明對其代理效率的信心。
B. 編碼代理(Coding agents)
軟件開發領域顯示出 LLM 功能的巨大潛力,其能力從代碼補全發展到自主解決問題。代理特別有效,因為:
- 代碼解決方案可通過自動化測試進行驗證;
- 代理可以使用測試結果對解決方案進行迭代;
- 問題空間定義明確且結構化;
- 輸出質量可以客觀衡量。
在我們自身的實現中,代理現在可以基於拉取請求描述解決 SWE-bench Verified 基準中的真實 GitHub 問題。然而,儘管自動化測試有助於驗證功能,人類審查仍然對於確保解決方案符合更廣泛的系統需求至關重要。
附錄 2:提示工程您的工具(Prompt engineering your tools)
無論您構建哪種代理系統,工具可能都將是代理的重要組成部分。工具使 Claude 能夠通過 API 與外部服務互動,具體指定它們的結構和定義。當 Claude 響應時,若計劃調用一個工具,它會在 API 響應中包含一個工具使用塊。工具的定義和規範應該像您的總體提示一樣獲得提示工程的關注。在這份簡短的附錄中,我們描述了如何對工具進行提示工程。
通常有多種方式可以指定相同的操作。例如,可以通過撰寫差異檔案(diff)來指定文件編輯,也可以重寫整個文件。對於結構化輸出,可以將代碼返回在 Markdown 中,或者嵌入到 JSON 中。在軟體工程中,此類差異通常是表面性的,可以無損地相互轉換。然而,對於大型語言模型(LLM)來說,有些格式比其他格式更難撰寫。例如,撰寫差異檔案(diff)需要在編寫新代碼之前,先知道塊標頭中正在更改的行數。而將代碼嵌入 JSON(與 Markdown 相比)則需要額外地轉義換行符和引號。
我們對工具格式設計的建議如下:
- 給模型足夠的 Token 空間來「思考」,避免讓它陷入困境。
- 保持格式接近於模型在互聯網上自然見過的文本樣式。
- 確保沒有額外的格式負擔,例如要求準確計算成千上萬行代碼,或是對編寫的代碼進行字符串轉義。
一條經驗法則是:思考在人機界面(HCI)上投入了多少精力,並計畫在創建良好的代理-計算機界面(ACI)上投入同等的努力。以下是一些具體建議:
-
站在模型的角度思考。
這個工具的描述和參數是否足夠明顯,讓人可以直接使用它,還是需要仔細思考後才能順利操作?如果是後者,對模型來說可能也是如此。一個好的工具定義通常包括範例用法、邊界情況、輸入格式要求以及與其他工具的明確分界。 -
如何修改參數名稱或描述,使其更清晰?
將其視為為團隊中的初級開發者撰寫優秀的文檔註釋(docstring)。當使用許多相似的工具時,這一點尤為重要。 -
測試模型如何使用你的工具:
在工作台中運行多個示例輸入,觀察模型會犯哪些錯誤,並進行迭代改進。 -
防錯設計(Poka-yoke)你的工具:
修改參數,使得犯錯變得更加困難。
在為 SWE-bench 構建代理時,我們實際上花了更多時間優化工具,而不是優化整體提示。例如,我們發現當代理移出根目錄後,模型在使用相對文件路徑的工具時會犯錯。為了解決這個問題,我們將工具改為始終要求絕對文件路徑,結果發現模型能完美地使用這種方法。

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









