



有些东西真的不常用,但还是要知道,毕竟我们是需要考试的小学生。我的复习方式就是去看别人的博客,已经记住的就不迁移了,忘了的忽略的就需要借各位博客大佬的了!
1.基础类型、运算符
| 简单类型 | boolean | byte | char | short | int | long | float | double | void |
|---|---|---|---|---|---|---|---|---|---|
| 二进制位数 | 1 | 8 | 16 | 16 | 32 | 64 | 32 | 64 | - |
| 封装器类 | Boolean | Byte | Char | Short | Integer | Long | Float | Double | Void |
| 范围 | - | -128~127 | - | -32768~32767 | -2^31~2^31-1 | -2^63~2^63-1 | 3.4e-45~1.4e38 | 4.9e-324~1.8e308 | - |
| 说明 | 二进制位数:Byte.SIZE最小值:Byte.MIN_VALUE最大值:Byte.MAX_VALUE | 存储Unicode码,可以存中文,因为这种编码和中文都占两个字节 | 二进制位数:Short.SIZE最小值:Short.MIN_VALUE最大值:Short.MAX_VALUE | 二进制位数:Double.SIZE最小值:Double.MIN_VALUE最大值:Double.MAX_VALUE |
基本类型的优势:数据存储相对简单,运算效率比较高
包装类的优势:有的容易,比如集合的元素必须是对象类型,满足了java一切皆是对象的思想
进行混合运算的时候,byte,short,char不会相互转换,都会自动类型提升为int类型,其他类型进行混合运算的是小的数据类型提升为大的
byte,short,char – int – long – float – double
任何数据类型用+与字符串相连接都会产生新的字符串
System.out.println(“hello”+’a’+1); //运算结果:helloa1
System.out.println(‘a’+1+”hello”); //运算结果:98hello
%运算符结果的符号只和左边有关系,与右边无关
&&和&的区别?
a:最终结果一样。
b:&&具有短路效果。左边是false,右边不执行。
&是无论左边是false还是true,右边都会执行
||跟|区别和上面的一样的意思,虽然最终结果是一样的,但||左边是true,右边就不执行了
2.面向对象三大特性
封装:隐藏对象的属性和实现细节,仅对外提供公共访问方式
封装的好处:
(1)将外界的变化隔离,使程序具备独立、安全和稳定性。
(2)便于设计者使用,提高代码的复用性封装的原则
(1)将不需要对外提供的内容都隐藏起来
(2)把实现细节隐藏,提供可以对其进行访问公共的方式
封装的方式
(1)将某一功能、属性抽离出来,独立写成单独的方法或类
(2)设置访问权限
继承:
继承的作用:
(1)父类具备的方法子类可以直接继承过来,不用重新书写,提高了代码的复用性
(2)让类与类之间产生关系,有了关系才有多态的实现
(3)Java中只支持单继承,不支持多继承,因为多继承存在安全隐患(当多个父类存在同个功能时,子类不确定要运行哪一个),Java支持多层继承,即父类还可以继承其他类,java用另一种机制解决单继承的局限性,即多实现
多态:某一类事物具备的多种表现形态
表现形式:
(1)父类的引用指向自己的子类对象
(2)父类的引用接受自己的子类对象
Override(重写)和Overload(重载)的区别?Overload能改变返回值类型吗?
方法重写:子类中出现了和父类中方法声明一模一样的方法。与返回值类型有关,返回值是一致(或者是子父类)的
方法重载:本类中出现的方法名一样,参数列表不同的方法。与返回值类型无关。
final修饰特点
修饰类,类不能被继承
修饰变量,变量就变成了常量,只能被赋值一次
修饰方法,方法不能被重写
static 关键字:
static方法就是没有this的方法。在static方法内部不能调用非静态方法,反过来是可以的。而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用static方法。static变量是被所有对象所共享的,在内存中只要一个副本,他会在类初次加载时被初始化,static变量是类所有的,非static变量是对象所有的。
static代码块可以用来优化程序性能,static可以放到类的任何地方,类中以有多个static块
。(在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次)类加载时执行一次这种特性正好用来优化程序,比如类中一个方法有常用的变量可以放到静态块中,避免了空间的浪费。static不允许用来修饰局部变量。
3.核心类
String类:
public class StringCls {
public static void main(String args[]){
String s1 = "HELLO world";
String s2 = new String("hello WORLD");
String s3 = "this is a test";
String s4 = "this is a case";
String s5 = "";
String s6 = null;
System.out.println(s1.charAt(2));
// L
System.out.println(s1.compareTo(s2));
// -32
System.out.println(s1.compareToIgnoreCase(s2));
// 0
System.out.println(s1.concat(s2));
// HELLO worldhello WORLD
System.out.println(s1.substring(10));
// d
char[] chs = s4.toCharArray();
String s7 = String.copyValueOf(chs);
String s8 = String.copyValueOf(chs,0,10);
System.out.println(s7);
System.out.println(s8);
// this is a case
// this is a
System.out.println(s1.endsWith("world"));
System.out.println(s1.equals(s2));
System.out.println(s1.equalsIgnoreCase(s2));
// true
// false
// true
char[] tt = {'1','2','3'};
s3.getChars(0,1,tt,1);
String s9 = String.copyValueOf(tt);
System.out.println(s9);
// 1t3
System.out.println(s3.indexOf('t'));
System.out.println(s3.indexOf('t',5));
System.out.println(s3.intern());
// 0
// 10
// this is a test
System.out.println(s3.isEmpty());
System.out.println(s3.lastIndexOf('t'));
System.out.println(s3.lastIndexOf("is"));
// false
// 13
// 5
System.out.println(s3.matches("/w+"));
System.out.println(s3.replace("is", "##"));
String[] tmp = s3.split(" ");
// false
// th## ## a test
System.out.println(tmp[1]);
System.out.println(s1.toLowerCase());
System.out.println(s1.toUpperCase());
System.out.println(" 123 ".trim());
// 123
// hello world
// HELLO WORLD
// HELLO world
StringBuffer stringBuffer = new StringBuffer(s1.toLowerCase());
Per p = new Per();
stringBuffer.append(p);
System.out.println(stringBuffer.toString());
// StringBuffer的append 方法可以连接各种基础类型、char[]、String以及StringBuffer
//StringBuffer的append 方法可以连接各种基础类型、char[]、String以及StringBuffer
//而insert的方法可以 控制插入的位置,同时这个类也具有和String相同的许多方法
}
}
class Per{
public static String name = "pipi";
public static Integer age = 1324;
}public static void main( String args[]){
/**
* Date
*/
Date d1 = new Date();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Date d2 = new Date();
System.out.println(d1.after(d2));
System.out.println(d1.before(d2));
System.out.println(d1.compareTo(d2));
System.out.println(d1.equals(d2));
// false
// true
// -1
// false
System.out.println(d1.getTime());
// 1535091741035
/**
* DateFormat
*/
System.out.println("-------------------------------------------");
DateFormat dateFormat = DateFormat.getDateInstance();
System.out.println(dateFormat.format(new Date()));
//2018-8-24
System.out.println(dateFormat.getCalendar());
System.out.println(dateFormat.getTimeZone());
/**
* SimpleDateFormat
*/
System.out.println("-------------------------------------------");
SimpleDateFormat f1 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
SimpleDateFormat f2 = new SimpleDateFormat("yy年M月dd日");
long t1 = System.currentTimeMillis();
System.out.println(f1.format(t1));
System.out.println(f2.format(t1));
// 18-08-24 14:45:09
// 18年8月24日
// G 年代标志符
// y 年
// M 月
// d 日
// h 时 在上午或下午 (1~12)
// H 时 在一天中 (0~23)
// m 分
// s 秒
// S 毫秒
// E 星期
// D 一年中的第几天
// F 一月中第几个星期几
// w 一年中第几个星期
// W 一月中第几个星期
// a 上午 / 下午 标记符
// k 时 在一天中 (1~24)
// K 时 在上午或下午 (0~11)
// z 时区
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String str = "2018-8-23";
Date t = new Date();
try {
t = sdf.parse(str);
} catch (ParseException e) {
e.printStackTrace();
}
SimpleDateFormat sdf1 = new SimpleDateFormat("yyyy年MM月dd日");
System.out.println(sdf1.format(t));
// 2018年08月23日
System.out.println("-------------------------------------------");
/**
* Calender
*/
Calendar calendar = Calendar.getInstance();
System.out.println(calendar);
// calendar.set(2018,8,23);
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH)+1;
int date = calendar.get(Calendar.DAY_OF_MONTH);
int hour = calendar.get(Calendar.HOUR_OF_DAY);
int minute = calendar.get(Calendar.MINUTE);
int second = calendar.get(Calendar.SECOND);
int day = calendar.get(Calendar.DAY_OF_WEEK);
System.out.println("year"+year);
System.out.println("month"+month);
System.out.println("date"+date);
System.out.println("hour"+hour);
System.out.println("minute"+minute);
System.out.println("second"+second);
System.out.println("day"+((day-1)>0?day-1:7));
// Calendar.YEAR---年份;
// Calendar.MONTH---月份;
// Calendar.DATE---日期;
// Calendar.DAY_OF_MONTH---日期,和Calendar.DATE字段完全相同;
// Calendar.HOUR---12小时制的小时数;
// Calendar.HOUR_OF_DAY---24小时制的小时数;
// Calendar.MINUTE---分钟;
// Calendar.SECOND---秒;
// Calendar.DAY_OF_WEEK---星期几 周日为1 周一是2
Calendar c1 = Calendar.getInstance();
c1.add(Calendar.DATE, 100);
int y1 = c1.get(Calendar.YEAR);
int m1 = c1.get(Calendar.MONTH);
int dd = c1.get(Calendar.DATE);
System.out.println(y1+"-"+m1+"-"+dd);
System.out.println(calendar.after(c1));
System.out.println("-------------------------------------------");
/**
* GregorianCalendar
*/
Calendar gcal = new GregorianCalendar();
gcal.setTime(new Date());
System.out.println(gcal.get(Calendar.YEAR));
System.out.println(gcal.get(Calendar.MONTH));
System.out.println(gcal.get(Calendar.DATE));
System.out.println(gcal.getActualMaximum(Calendar.DAY_OF_MONTH));
System.out.println("-------------------------------------------");
}Math类
补充之前:
抽象类:
抽象类中应该包含抽象方法,否则没有意义。抽象类使用来继承的,它的作用?有一点想多态或者一种约束的赶脚,比如说每个人都会吃饭,但是人与人之间吃饭的方式不同,所以不能确定他们是怎么吃饭的,但他们一定会吃饭。。。
特点:
1.抽象方法一定在抽象类中。
2.抽象方法和抽象类都必须被abstract关键字修饰。
3.抽象类不可以用new创建和实例化对象。因为抽象类本身就是不完整的。
4.抽象类的抽象方法要被使用,必须有子类复写所有的抽象方法后,建立子类对象调用。
5.如果子类只覆盖了部分抽象方法,那么该子类还是一个抽象类。
注意点:(abstract关键字和那些关键字不能共存)
1.final: 被final修饰的类不能有子类(不能被继承)而被abstract关键字修饰的类一定是一个父类(一定要被继承)
2.private: 抽象类中私有的抽象方法,不能被子类所知,就无法被复写。那么子类就还是一个抽象类,同时抽象方法出现就是要被复写的。
3.static: 如果static可以修饰抽象方法,那么直接调用类名就可以访问,但抽象方法运行没有意义。
接口(interface):
接口是一种对行为的抽象,接口中的变量会被隐式的指定为public static final,接口中的方法只能是public abstract。
作用:(原文地址:https://www.cnblogs.com/zhaoyanjun/p/5320034.html)
1、重要性:在Java语言中, abstract class 和interface 是支持抽象类定义的两种机制。正是由于这两种机制的存在,才赋予了Java强大的 面向对象能力。
2、简单、规范性:如果一个项目比较庞大,那么就需要一个能理清所有业务的架构师来定义一些主要的接口,这些接口不仅告诉开发人员你需要实现那些业务,而且也将命名规范限制住了(防止一些开发人员随便命名导致别的程序员无法看明白)。
3、维护、拓展性:比如你要做一个画板程序,其中里面有一个面板类,主要负责绘画功能,然后你就这样定义了这个类。
可是在不久将来,你突然发现这个类满足不了你了,然后你又要重新设计这个类,更糟糕是你可能要放弃这个类,那么其他地方可能有引用他,这样修改起来很麻烦。
如果你一开始定义一个接口,把绘制功能放在接口里,然后定义类时实现这个接口,然后你只要用这个接口去引用实现它的类就行了,以后要换的话只不过是引用另一个类而已,这样就达到维护、拓展的方便性。
4、安全、严密性:接口是实现软件松耦合的重要手段,它描叙了系统对外的所有服务,而不涉及任何具体的实现细节。这样就比较安全、严密一些(一般软件服务商考虑的比较多)。
内部类:https://www.cnblogs.com/dolphin0520/p/3811445.html
一个类定义在另一个类或方法中,这样的类成为内部类。一般分为成员内部类、局部内部类、匿名内部类、静态内部类。
1.成员内部类即为普通的类嵌套。
(1)成员内部类可以无条件的访问外部类的所有成员属性和成员方法(包括private成员和静态成员)
(2)当成员内部类拥有和外部类同名的成员变量或者方法是,会发生隐藏现象,及默认情况下访问的是成员内部类的成员。如果访问外部类的同名成员->
(外部类.this.成员变量 | 外部类.this.成员方法)(3)外部类要访问内部类的成员必须想创建一个内部类的对象,然后通过指向这个对象的引用来访问。
2.局部内部类:定义在一个方法或者一个作用域中的类。
(1)它和成员内部类的区别在于局部内部类的访问仅限于方法内部或者该作用域中。
(2)局部内部类就像方法里面的一个局部变量一样,不能用访问限定符和static来修饰。
3.匿名内部类:使用匿名内部类能够在实现父类或者接口中的方法情况下同事产生一个相应的对象。
匿名内部类是唯一一种没有构造器的类。
4.静态内部类:定义在另一个类里面的类,只是在类的前面多了一个static关键字。
泛型:
4.集合
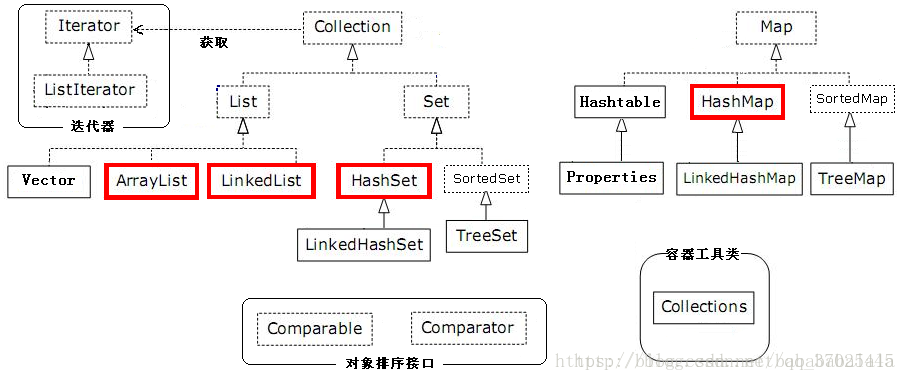
图片来源:https://blog.youkuaiyun.com/qq_37025445/article/details/76563133
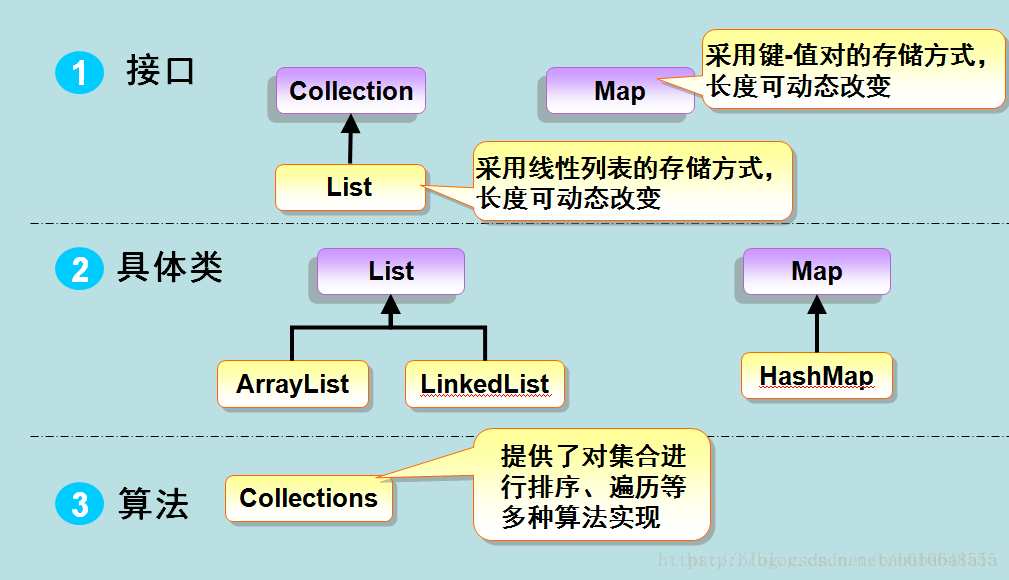
图片来源:https://blog.youkuaiyun.com/u010648555/article/details/56049460
java 集合框架中用的很多的适配器模式。
(1)List相关
ArrayList:基于数组实现,是一个动态的队列,它的容量可以自动增长。
参考:https://blog.youkuaiyun.com/u010648555/article/details/57415966
实现了RandomAccess接口,提供了随机访问功能,实际上就是通过下表序号进行快速访问。
实现了Cloneable接口,即覆盖了函数clone(), 能被克隆。
实现了Serializable接口,支持序列化,也就意味ArrayList能够通过序列化传输。
方法:
sort()方法:
public class Test {
private static final Integer CAPACITY_SIZE = 5;
public static void main ( String args[]){
//sort1
ArrayList<Stu> list1 = new ArrayList<>(CAPACITY_SIZE);
Stu s1 = new Stu("aa",18);
//ellipsis
list1.add(s5);
Collections.sort(list1, new Comparator<Stu>() {
@Override
public int compare(Stu o1, Stu o2) {
if( o1.getAge()>o2.getAge() ){
return 1;
}
return -1;
}
});
Stu tmp = null;
for( int i = 0; i < list1.size(); i++ ){
tmp = list1.get(i);
System.out.println(tmp.getName()+" "+tmp.getAge());
}
System.out.println("---------------------");
ArrayList<Tea> list2 = new ArrayList<Tea>(CAPACITY_SIZE);
Tea t1 = new Tea("aa",18);
//ellipsis
list2.add(t5);
Collections.sort(list2,Tea.ageComparator);
Tea tmp2 = null;
for( int i = 0; i < CAPACITY_SIZE; i++ ){
tmp2 = list2.get(i);
System.out.println(tmp2.getName()+" "+tmp2.getAge());
}
System.out.println("---------------------");
ArrayList<Par> list3 = new ArrayList<Par>(CAPACITY_SIZE);
Par p1 = new Par("aa",18);
//ellipsis
list3.add(p5);
Collections.sort(list3);
Par tmp3 = null;
for( int i = 0; i < list3.size(); i++ ){
tmp3 = list3.get(i);
System.out.println(tmp3.getName()+" "+tmp3.getAge());
}
}
}
class Stu{
//ellipsis
}
class Tea{
//ellipsis
public static Comparator ageComparator = new Comparator<Tea>() {
@Override
public int compare(Tea o1, Tea o2) {
if( o1.getAge() > o2.getAge() ){
return 1;
}
return -1;
}
};
}
class Par implements Comparable<Par>{
// ellipsis
@Override
public int compareTo(Par o) {
if( this.getAge() > o.getAge() ){
return 1;
}
return -1;
}
}其他方法不带药写了。。。
总结:(copy...)
初始化容量 = 10 ,最大容量不会超过 MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8!
indexOf和lastIndexOf 查找元素,若元素不存在,则返回-1!
当ArrayList容量不足以容纳全部元素时,ArrayList会重新设置容量:新的容量=“(原始容量x3)/2 ”。这里找到一篇俺觉得很好的文章:https://www.cnblogs.com/ShanHeDiao/p/4402030.html
从代码中可以看出,当容量不够时,每次增加元素,都要将原来的元素拷贝到一个新的数组中,非常之耗时,也因此建议在事先能确定元素数量的情况下,才使用ArrayList,否则建议使用LinkedList。
ArrayList基于数组实现,可以通过下标索引直接查找到指定位置的元素,因此查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低。
个人思考:写东西的时候ArrayList 基本上是最常用的集合,个人感觉一是它查询效率高二可能就是add()方法导入加入元素比较快。
LinkedList: 基于双向链表,可以当做堆栈、队列、双端队列来使用
参考:https://blog.youkuaiyun.com/u010648555/article/details/58680439
方法:
boolean add(E e) 将指定元素添加到此列表的结尾。
void add(int index, E element) 在此列表中指定的位置插入指定的元素。
boolean addAll(Collection<? extends E> c) 添加指定 collection 中的所有元素到此列表的结尾,顺序是指定 collection 的迭代器返回这些元素的顺序。
boolean addAll(int index, Collection<? extends E> c) 将指定 collection 中的所有元素从指定位置开始插入此列表。
void addFirst(E e) 将指定元素插入此列表的开头。
void addLast(E e) 将指定元素添加到此列表的结尾
E get(int index) 返回此列表中指定位置处的元素。
E getFirst() 返回此列表的第一个元素。
E getLast() 返回此列表的最后一个元素。
int indexOf(Object o) 返回此列表中首次出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。
int lastIndexOf(Object o) 返回此列表中最后出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。
E peek() 获取但不移除此列表的头(第一个元素)。
E poll() 获取并移除此列表的头(第一个元素)
E pop() 从此列表所表示的堆栈处弹出一个元素。
void push(E e) 将元素推入此列表所表示的堆栈。
E remove() 获取并移除此列表的头(第一个元素)。
E remove(int index) 移除此列表中指定位置处的元素。
boolean remove(Object o) 从此列表中移除首次出现的指定元素(如果存在)。
E removeFirst() 移除并返回此列表的第一个元素。
E removeLast() 移除并返回此列表的最后一个元素。
E set(int index, E element) 将此列表中指定位置的元素替换为指定的元素。
比较:
ArrayList: 数组实现, 查找快, 增删慢
由于是数组实现, 在增和删的时候会牵扯到数组增容, 以及拷贝元素. 所以慢。数组是可以直接按索引查找, 所以查找时较快
LinkedList: 链表实现, 增删快, 查找慢
由于链表实现, 增加时只要让前一个元素记住自己就可以, 删除时让前一个元素记住后一个元素, 后一个元素记住前一个元素. 这样的增删效率较高但查询时需要一个一个的遍历, 所以效率较低。
如何选择这两种集合:
ArrayList 适合随机访问, LinkedList 适合增加、删除。
(2)Map相关
HashMap:基于哈希算法的key-value数据结构,允许null键和null值。它是非同步的。
1.当哈希表中的条目数超出了加载因子与当前容量的乘积时,哈希表进行rehash操作,此时映射顺序可能会被打乱
2.HashMap除了非同步和可以使用null之外,其它的和HashTable大致相同。
因为HashMap的容量都是2的整数次幂,如果要自定义容量的话需要适当调整传入参数来保证期望的容量。
源码:
int capacity = 1; while (capacity < initialCapacity) capacity <<= 1;
总结:(copy)
1.HashMap 的实例有两个参数影响其性能:初始容量 和加载因子。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。HashMap的容量不足的时候,可以自动扩容resize(),但是最大容量为MAXIMUM_CAPACITY==2^30!
2.resize非常耗时的操作,因此,我们在用HashMap的时,最好能提前预估下HashMap中元素的个数,这样有助于提高HashMap的性能。
HashTree:基于红黑树的实现,它的键值都是有序的。
(3)Set相关
HashSet:元素有序
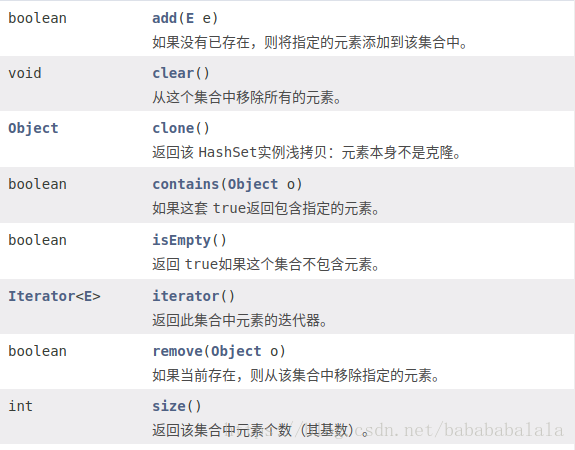
TreeSet:元素无序
补充:
Iterator: 迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不行也要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Iterator在遍历List过程中不能增删,否则会触发快速失败机制(这种机制提供迭代过程中集合的安全性)
改变列表的结构、改变列表的大小、打乱列表的顺序都会触发它。
遍历map:
Map<String, Tmp> map = new HashMap<>(); map.put("frist",new Tmp(43,"fadg")); map.put("second",new Tmp(4363,"gwe")); map.put("shepi",new Tmp(723,"favzxcg")); map.put("third",new Tmp(7653,"ghr")); map.put("adsjf",new Tmp(343,"fjhgj")); Iterator<Map.Entry<String, Tmp>> iterator2 = map.entrySet().iterator(); Map.Entry<String, Tmp> tmp = null; while( iterator2.hasNext() ){ tmp = iterator2.next(); String key = tmp.getKey(); Tmp val = tmp.getValue(); System.out.println(key+" "+val); } Iterator<String> keyIter = map.keySet().iterator(); while( keyIter.hasNext() ){ System.out.println(keyIter.next()); }Arrays:
https://blog.youkuaiyun.com/liu_yanzhao/article/details/70847050
Collections:
System.arraycopy方法:
static voidarraycopy(Object src, int srcPos, Object dest, int destPos, int length)从指定的源数组中复制一个数组,开始在指定的位置,到目标数组的指定位置。
int a[] = new int[20]; int b[] = new int[10]; for( int i = 0 ; i < 10; i++ ){ a[i] = b[i] = i+1; } System.arraycopy(b,0,a,10,10); for( int i = 0; i < a.length; i++ ){ System.out.print(a[i]+" "); } //1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10
5.io流
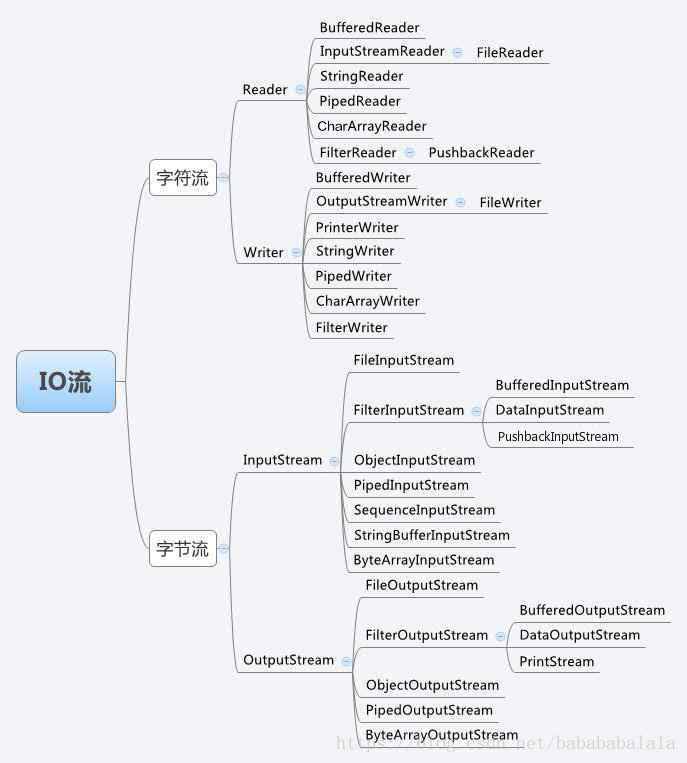
io流主要分为:
基于字节操作的I/O接口:InputStrean 和 OutputStream
基于字符操作的I/O接口:Writer 和 Reader
基于磁盘操作的I/O接口:File
基于网络操作的I/O接口:Socket
编码:
gbk编码中:中文占2个字节、英文占用1个字节
utf-8编码中:中文占3个字节、英文占1个字节
Java是双字节编码:utf-16be ,中英文占用2个字节,当某种编码的字节要转换为字符串时需要用到这种编码,负责会乱码
RandomAccessFile类:
1.这个类读写功能都有,支持随机访问文件,可以访问文件的任意位置
2.它是操作字节的,每次都写都会伴随这指针向后移动
例子:实现多线程复制文件
class copyFileBranch extends Thread{ public class RafImpCopyFile { public static long exeSize = 1024; public static void main(String args[]) throws IOException { int cpu = Runtime.getRuntime().availableProcessors(); System.out.println(cpu); // 最好起CPU核心数量*2 个线程 // 或者 CPU核心数量*2 +2 个线程 File src = new File("/home/liyuan/text/t1/src.zip"); File dest = new File("/home/liyuan/text/t2/dest.zip"); RandomAccessFile rafRead = new RandomAccessFile(src,"r"); RandomAccessFile rafWriter = new RandomAccessFile(dest,"rw"); long length = rafRead.length(); //src file size rafWriter.setLength(length); int exeThread = cpu+2; exeSize = length / exeThread; for( int i = 1; i < exeThread; i++ ){ new copyFileBranch(src, dest, exeSize, i).start(); } rafRead.seek(0); rafWriter.seek(0); byte[] bytes = new byte[1024]; int len = 0; int maxSize = 0; while( (len = rafRead.read(bytes))!=-1||maxSize<exeSize ){ rafWriter.write(bytes, 0, len); System.out.println("Master read "+len+"byte"); maxSize += len; } System.out.println("Master read over, total size:"+maxSize); rafRead.close(); rafWriter.close(); //qita System.out.println(); } } private int threadId; private RandomAccessFile rafRead; private RandomAccessFile rafWriter; private long startPoint; public copyFileBranch(File src, File dest, long startPoint, int threadId){ try { this.rafRead = new RandomAccessFile(src,"r"); this.rafWriter = new RandomAccessFile(dest, "rw"); }catch (IOException e){ e.printStackTrace(); } this.startPoint = startPoint; this.threadId = threadId; } @Override public void run() { try{ rafRead.seek(startPoint);; rafWriter.seek(startPoint); byte[] bytes = new byte[1024]; int len = 0; int maxSize = 0; while( (len = rafRead.read(bytes))!=-1||maxSize<RafImpCopyFile.exeSize ){ rafWriter.write(bytes, 0, len); System.out.println("Thread "+this.threadId+"read "+len+"byte"); maxSize += len; } System.out.println("Thread "+this.threadId+"read over, total size:"+maxSize); }catch (IOException e){ e.printStackTrace(); } finally { try { rafRead.close(); rafWriter.close(); } catch (IOException e) { e.printStackTrace(); } } } }
常用的字节流:
FileInputStream&FileOutputStream :https://blog.youkuaiyun.com/lyb1832567496/article/details/52712218
Buffe
DataInputStream&DataOutputStream:https://www.cnblogs.com/alsf/p/7226027.html?utm_source=itdadao&utm_medium=referral
常用的字符流:
BufferedReader & BufferedWriter :https://blog.youkuaiyun.com/hfreeman2008/article/details/49175331
Path和Files类:
public static void main(String args[]) throws IOException { Path mdir = Paths.get("/home/liyuan/iotest/tmp"); Path mdir1 = Paths.get("/home/liyuan/iotest/opt"); if( !Files.exists(mdir) ){ Files.createDirectories(mdir); } if( !Files.exists(mdir1) ){ Files.createDirectories(mdir1); } Path mfile = Paths.get("/home","liyuan","iotest","tmp","test.txt"); Path mfile1 = Paths.get("/home/liyuan/iotest/opt/test.txt"); if( !Files.exists(mfile) ){ Files.createFile(mfile); } String content = "第一行写入数据\n"; Files.write(mfile,content.getBytes()); String con1 = "这是追加的的数据\n"; Files.write(mfile,con1.getBytes(),StandardOpenOption.APPEND); List<String> list = new ArrayList<>(5); list.add("列表中的数据1"); list.add("列表中的数据2"); list.add("列表中的数据3"); list.add("列表中的数据4"); list.add("列表中的数据5"); Files.write(mfile,list,StandardOpenOption.APPEND); Scanner in = new Scanner(mfile); while( in.hasNext() ){ System.out.println(in.nextLine()); } System.out.println("--------------------------------------"); byte[] bytes = Files.readAllBytes(mfile); String str = new String(bytes,"utf-8"); System.out.println(str); System.out.println("--------------------------------------"); Files.copy(mfile,mfile1); Path mfile2 = Paths.get("/home/liyuan/iotest/opt/move.txt"); Path res = Files.move(mfile,mfile2); System.out.println(res.getFileName()); }
参考:https://www.cnblogs.com/dreamyu/p/6551137.html
6.jdbc
https://www.cnblogs.com/erbing/p/5805727.html
补充:
1.java 和 javac
javac 是Java语言的编译器 java是Java语言的解释器
从命令行来看 javac 可以将Java源文件编译成class字节码文件
Java 可以运行class字节码文件2.Java的jar命令
通过javac xxx.java 可以讲Java源代码编译成(.class)字节码文件
通过Java xxx 可以执行具有主函数的程序
通过jar cvf xxx.jar xxx.class 可以将单个class文件打包为jar包,但打包号的jar包不可运行,需要新建一个文件(mmm)中添加Main-Class: xxx ,来合并打包才可运行
jar cvfm xxx.jar mmm xxx.class
通过java -jar xxx.jar 来运行jar包
通过jar cvfm xxx.jar mmm dir/yyy.class xxx.class 来引用其他class文件并打包
通过jar cvfm xxx.jar mmm xxx.class 并在mmm为见中添加Class-Path: vvv.jar 来引用其他jar包并打包
1.反射原理
java是一门面向对象语言,所以类同样也是对象,java的反射机制是指运行状态中对于任意一个类都能够知道这个类的所有属性和方法,对于任意一个对象都能都调用它的方法,这种动态获取信息,动态调用对象的功能叫做java语言的反射机制。2.垃圾回收机制(对比C++)
C++ 程序可以使用指针,所以它可以使用delete关键字来释放内存,而javac语言有垃圾回收机制gc来根据自己的策略来回收堆中的内存,垃圾回收机制主要的回收策略有引用计数法和碎片清理法。3.java 和 javac
javac 是Java语言的编译器 java是Java语言的解释器
从命令行来看 javac 可以将Java源文件编译成class字节码文件
Java 可以运行class字节码文件4.Java的jar命令
通过javac xxx.java 可以讲Java源代码编译成(.class)字节码文件
通过Java xxx 可以执行具有主函数的程序
通过jar cvf xxx.jar xxx.class 可以将单个class文件打包为jar包,但打包号的jar包不可运行,需要新建一个文件(mmm)中添加Main-Class: xxx ,来合并打包才可运行
jar cvfm xxx.jar mmm xxx.class
通过java -jar xxx.jar 来运行jar包
通过jar cvfm xxx.jar mmm dir/yyy.class xxx.class 来引用其他class文件并打包
通过jar cvfm xxx.jar mmm xxx.class 并在mmm为见中添加Class-Path: vvv.jar 来引用其他jar包并打包5.Java的字节码文件
java能在不同的平台上运行无阻是依靠它的jvm,而.class这种字节码文件就是jvm可以识别的一种16进制文件。6.Java中堆和栈的区别
堆和栈都属于java内存的一种,java都会使用gc来回收它们
堆内存用来存放new创建的对象和数组而栈内存用来存放方法或者局部变量
堆是先进先出,后进后出的,而栈内存是后进先出,先进后出
(在栈中定义一个特殊的变量,让这个变量的取值等于堆中数组或对象的首地址,栈中这个变量就成了数组或对象的引用变量,而这种栈中的变量指向堆内存中的变量,这就是java中的指针)7.java的深拷贝和浅拷贝
如果一个类实现了Cloneable接口并且覆盖clone()方法那么这个类可以被拷贝
拷贝分为浅拷贝和深拷贝,浅拷贝后新对象中的对象引用还是指向旧对象的地址,
如果这个被引用的对象同样实现了Cloneable接口的话,那么这个时候的拷贝属于深拷贝,
但如果这个被引用的对象同样引用了其他的对象,那么这是他们指向的地址依旧会像浅拷贝那样。
8. 代码块https://blog.youkuaiyun.com/hspingcc/article/details/54893853
代码块分为四种:
普通代码块function...{}、静态代码块static{}、
同步代码快synchronize{}、构造代码块{}
编译器会把构造代码块插入到每个构造函数的前端
构造代码块可以用来:
1.初始化实例变量
2.初始化实例环境
可以用来做对象计数器,特殊点:当一个构造函数调用另一个构造函数的时候,构造代码块不会插入。

















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









