



面向半自动驾驶辅助系统的模块化框架
1 引言
联合国各国元首于2015年通过了一项可持续发展目标(SDG),旨在到2020年将全球道路交通事故造成的死亡和受伤人数减少50%。道路交通事故是全球主要的死因之一,道路交通事故也是15至29岁人群的主要死因[1]。尽管全球人口和机动车数量自2007年以来持续增长,但由道路交通事故导致的死亡人数(每年约125万人)却一直保持不变。有充分证据表明,过去几年在全球范围内实施的改善道路安全的措施,如汽车安全系统和道路安全意识宣传活动,对此起到了关键作用。然而,剩余的交通事故仍然对全球经济造成巨大影响。
汽车安全系统 broadly 可分为被动式和主动式。当前的汽车被动式安全系统包括安全气囊或安全带,有助于减轻事故发生时造成的伤害严重程度,但无法降低发生事故的概率。相比之下,主动式系统(如自动制动系统或动态巡航控制)可直接防止或减少事故发生[2]。
本研究聚焦于一种称为主动式驾驶员辅助系统(DAS)的系统。该系统旨在通过提供自动化或自适应驾驶功能的技术,帮助驾驶员实现更安全、更舒适的驾驶体验。根据汽车工程师学会(SAE)1,车辆自主性分为六个等级:
- Level 0: no automation 人类驾驶员始终完全控制车辆并执行所有驾驶功能。
- Level 1: driver assistance 人类驾驶员拥有完全控制权,但车辆可为一个或多个驾驶功能提供辅助,例如电子稳定控制或辅助制动。
- Level 2: partial automation 人类驾驶员对车辆具有主要控制权,但车辆能够对多种驾驶模式实现完全控制,例如转向和加速/制动的组合。
- Level 3: conditional automation 自动驾驶系统具有主要控制权,并在某些条件下执行所有驾驶功能。在许多驾驶模式下需要人类驾驶员干预。
- Level 4: high automation 自动驾驶系统对车辆拥有几乎完全的控制权。仅在某些驾驶模式下需要人类驾驶员干预。
- Level 5: full automation 自动驾驶系统对车辆拥有完全控制权。无需任何人类驾驶员干预。
目标是开发一种具有模块化架构的解决方案,可轻松安装到自主等级为0或1的汽车中,从而将这些汽车升级至自主等级2。
摄像头通常是智能汽车主要的外向传感器的良好选择。这是因为摄像头能够提供大量信息和宽广视野。这些信息通常对于实现快速响应和精确驾驶非常理想,因为它为汽车提供了在现实世界中自主导航和运行所需的情境感知能力。尽管摄像头无法像深度传感器(如测距激光器)那样确定汽车周围场景的几何形状,但已有充分证据表明,通过适当的处理,摄像头可用于精确估计运动,并恢复场景中的详细三维几何信息[3]。它们所提供的详细光度信息,几乎无限地提升了应对密集体素重建和物体识别等问题的潜力。
如今,由于摄像头、支持电子设备和处理卡的成本和尺寸的降低,可以开发出功能强大且低成本的计算机视觉系统。作为概念验证,已开发出一种模块化解决方案,该方案采用立体相机作为唯一传感器,旨在开发一种低成本驾驶辅助系统,该系统可由技术知识较少的人群进行安装和使用。
机器学习(即深度学习)的应用在旨在从数据中获取知识的领域中变得越来越重要。在汽车领域,它极大地推动了辅助系统以及智能交通系统的发展。本研究表明,将机器学习与计算机视觉嵌入低成本处理卡中,可成功用于设计具有优异效果的模块化驾驶辅助系统(DAS)。
交互式设计的目标是创造使用户能够以最佳方式实现目标的产品。通过并行而非串行地执行开发阶段的新框架的设计和商业化,可以实现这一目标,从而减少该过程所需的时间和成本。本研究提出的框架的开发使得能够创建驾驶辅助的模块化系统。这允许使我们能够使用汽车获取数据并进行半自动驾驶系统的测试,从而以交互式和模块化方式缩短系统的获取和测试时间。
在下一节中,将回顾最先进的技术以介绍本研究中使用的框架。在第3节中,简要概述了支持我们框架的理论。在第4节中,进一步详细解释了所提出的框架。在第5节中,展示了系统取得的结果。最后,在第6和第7节中讨论了结论与未来工作。
2 现有技术现状
2.1 相关架构
目前,越来越多的自动驾驶系统和高级驾驶辅助系统(ADAS)正在被开发。因此,为这些系统开发并标准化某些架构和框架显得尤为重要。这些架构基于三个主要概念:汽车、机器人技术(智能控制和视觉)以及嵌入式系统。通过结合这些概念,形成了一个有趣且重要的研究领域,称为自主嵌入式系统[4]。
一些研究工作致力于开发模块化系统和车辆仿真平台[5],旨在通过驾驶场景模拟来测试这些系统。此外,还开展了研究以提高半自动驾驶车辆中的安全性和驾驶理解[6]。在此过程中,通过考虑驾驶员的态度和安全性,对半自动驾驶车辆所采取的动作进行了研究和探索。此外,还开发了车辆的故障诊断系统[7],旨在通过使用机器学习算法防止某些对乘员构成危险的情况,从而提高安全性。
在几项研究中,开发自动驾驶架构或高级驾驶辅助系统(ADAS)主要有三个阶段:感知、认知和决策[8–10]。这三个阶段都至关重要,构成了工作的基础。
在汽车领域,电子系统的开发带来了新的挑战、新的机遇以及某些开放式架构的标准化,例如汽车开放系统架构(AUTOSAR)[11]。这类架构为我们提供了设计汽车系统的方法论,类似于前述系统[12]。
同样,硬件的发展也以实现上述三个阶段为目标;例如,英伟达 DrivePX[13]能够连接多种类型的多传感器,并通过高度可并行化的嵌入式解决方案提供开发自动驾驶系统所需的软件工具。
2.2 计算机视觉和机器学习
利用计算机视觉辅助道路驾驶员的可能性非常广泛,主要针对解决特定任务。由于可能获取的信息量巨大,交通场景的分析极为复杂。例如,光照和尺度变化、运动物体与遮挡物体以及车辆运动是必须解决的一些主要问题。目前,计算机视觉可以实现多种任务,包括盲区定位辅助[14],驾驶员意识测量[15],以及车辆/行人检测车辆[16]。
在将这些解决方案应用于测试车辆并用于实时应用之前,必须提高其性能和准确性。由于新型深度学习设备和更快速处理卡的发展,与视觉感知和学习相关的新解决方案的效果相比以往方法已得到提升[17,18]。
车辆检测一直是模式识别和计算机视觉领域的主动研究方向。为了获得更优的分类器,已尝试多种方法。例如,类Haar特征检测和光流方法分别被用于检测相对于测试车辆同向和逆向行驶的车辆[19]。然而,这些方法的有效性受限于检测器产生的误报数量,需要借助几何约束和滤波技术来剔除误报。其他在场景中寻找车辆的方法则利用角点[20]或水平和垂直边缘的组合[21,22]等几何特性。
立体视觉也是一种非常有用的方法,它利用摄像头的内参和外参来获取每个图像像素点上的深度信息的三维地图。例如,在[23]中,没有使用完整的三维地图,而是仅计算了一组稀疏特征集,并将其分类为垂直、水平或角边缘;这些特征随后被用于检测车辆前方的障碍物。道路和物体通过一些几何约束进行分割。其他技术通过计算光流[24]来利用连续图像之间的运动。行驶方向相反的车辆所产生的发散流可以很容易地被识别出来,从而与当前车辆产生的流区分开来。
最近的方法利用深度学习来改进车辆及其周围环境的分割和分类。深度学习为复杂问题提供了解决方案,其中可以通过获取大量数据来在所有可能场景中训练网络。然而,深度学习是计算密集型的。这可以通过使用新的图形卡来克服,这些图形卡是

在使用最先进的开源库时易于实现[17,18]。
如前所述,自动驾驶要求识别与分类过程具有高精度并能够实时执行。例如,在[25]中采用滑动窗口方法,通过使用图像、激光雷达、雷达和GPS传感器数据训练网络来检测车道边界和车辆。研究表明,在车辆前后两个行驶方向上,最远可达5060米的实时检测效果优异。在另一项研究[26]中,通过在深度网络架构中使用图像块和空间先验信息实现了城市场景的语义分割。该研究提出的方法在道路检测和城市场景物体理解方面达到了先进水平;然而,预测阶段需要约30秒的时间来推断每个位置的标签。
3 提出的方法
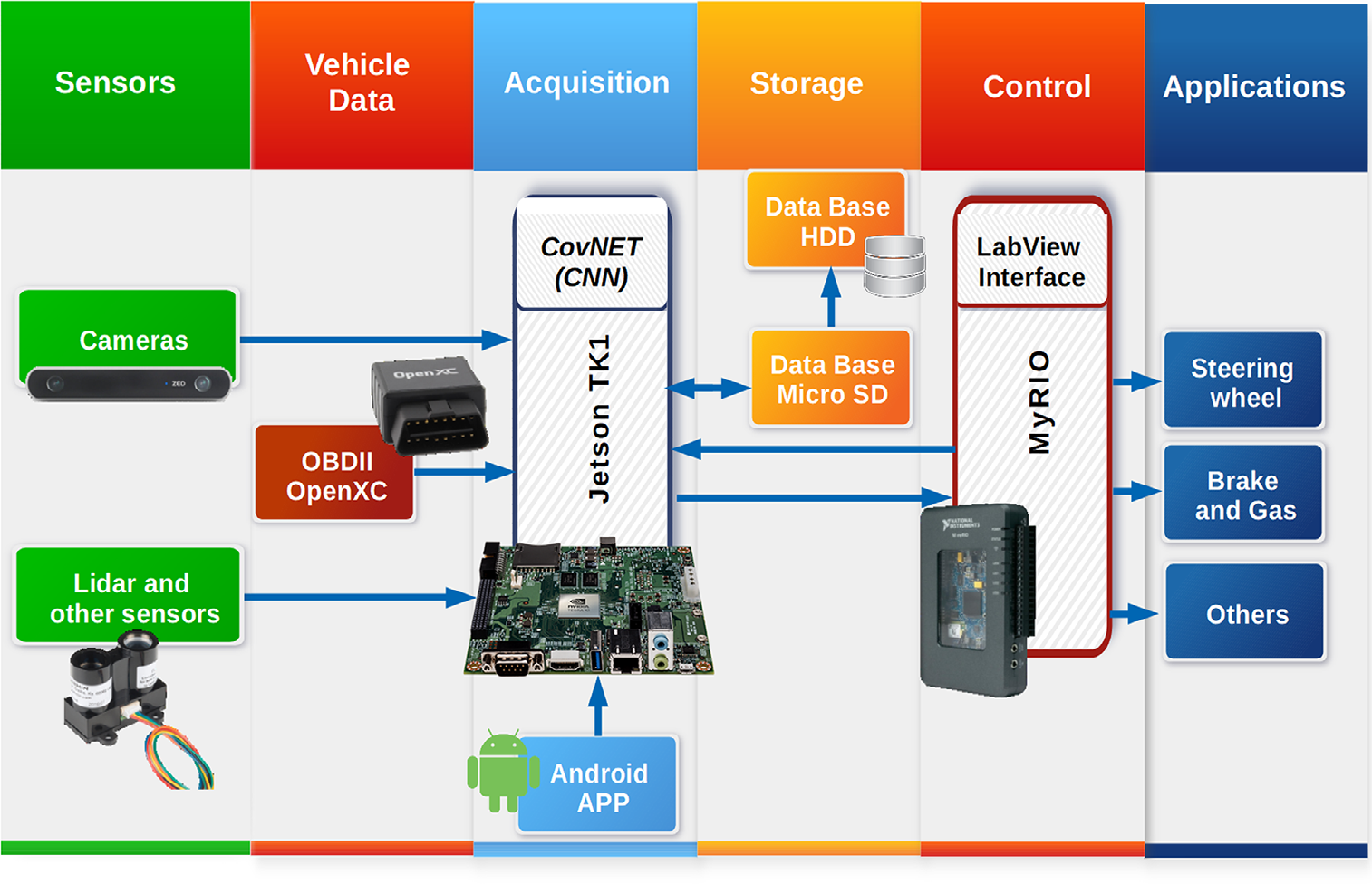
所提出的框架的总体架构由不同模块集成(图1)。这些模块将在以下部分进一步说明。
3.1 传感器与数据采集
在我们提出的解决方案中,需要使用不同的传感器来测量某些环境变量。用于所提出架构的传感器将在以下小节中给出。
3.1.1 传感器
– 立体摄像头:通过分析镜头之间的视差来获取距离数据。
– 控制器局域网(CAN)总线读取器:为了从车辆中获取数据,需要与CAN总线通信,例如通过OBD II接口。一些设备可以连接到此端口并获取变量,如车速、方向盘转角、加速度、制动或活动状态。
– 激光雷达或雷达:通过使用激光或电磁场来获取到附近可能存在的物体的距离。它们通常非常精确,但成本也很高。
– 定向摄像头:这些摄像头在停车情况下进行机动操作时非常有用,并可提供环境感知能力。
– 加速度计和陀螺仪:用于获取车辆的倾角和加速度力,以限制某些动态操作。
3.1.2 数据采集
我们的方法首先获取一个名为自主立体驾驶学习数据的数据库,该数据库通过使用不同的传感器捕获数据(见图1)。这些数据是必需的,并且需要同步,以便为监督学习算法在驾驶过程中预测特定参数的应用提供支持。
采集的数据包括前向立体图像(含图像视差)、车速、方向盘转角、加速度、制动操作、雷达和激光雷达的深度矩阵、360度视觉图像、车辆在XYZ轴上的测量角度以及运动瞬态值。
3.2 训练阶段和实现
我们数据库的开发使得能够利用当前最先进的机器学习技术,特别是卷积神经网络(CNN),实现并优化不同的高级驾驶辅助系统(ADAS),这些技术将在本研究中用于展示一个成功的应用:
- 转向角度预测和车轮控制:设计一种智能算法,用于在车辆跟踪场景中估算理想的转向盘角度。
- 速度预测和踏板控制:设计一种智能算法,利用与目标车辆的距离来估算车辆的理想车速,并将该结果作为输出,用于自动控制油门和刹车踏板。
- 带语音提示的泊车辅助:利用360度视觉和语音警报的动态泊车辅助系统,引导驾驶员完成优化泊车轨迹规划。
- 带警报的坑洞检测:用于检测道路坑洞的智能视觉辅助系统。
4 拟议应用与开发
如前所述,我们框架的开发和实施阶段将在接下来的部分中进行说明。
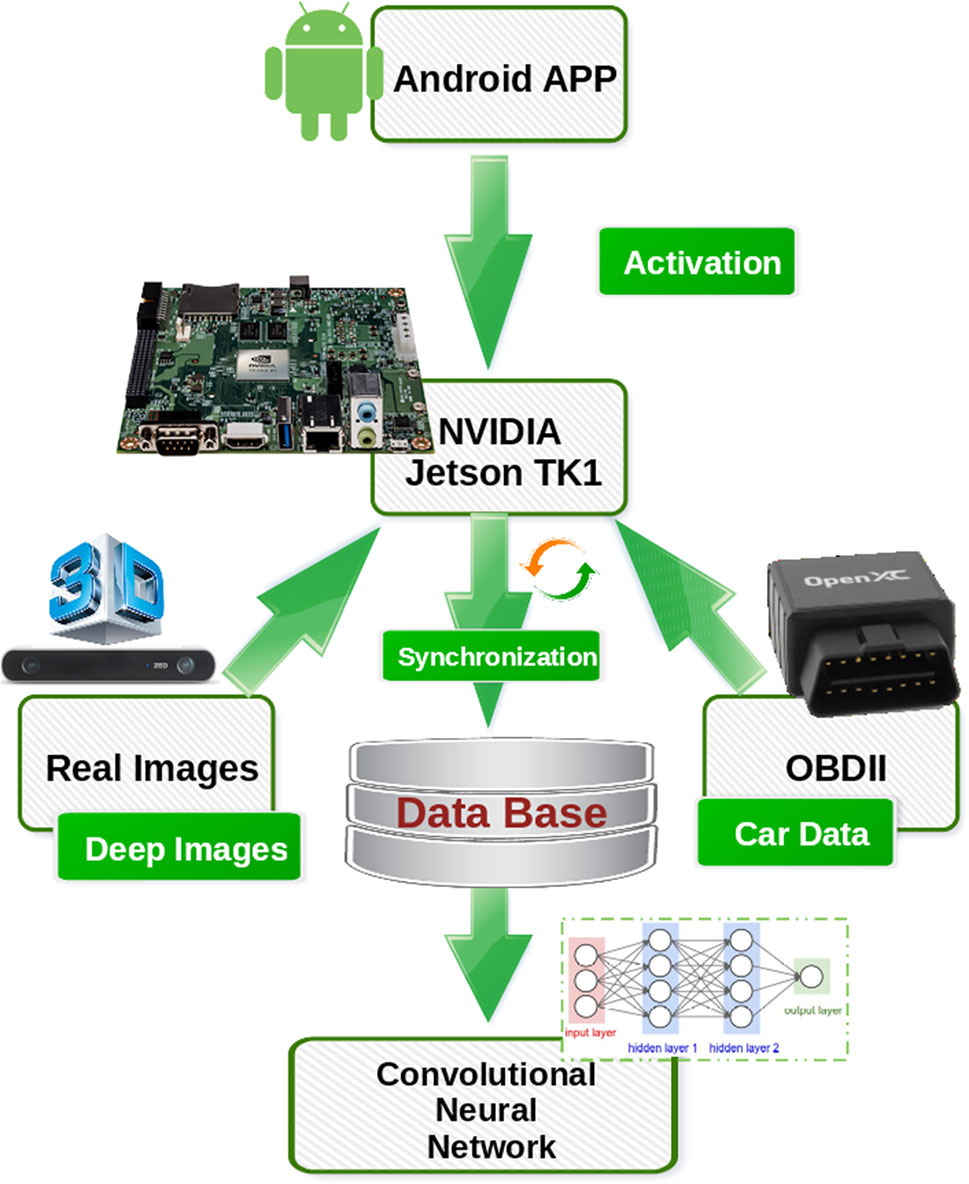
4.1 Jetson数据采集
设计了一个模块化采集系统(图2)。该系统捕获上述数据的同步样本。

上文所述。系统采集通过Jetson TK1板卡作为处理系统实现,其中ZED相机、OPENXC和蓝牙模块通过移动应用接收激活指令。
4.1.1 图像采集
通过ZED相机以VGA分辨率(640×480像素)进行图像采集,用于实时深度和深度图像,帧率为15帧每秒。该相机能够根据最远20米的距离计算深度。
4.1.2 CAN总线数据
使用OPENXC平台并通过Python库读取OBD端口及其数据。从端口获取的数据包括方向盘转角、车速、油门状态和刹车状态(图3)。
4.1.3 移动应用操作
为Android设计了一个移动应用程序,用于操控数据采集过程、启动系统以及选择需要同步和采集的数据。通过向Jetson TK1发送蓝牙信号来启动该过程。
4.1.4 同步
使用频率因子来同步OBD数据和图像。在某些情况下,对部分数据进行了插值处理,以使样本数量与图像数量相同。
本工作旨在改进并扩充数据库(立体深度驾驶数据)中的图像数量,该数据库将包含真实图像和与OBD数据(如方向盘转角、车速、油门踏板动作和制动)相关联的深度图像。
4.2 立体车辆跟踪数据(SCTD)
为了测试该方案,使用了15段时长为5到7分钟的VGA分辨率视频,以确定这些图像与真实视频(RGB)之间的视差。
经过处理,从不同城市交通环境中拍摄的15个视频中获得了105,556张图像。这些样本随后被用于训练车辆检测算法和路径规划算法。为了在跟踪过程中提取车辆运动并有效检测城市交通环境中的车辆,有必要收集大量图像以生成足够的样本。这些图像的一些示例如图4所示。
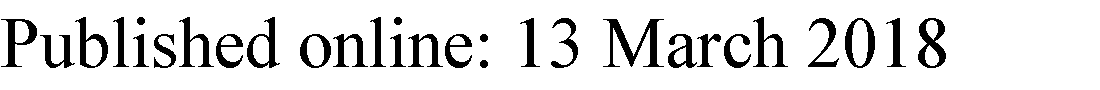
4.3 方向盘仪表化
方向盘仪表系统在福特福克斯上进行安装,以作为执行器并执行自动驾驶转向控制测试。
该机械系统的设计是由于车辆采用液压转向系统,无法通过CAN通信进行电子修改。该系统通过步进电机、齿轮系统和金属方向盘设计而成,金属方向盘通过齿轮在整个系统中耦合连接。
该系统主要由一个金属方向盘组成,该金属方向盘通过一个居中的齿轮连接到原始方向盘上,并通过链条连接到安装在副驾驶座位前方底座上的步进电机(图5)。该设计旨在即使遇到最大阻力时(例如发动机开启且汽车静止时)也能驱动方向盘转动。
在我们的案例中,结果为2.35 牛·米。因此,购买了步进电机以满足这一要求,确保该功能能够在更大的阻力下正常运行。
需要注意的是,该系统仅是一个原型,且由于不符合车辆系统的安全标准,只能用于研究目的。此外,它会屏蔽安全气囊,因此该系统仅在受控的交通状况下使用。然而,所提出的系统可以进行修改,以通过输出信号来控制电子助力转向或其他任何安全系统。
4.4 转向角度预测
获得的数据库被用来训练一个卷积神经网络(CNN),以估计车辆方向的角度。在获取数据库后,车辆数据和图像仍在持续处理,以扩展系统的训练。
假设一种机器学习算法能够模仿人类能力,将图像上下文解释为用于车辆追踪的方向盘运动。
所开发的算法基于英伟达端到端学习自动驾驶汽车方法[27]以及TensorFlow自动驾驶实现[28]。该系统的主要结构是一个卷积神经网络(CNN),可配置以调整训练参数,并根据应用需求改进结果。
该实现的基础被采用并针对我们的输入参数进行了调整。从文献中获得的卷积神经网络(CNN)架构被使用[27]并复制以比较神经网络在真实图像与深度图像下的效率。该架构如图6所示。还采用了一些方法来生成训练损失和输出数据的注册表,并对上述结果进行比较。
训练在Ubuntu系统上使用GPU支持的 TensorFlow 1.2完成,硬件配置为Nvidia 860M显卡和 CUDA 8。对105,556张图像的训练时间,实际图像为7小时45分钟,深度图像为6小时32分钟。在这两类图像中,均保留了3个RGB通道,因此神经网络的输入数组相同。
训练共进行了50个训练轮次,以获得尽可能小的损失值。


5 结果
5.1 转向角预测训练损失
训练后,绘制了真实图像和深度图像的训练损失值(图7)。图7显示,深度图像的数据损失值下降速度比真实图像更快。因此,深度图像的学习速度比真实图像更快。深度图像的损失值为0.004919,真实图像的损失值为0.006252。因此,深度图像的损失值低于真实图像。
5.2 转向角预测
系统训练完成后,使用验证视频来预测方向盘转角并验证系统精度。
这些数据与通过OBD端口获得的值一起绘制,以进行比较并获取其误差(图8,9)。
5.3 转向角度预测误差
为了计算卷积神经网络(CNN)相对于通过OBD端口获得的角度所产生的百分比误差,需进行校准。
平均绝对百分比误差(MAPE)的计算由以下方程得出:
$$
\text{MAPE} = \frac{1}{n} \sum_{t=1}^{n} \frac{|A_t - P_t|}{|A_t|}
$$
其中:
– $ n $ = 数据长度
– $ A_t $ = 实际值(通过OBD 端口获取)
– $ P_t $ = 预测值(通过卷积神经网络(CNN)获取)
使用迄今为止获取的15个视频的RGB和深度图像计算了MAPE。这样做是为了确定系统在这两种情况下效率的差异。此信息的汇总见表1。
5.4 研究结果
–
训练期间更低的损失
:深度图像的损失值比真实图像更低,该值在理论上越接近0,表示对训练数据的学习效果越好。然而,前述研究仅考虑了基于真实图像的学习训练。
–
更少的处理时间
:通过比较两种类型图像的训练时间,我们发现使用深度图像时训练时间更短(几乎缩短了1小时)。这可归因于卷积神经网络(CNN)在训练过程中处理深度图像数据更为容易。
–
更低的平均误差
:平均误差表显示,深度图像产生的平均误差更低,这可能表明使用针对此类图像训练的卷积神经网络(CNN)所获得的预测具有更高的可靠性。
–
良好的转向预测回归
:图8和图9展示了真实图像和深度图像中车辆方向数据与训练后的卷积神经网络(CNN)预测结果的对比。这些图显示了方向盘动作的预测精度,在两种情况下都很好,但深度图像的预测更为准确。
5.5 交互式工程结论
本研究中提出的框架的开发使得能够创建用于驾驶辅助的模块化系统。这使我们能够使用汽车采集数据并进行测试用于半自动驾驶,从而以交互式和模块化方式减少系统的数据采集和测试时间。
此外,通过以交互方式使用用于车辆转向的机电系统,这些系统还允许用户以特定方式测试不同的人工智能算法,从而验证其相对于先前进行的仿真的有效性。
提出的框架在测试系统中存在的局限性体现在智能算法预测后机械控制系统的响应速度上;同时,在执行学习算法训练时,训练时间将取决于采集数据量、网络架构以及其他因素。
交互式工程有助于推进这些系统的原型设计,开展以用户为主要参与者的测试,用于辅助系统开发。如今,人工智能已成为这些系统中最重要的工具之一。
6 结论与未来工作
我们的假设是,机器学习算法可以模仿人类处理过程来解释图像上下文,并将其转化为实际的方向盘运动以跟随前车。
作为概念验证,已开发出一种硬件和软件解决方案,通过使用立体相机作为唯一传感器实现方向盘的自主激活,考虑到用于数据采集和数据处理的摄像头和电子电路板的成本和尺寸正在不断降低。
所提出的框架的总体架构包含不同模块。我们的方法首先获取一个名为自主立体驾驶学习数据的数据库,该数据库记录了通过使用不同传感器收集的数据。该数据库用于支持相关应用,其中利用监督学习算法在车辆驾驶过程中预测特定参数。
我们数据库的开发将允许使用当前最先进的机器学习技术(特别是卷积神经网络(CNN))来实现和优化不同的高级驾驶辅助系统(ADAS),该技术在后续研究中被用于成功演示高级驾驶辅助系统的应用。
设计了一个模块化采集系统,用于获取上述数据的同步样本。在福特福克斯上构建了方向盘系统的仪器装置,作为执行器以进行自主转向控制测试。
上述系统的开发能够实现用于半自动驾驶的交互式模块化系统传导,通过交互式和模块化方法减少了采集时间和系统测试。如今,由于交通事故发生率较高,车辆辅助系统的开发变得愈发必要。系统成本下降和计算能力提升使得该技术更加普及。通过半自动驾驶系统提高驾驶安全是提升汽车安全的第一步。因此,研究表明,此类系统可用于普通城市环境(如交通拥堵)中,当车辆以低速跟随前方车辆行驶时的情况。
有必要进一步测试方向盘仪表系统的控制系统。尽管设计已经完成且仿真误差率较低,但仍需通过仪表系统进行实际测试,以验证我们的设计与其他自动化机制结合时的半自主转向质量。


















 4676
4676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









