



基于多种技术的鲁棒用户监测系统
I. 引言
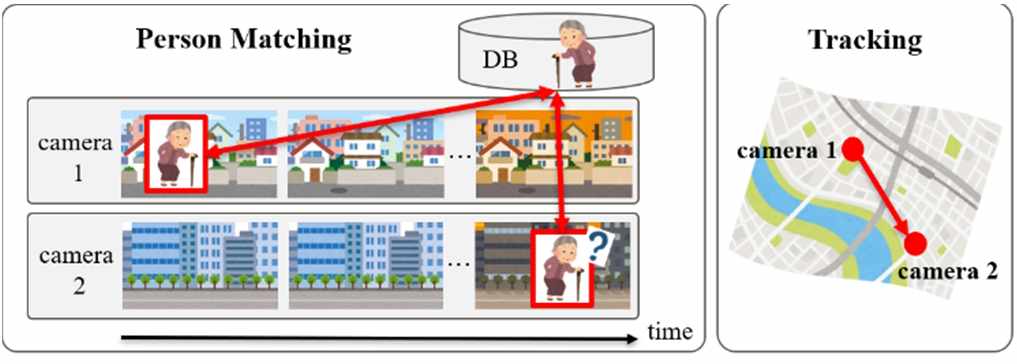
日本已成为全球老龄化最严重的国家之一,因痴呆而走失的老年人数量逐年增加。为了实现早期发现,已有系统通过让老年人携带智能手机等设备来采集位置信息 [1],但这些设备并不总是随身携带。因此,人们开始考虑一种通过监控摄像头图像进行人员匹配和追踪的机制。
在利用监控摄像头的图像中实现人员匹配时,可根据图像时间戳,结合摄像头的位置和时间信息追踪目标人员的行进路径。
有使用面部信息作为人员匹配技术的方法,但许多国家已经开始避免出于隐私的考量使用此类信息。近年来,利用步态信息[2]和耳部信息[3]的方法受到关注,该方法能在实现隐私保护的同时进行身份识别。
这些方法特别适用于寻找走失的老年人,因为在该应用场景下,老年人无需主动配合即可实现非接触式匹配。
在使用步态信息的匹配技术中,如果图像能够完整捕捉到人体全身,便可实现高准确率的匹配。但在实际监控摄像头拍摄的图像中,由于脚部经常被遮挡,该方法会出现准确率下降的情况。此外,由于耳部图像区域比步态图像区域小,且图像质量容易变化,可能导致匹配失败。
因此,亟需开发一种即使在发生环境变化和图像质量下降的情况下仍能实现高准确率的匹配技术。
本文提出了一种方法,通过仅使用模拟监控摄像头遮挡情况下的上半身图像中的步态和耳部等多种信息,能够比传统方法更准确地进行人员匹配。此外,我们展示了利用不同日期拍摄的老年人步态图像进行评估的结果。
II. 人员匹配方法
A. 使用步态信息的传统方法
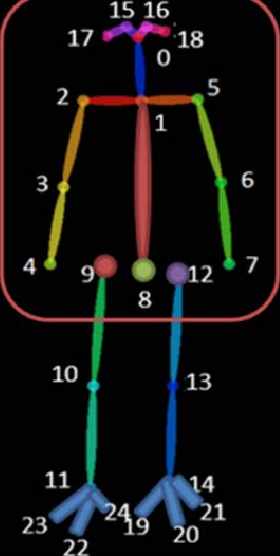
近藤等人[2]的研究提出了基于通过OpenPose估计的时间序列步态姿态,提取全身部位的步态特征,并在特征空间中找出了172维特征。
本文中,如图2所示,利用步态姿态中的上半身部分,提取了72维特征,包括肩部高度、肘部高度、手部摆动和胸部高度。在这些初始特征中,通过特征选择找出了51维特征。

B. 使用耳部信息的传统方法
利用耳部信息的方法在隐私保护和耳部形态即使在老化过程中变化较小这两方面被认为非常有用。目前已有基于手工特征和基于深度卷积神经网络(CNN)的研究。
在本文中,我们使用Handley等人提出的基于CNN的特征提取模型,在利用相关性矩阵进行归一化后,获得了512维特征。
C. 提出的方法
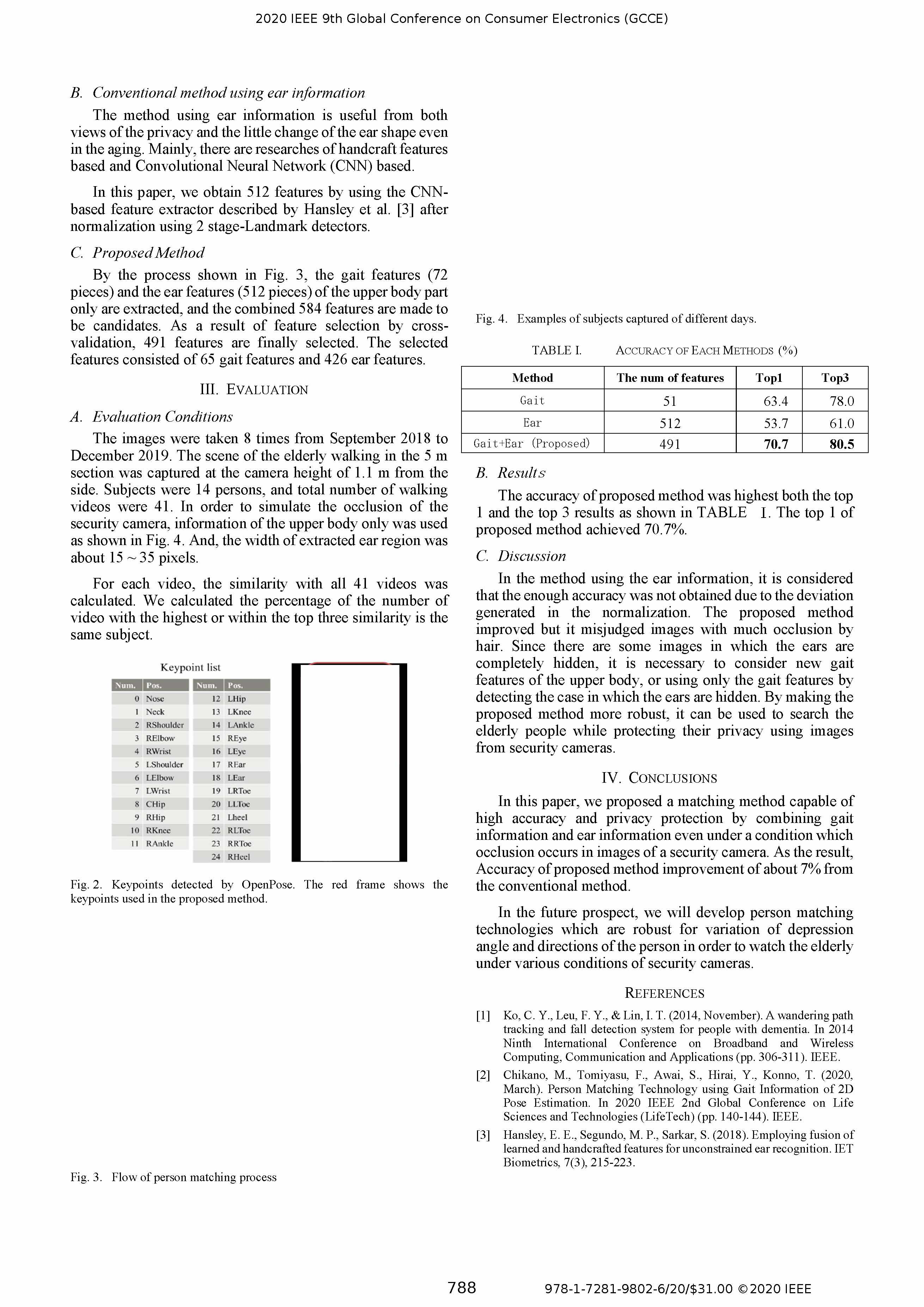
通过图3所示的流程,仅提取上半身部分的步态特征(72维)和耳部特征(512维),并将组合的584维特征作为初始特征。经过验证的特征选择后,最终选出了491维特征。所选特征包含197维步态特征和294维耳部特征。
III. 评估
A. 评估条件
图像采集时间为2018年9月至2019年12月,共进行了8次。老年人在5米长的走廊内行走的过程,由前方1.1米高度的摄像机进行拍摄。每次实验共有15名受试者,行走次数总计为415次。为了模拟实际摄像头的遮挡,仅使用了上半身信息,如图4所示。提取的耳部区域高度设定为15~35像素。
对于每一次行走,计算其与其余415次行走之间的相似度。我们统计了具有最高相似度的匹配结果中属于同一受试者的比例。
| 关键点编号 | 关节名称 | 关键点编号 | 关节名称 |
|---|---|---|---|
| 0 | 鼻子 | 12 | 左肩 |
| 1 | 颈部 | 13 | 右肩 |
| 2 | 右肩 | 14 | 右肘 |
| 3 | 右肘 | 15 | 右腕 |
| 4 | 右腕 | 16 | 左腕 |
| 5 | 左肩 | 17 | 左肘 |
| 6 | 左肘 | 18 | 左耳 |
| 7 | 左腕 | 19 | 右脚踝 |
| 8 | 胸部 | 20 | 左脚踝 |
| 9 | 腰部中心 | 21 | 右脚趾 |
| 10 | 腰部左侧 | 22 | 左脚趾 |
| 11 | 腰部右侧 | 23 | 右脚跟 |
| 24 | 左脚跟 |
B. 结果
如表I所示,本文提出的方法在Top-1和Top-3结果中的准确率均达到最高。本文提出的方法的Top-1准确率达到70.7%。
| 方法 | 特征数量 | Top-1准确率 (%) | Top-3准确率 (%) |
|---|---|---|---|
| 步态(传统方法) | 51 | 63.4 | 78.0 |
| 耳部(传统方法) | 512 | 53.7 | 61.0 |
| 步态+耳部(本文提出) | 491 | 70.7 | 80.5 |
C. 讨论
在使用耳部信息的方法中,由于归一化过程中发生的变形,导致准确率不高。本文提出的方法虽有所改进,但在头发遮挡较多的图像中仍出现误匹配。由于当耳部完全被遮挡时,仅依赖上半身步态特征可能不足以准确识别,未来可考虑在检测到耳部被遮挡的情况下动态切换至仅使用步态特征的模式。通过使本文提出的方法更加鲁棒,可利用监控摄像头的图像在保护隐私的同时有效实现对老年人的监护。
IV. 结论
本文提出了一种结合步态信息和耳部信息的匹配方法,即使在监控摄像头图像发生遮挡的情况下,也能实现高准确率和隐私保护。结果表明,该方法的准确率比传统方法提高了约7%。
在未来工作中,我们将开发对光照变化和人员朝向具有鲁棒性的人员匹配技术,以便在各种监控摄像头环境下实现对老年人的有效监护。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









