



云、雾和边缘计算基础设施的能耗估计
摘要
为了改善局部性,已提出诸如边缘计算等新的与云相关的架构。尽管这些新架构日益流行,但其能耗尚未得到充分研究。为推进这一关键问题的研究,我们首先引入了不同与云相关的架构的分类法。基于该分类法,我们提出了一种评估其能耗的能源模型。与以往的方案不同,我们的模型涵盖了计算设施的全部能耗,包括冷却系统,以及连接最终用户与云资源的网络设备的能耗。最后,我们将模型应用于从完全集中式到完全分布式的一系列与云相关的架构,并比较它们的能耗。结果表明,由于不使用数据中心内部网络和大规模冷却系统,完全分布式架构分别比完全集中式和部分分布式架构节能14%至25%。据我们所知,本工作是首个提出能够使研究人员分析和比较不同与云相关的架构能耗模型的研究。
索引术语 —云计算, 能耗, 分布式云, 雾计算, 边缘计算, P2P。
I. 引言
云计算解决方案的能耗已成为我们现代计算设施面临的挑战之一。数据中心(DCs)是云计算中消耗能源的主要组成部分。根据劳伦斯伯克利国家实验室(LBNL)发布的报告,在2016[1],,数据中心消耗了估计700亿千瓦时(约占美国总用电量的1.8%)的电能,预计到2020年,美国的数据中心将消耗约730亿千瓦时的电能。
与此同时,与物联网(IoT)相关的新应用不断涌现,这要求更加分布式的云相关架构,依赖于部署在网络内部及边缘的资源。这些新兴的虚拟化架构被称为雾、边缘,有时也称为P2P计算基础设施[2],[3],,旨在满足基于物联网的应用对低延迟和高带宽的需求。尽管这类基础设施是否会被部署已无争议,但其能耗影响尚未得到研究。
本文的主要目标是提出一种通用能耗模型,以准确评估和比较能耗。与云相关的架构的前沿目前正在不断发展,我们首先介绍了现有定义以及每种架构的关键特征。然后,我们建议将它们各自确定为一种明确定义的架构,范围从集中式到完全分布式架构。为此,我们提出了一种分类法,根据特性对现有的与云相关的架构进行分类,并对各基础设施的硬件元素进行归类。基于所提出的分类法,本文提出了一个能源模型。由于该模型准确地考虑了不同架构之间的差异,因此可用于估算特定架构的能耗,以及对它们进行比较。
我们的主要贡献在于:
(i)建立一个涵盖技术特性、服务和用户满意度的与云相关的架构及组件的分类法,以全面覆盖该领域。我们提出的分类法的主要目的是探索相似范式中不同架构和组件的独特特征,并为对现有和未来架构进行分类提供基础。
(ii)提出一种通用且准确的模型,用于估算现有云相关基础设施的能耗。该模型为深入分析和清晰理解当前云环境提供了基础。此外,这项工作还揭示了当前在该领域部署的底层技术。
本文的其余部分组织如下:第二节介绍了相关工作。第三节使用我们提出的分类法对云相关架构进行分类。第四节介绍了所提出的能源模型。第五节分析了不同架构的能耗。最后,第六节总结了我们的工作。
II. 相关工作
在本节中,我们首先介绍现有的云相关基础设施。然后,对最常用的云和数据中心模拟器的能耗模型进行比较。最后,介绍了针对不同与云相关的架构的能耗消耗比较的相关研究工作。
A. 虚拟化架构
云计算最近已转向更分布式的架构,以满足用户对移动性、大数据量处理和低延迟的需求。2014年,欧洲电信标准协会(ETSI)提出了一种名为移动边缘计算的新云架构[4]。
根据最初的定义,“移动边缘计算在无线接入网络(RAN)内为移动用户提供IT和云计算能力,位置上靠近移动用户”[4]。欧洲电信标准协会(ETSI)的移动边缘计算(MEC)小组于2016年更名为多接入边缘计算,以扩大其对异构网络的接入能力[5]。MEC基础设施通过分层或分布式控制进行管理,具体取决于所考虑的应用[5],[6]。当移动设备被用来为更小的设备提供计算能力时,它们也可以包含在MEC基础设施中[7]。
在物联网(IoT)不断扩展的推动下,思科于2012年提出了雾计算的概念[8]。根据开放雾联盟的定义,“雾计算是一种系统级横向架构,能够在从云到物的整个连续统一体上,任意位置分发计算、存储、控制与网络的资源和服务”[9]。特别是,该架构旨在应对由网络边缘的物联网设备产生的时间敏感型和大量数据[10]。为此,雾计算可将云延伸至靠近物的任何具备计算、存储和网络连接能力的设备[8]。雾计算架构可视为具有三层的层次结构:物联网设备、雾节点和云数据中心[10]。根据应用的不同,雾节点可采用去中心化或分布式方式进行管理[10]。
从产业视角来看,这两种模型之间的差异尚不明确,一些举措(如Linux基金会发起的《边缘计算开放术语表》)旨在为这一主题提供准确的定义[11]。
B. 能耗模型和仿真工具
最近的研究[12],[13]表明,在过去十年中已提出了二十多种云和数据中心模拟器,其中CloudSim[14]是最受欢迎的之一。尽管它具有诸多优势(e.g.,大规模数据中心建模、联邦模型以及支持大量虚拟机),CloudSim仍存在若干局限性,包括通信与网络能耗模型的支持有限。
由于CloudSim具有可扩展性,已有大量工作[15]–[17]致力于对其功能进行扩充。其中少数研究聚焦于CloudSim的能源模型。例如,Li等人[17]提出了DartCSIM,以实现能耗与网络的联合仿真。此外还提出了其他云模拟器,如iCanCloud[18],但它们并未设计用于支持分布式数据中心架构[19]。Malik等人[19]提出了CloudNetSim++,这是一种基于图形用户界面的框架,用于在OMNeT++中对数据中心进行建模与仿真,包含网络设备的仿真模型。然而,该模拟器在其模型中未考虑数据包长度对能耗的影响。最后,SimGrid工具箱提出了对虚拟机的精确建模[20],以及服务器的能耗模型[21],但未提供网络组件的能耗模型。
尽管存在上述工具,但我们未能找到一种简单的模型或模拟器,能够轻松支持从完全集中式到完全分布式的不同与云相关的架构,而无需深入细节编程和扩展上述模拟器。例如,为了比较不同的与云相关的架构,我们需要考虑其控制节点的数量和位置,这将在本文后面进行讨论。最后,大多数现有的模拟器也无法提供架构组件的准确结果,或未考虑其空闲能耗部分。基于以上所有原因,我们设计了一个通用能耗模型来比较不同的与云相关的架构。
据我们所知,我们的工作是首个提出能够使研究人员分析(从而比较)不同与云相关的架构能耗的模型。尽管Jalali等人[22]比较了由集中式数据中心和雾计算提供的应用的能耗,但他们提出的能耗模型中有多个部分尚不够准确,无法回答与云相关架构的能耗足迹问题。Li等人[23]比较了由集中式云和边缘计算提供的物联网应用的能耗。C.菲安德里诺等人[24]也提出了用于评估和比较云计算数据中心通信系统能效的指标。在所有这些情况下[22]–[24],,所提出的模型对于准确分析各种与云相关的架构而言仍是不完整的。例如,由于未考虑集中式数据中心的规模和数据中心内网络拓扑,因此无法对数据中心内网络部分进行分析。此外,它们通常只关注特定应用或某类应用的影响[25]。
III. 提出的分类法
近年来,提出了许多与云相关的架构以满足用户和服务提供商的需求。将具有若干相似特征的架构归为同一类,可以显著简化我们的能源模型的呈现和设计。为此,我们提出了一种分类法,以适当地涵盖和分类这些架构。
A. 与云相关的架构
与云相关的架构包括一个或多个数据中心以及若干最终用户,所有这些组件通过电信网络相互连接。最终用户是请求的发送者和服务的接收者。数据中心向最终用户提供不同的云服务,由多个计算节点(CNs)和服务节点(SNs)组成,其中计算节点用于托管虚拟机(VMs),服务节点则作为基础设施管理节点或存储节点。与云相关架构之间的主要区别在于其数据中心的位置、数量、规模和角色(e.g.,控制器、存储、计算,或其中一部分)。
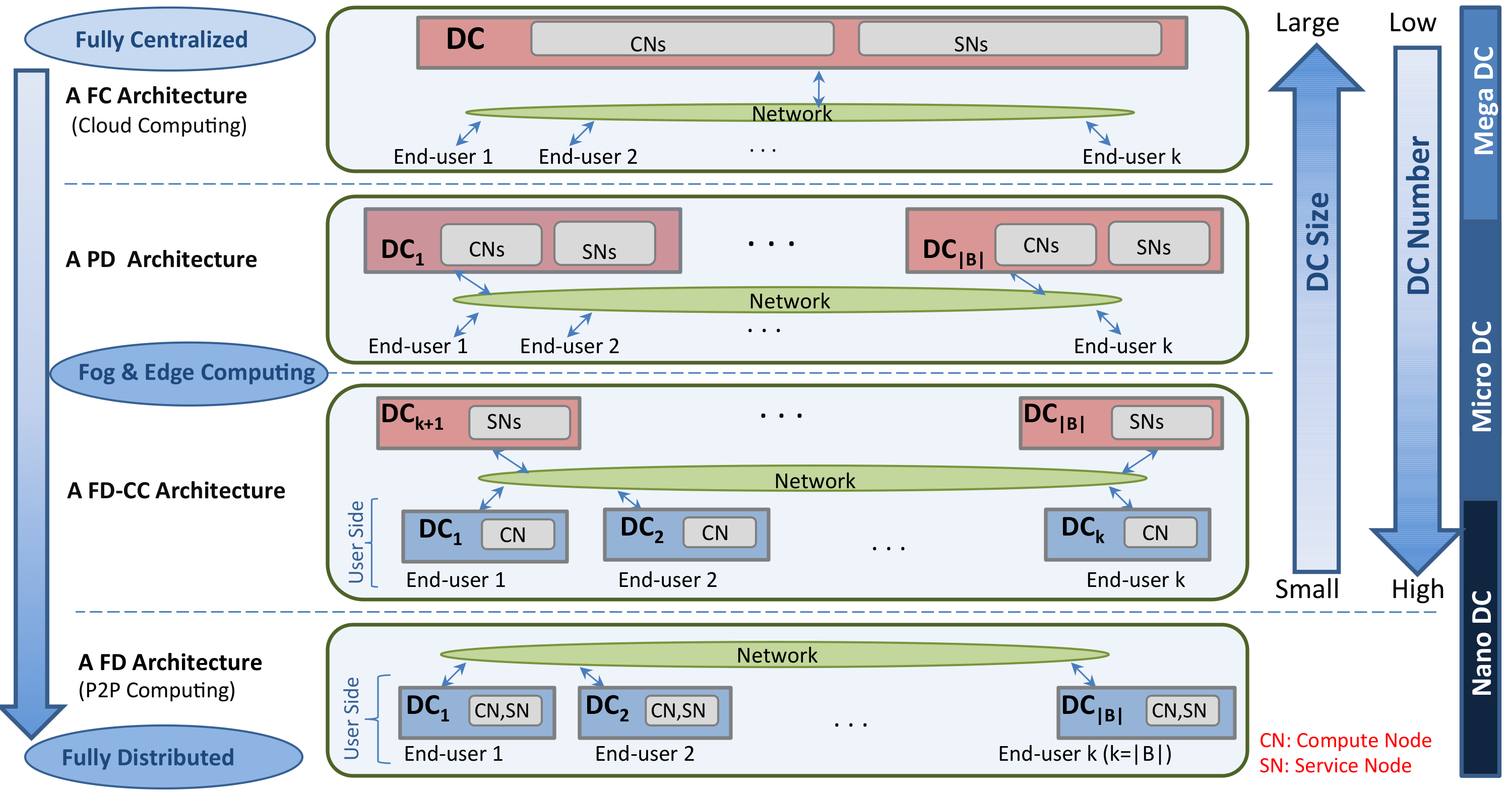
完全集中式(FC) – FC架构包含一个大型数据中心。所有最终用户都连接到该中心数据中心并从中获取服务。
部分分布式(PD) – 在PD架构中,多个数据中心分布在不同的位置并协同工作共同为最终用户提供服务。电信网络将云数据中心相互连接,同时也将最终用户连接到数据中心。在PD架构中,由于数据中心数量较多,数据中心通常比FC架构更靠近最终用户。然而,数据中心并未位于最终用户场所内。
具有集中式控制器的完全分布式(FD-CC)——FD-CC架构包含多个位于最终用户场所的DC(即,一个或少数几个最终用户对应一个DC)。然而,控制器(即,作为SNs)位于网络核心的一个或多个DC中。位于最终用户场所的DC通常规模为一台物理机(PM)。位于网络核心的其余DC仅用于管理方面,不用于计算和存储服务。
完全分布式(FD) – 在FD架构中,与FD-CC不同,管理系统也分布在最终用户的位置上。这意味着在网络核心中没有负责控制资源的数据中心(即,没有独立的服务节点)。
所采用的缩写汇总于表I。FC架构代表集中式云基础设施。PD架构的示例可在去中心化的雾基础设施中找到[10]。FD-CC架构汇集了具有分布式节点和去中心化管理节点的分层雾和边缘基础设施,用于承载例如虚拟网络功能(VNF)编排[5],[10]。最后,FD架构代表完全分布式的边缘基础设施[6]。需要注意的是,在本研究的背景下,我们未考虑各种无线网络技术[26]。将包含移动雾节点的架构纳入考虑范围被视为未来的工作。
表 I 缩略语列表
通用术语
| |
| —|
| DC数据中心 物理机,虚拟机分别为物理机和虚拟机 CN, SN分别为计算节点和服务节点 PUE电源使用效率 C, B, M, F分别为电信网络中的核心、骨干、城域和接入路由器 电信网络|
云架构
| |
| —|
| FC完全集中式架构 PD部分分布式架构 FD-CC具有集中式控制器的完全分布式架构 FD完全分布式架构|
B. 架构的组件
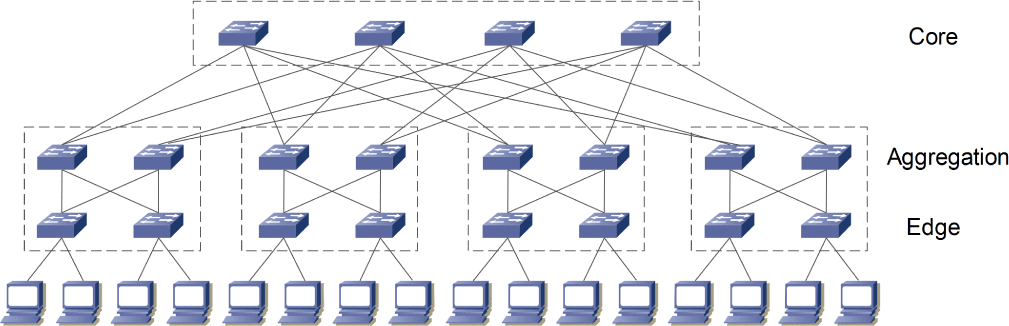
图2展示了所有与云相关的架构中信息与通信技术设备的全面概述。任何架构都包含两个主要部分:数据中心(DC)和电信网络,这两部分将在下文进行描述。
此外,数据中心可根据其规模进行分类:当托管的物理机数量超过10,000台时为大型,少于500台时为微型,而当数量为纳米级时则称为纳米级。仅包含少量物理机。在本例中,我们考虑一种极端情况,即一个纳米数据中心仅由一台物理机构成,且没有任何额外的信息与通信设备,例如数据中心内部的网络设备(i.e.,交换机和链路)。此外,值得注意的是,除纳米数据中心外,所有其他数据中心都配备有非信息通信设备,例如独立的冷却系统。为了反映数据中心中非信息通信设备(i.e.,从微型到大型)的能耗情况,电源使用效率(PUE)是一个广为人知的数据中心能效指标。它表示总设施能耗与IT设备能耗之间的比率[27]。换句话说,可通过将数据中心的信息与通信设备能耗与其PUE值相乘来估计该数据中心的总体能耗。
如图2所示,物理机可分为两大类:第一类物理机专用于计算用途(例如,计算和云管理节点)。第二类物理机由于具备特定的存储后端(即,存储节点),可用于存储大规模数据集。由于附加的存储设备,每种类型的物理机具有不同的能耗特征。在数据中心术语中,计算节点(CNs)对应第一类,而服务节点(SN)若用于管理基础设施则属于第一类,若用于存储用途则属于第二类。在FD架构的极端情况下,使用基于单个计算节点的物理机时,服务节点功能由直接运行在计算节点上的虚拟机提供,并使用本地磁盘作为默认存储后端。
除了物理机外,大型或微型数据中心的信息与通信设备还包括网络设备,如路由器、交换机和链路,用于连接物理机。数据中心内部用于连接物理机的网络设备的数量和类型由其网络拓扑决定。自2008年以来,已提出三十多种适用于数据中心的网络拓扑。在本研究中,我们考虑一种胖树交换机中心架构(即n元胖树拓扑),该架构对应于当前许多可用数据中心的网络拓扑。
使用小规模且相同的交换机被认为是胖树拓扑的一个显著优势。这使得通信架构中的所有交换机都可以采用廉价的商用部件。此外,与使用非相同交换机的架构相比,该拓扑简化了系统模型和分析。该拓扑具有灵活性和可扩展性,因此能够适应不同规模的数据中心。我们考虑一种具有三层(即核心、汇聚层和边缘)、(n/2)²台核心交换机以及n个机柜组(即每个机柜组包含两层,分别为n/2台汇聚层交换机和n/2台边缘交换机)[30]的n元胖树拓扑。该拓扑使用类似的n端口交换机,最多可支持n³/4台物理机。图3给出了一个n=4的示例。
最后,电信网络将所有数据中心和最终用户连接在一起。它通常包括四个主要逻辑层[31]:核心、骨干、城域和接入层(或最终用户)。城域层为最终用户提供网络接入。骨干层提供基于策略的连接。核心层提供高速传输,以满足骨干层设备的需求。对于FC架构,我们假设单个数据中心直接连接到电信网络的核心层。对于PD架构,数据中心连接到骨干路由器或城域路由器。对于FD-CC架构,包含CNs的数据中心连接到骨干路由器或城域路由器,而包含SNs的数据中心则连接到核心层。最后,对于FD架构,数据中心连接到接入层。我们假设路由策略始终采用最短路径。
四、能源模型
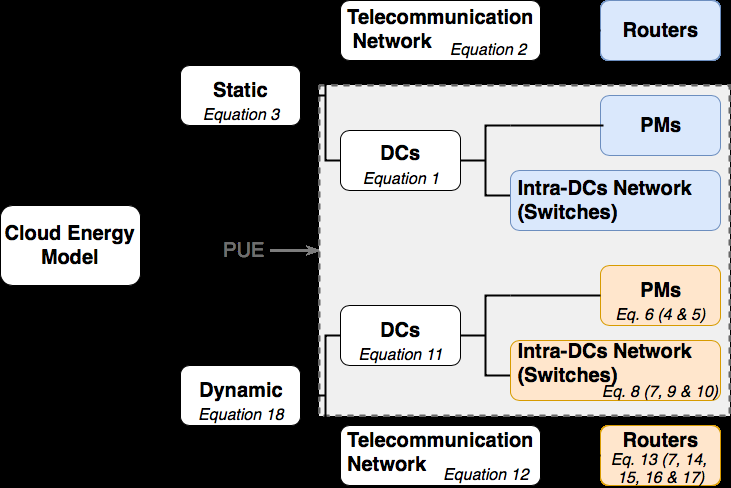
在本节中,我们介绍了为不同与云相关的架构定义的能源模型。我们考虑一种场景,即一组最终用户请求了V个活跃虚拟机。我们的目标是提供一个通用模型,以估计在给定时间段T内上述各云相关基础设施在已分配虚拟机运行时的能耗。需要强调的是,我们并未考虑这些架构在服务质量(i.e.,延迟)方面的差异。此外,仅估算基础设施本身的能耗:包括数据中心与用户之间的电信网络,但不包括最终用户的设备。为了估算某一架构的能耗,该模型接收一组列于表II中的输入参数及其定义。
A. 概述
如图4所示,我们的模型将信息与通信设备的能耗分为静态部分和动态部分[32]。静态能耗是指不考虑任何工作负载时的能耗(i.e.,资源空闲)。动态成本根据活跃虚拟机对云资源的当前使用情况计算得出。
表II 能量模型输入列表
通用输入
| |
| —|
| U终端用户数量 V虚拟机数量 T考虑的时间段(秒)|
计算输入
| |
| —|
| DC N数据中心 DC={DC1,…, DCN}的集合,包含 N 取决于所考虑的架构 pmi DCi中具有 i ∈{1,…, N}的物理机数量 P UEi DCi的电能使用效率 CNi位于 DCi的一组CNs SNi位于 DCi的SN集合(对于FD架构, SNi= ∅) P idle x物理机 x在空闲模式下的功耗,属于 DCi (单位为瓦特),其中 x ∈{CNi⋃ SNi} P cores x,j物理机动态功耗 x当其 j的 k 核心完全负载(以瓦特为单位)时, j ∈{0,…, k}和 P cores x ,0= 0 uSN每个服务节点的平均CPU利用率(用于服务和存储) 函数 uV M CNs上每个VM的平均CPU利用率 uH每台物理机的虚拟机管理程序的平均CPU利用率 CNs上的监控进程|
网络输入
| |
| —|
| L数据中心内网络上数据包的平均长度以及 电信网络(以字节为单位) λ属于数据中心的物理机产生的平均流量速率(单位:bps) q物理机发送给最终用户的数据包的平均比率 µ用户向数据中心产生的平均流量速率(单位:比特每秒) λSN FD-CC架构中从计算节点到存储节点的平均流量速率 (比特每秒) NEi每个具有 n个端口的属于 DCi的交换机集合 P idle c交换机 c在 DCi中的空闲功耗 模式(以瓦特为单位),其中 c ∈ NE i Epkt switch交换机动态能耗以处理一个数据包 (单位:焦耳) ES&F switch 交换机动态能耗的存储转发 每字节(焦耳) RT电信网络中的一组路由器 数据中心,以及数据中心与最终用户之间 nX X类路由器在电信中的数量 网络中具有 X ∈{C, B, M, F}其中C、B、M和 F分别代表核心、骨干、城域和接入路由器 路由器 P idle r路由器 r在空闲模式下的功耗,具有 r ∈ RT E p kt r X 路由器处理一个数据包的动态能耗 (单位:焦耳)与 X ∈{C, B, M, F} E SF r X 路由器存储转发的动态能耗 一个字节(以焦耳为单位)为 X ∈{C, B, M, F}|
在介绍能源模型的静态部分和动态部分之前,我们提出了一些技术假设,这些假设在不失一般性的前提下简化了模型:
1) 虚拟机规模同质(中央处理器和内存)。通过假设大规模虚拟机包含一组小规模虚拟机(i.e.,一组资源基本单元),可对异构虚拟机进行建模。
2) 所有V虚拟机在整个时间段T内均处于运行状态。
3) 对于每种架构,虚拟机均匀分布在所有基于CN的活动物理机上。该假设旨在简化模型的设计和使用。通过提供一个调度算法来指定每个计算节点上的虚拟机数量以及与其他虚拟机交换的流量,该假设可以被放宽。
4) 数据中心内网络采用胖树拓扑,电信网络则采用如前所述的分层拓扑结构‐ ogy as previously discussed。
5) 交换机的接口是双向的,上行链路和下行链路的容量相似。如果某一方向没有流量,整个接口仍然处于活动状态。
B. 模型的静态能耗部分
如图4所示,与云相关的架构的静态能耗部分包括物理机和交换机的静态能耗。对于一台物理机而言,其空闲功耗对应于服务器在开机但未运行任何任务时所消耗的功率[32]。类似地,交换机负载无关部分的能耗被视为其空闲功耗,这部分包括机箱、电源和风扇等组件的功耗[33]。
对于每个设备(物理机或交换机),其静态能耗对应于在表II中定义的时间段T内的空闲功耗。由于空闲功耗在时间上是常量,将其乘以T即可得到在时间段T内的能耗。因此,DCi的静态能耗为:
$$ E_{static}^{DC_i} = \sum_{a \in CN_i} (P_{idle}^a \cdot T) + \sum_{b \in SN_i} (P_{idle}^b \cdot T) + \sum_{c \in NE_i} (P_{idle}^c \cdot T) $$ (1)
在公式1中,CNi、SNi和NEi分别对应于DCi的基于CN的物理机、基于SN的PM和数据中心内交换机的数量。P_idle_x对应设备x的空闲功耗,该设备可以是:对于某些架构属于CNi或SNi的物理机类型1;对于某些架构属于SNi的物理机类型2;或属于NEi的数据中心内交换机。对于由单个物理机组成的纳米数据中心的完全分布式架构,由于纳米数据中心不需要交换机,因此NEi=∅ ∀i。
对于通信网络部分,静态能耗对应于用于连接数据中心和最终用户的路由器的空闲功耗。因此,该架构网络的静态能耗可以表示为:
$$ E_{static}^{Net} = \sum_{r \in RT} (P_{idle}^r \cdot T) $$ (2)
如果出于能耗感知管理的目的,某些设备处于睡眠模式而非空闲状态,则在方程1和方程2中,这些设备的空闲功耗应替换为其在睡眠模式下的功耗。为保持方程清晰,该参数未包含在方程中。
将所有部分综合起来,架构的静态能耗计算如下:
$$ E_{static}^{total} = \sum_{N}^{i=1} (E_{static}^{DC_i} \cdot PUE_i) + E_{static}^{Net} $$ (3)
该方程将总静态能耗表示为通信网络设备的静态能耗与每个数据中心(包括其制冷相关能耗,由PUE表示)的静态能耗之和。接下来,我们描述由物理机、数据中心内交换机和通信路由器引起的动态能耗部分。
C. 物理机动态能耗
物理机的动态能耗主要取决于CPU利用率[21],[32]。基于先前关于多核服务器的研究[21],[34],,我们使用分段线性函数来表示物理机动态能耗与其CPU利用率之间的依赖关系。该映射函数通过逐个满载物理机核心时的实际能耗测量值进行实例化。在[21],中,作者表明该模型对于所考虑的应用误差在几个百分点以内。因此,对于具有k个核心的物理机x,分别测量其1、2直至k个核心全部满载时的平均功耗值。然后,从这些值中减去物理机P_idle_x的空闲功耗,以保留仅动态部分。这些动态功耗值记为P_cores_x,j,其中j∈{0,…,k}且P_cores_x,0=0。能耗映射函数在每两个相邻值之间呈线性关系。因此,当某物理机使用的CPU容量比率为u,若j/k≤u≤(j+1)/k且j∈{0,…,k−1},则该物理机x在时间段T内的动态能耗可表示为:
$$ E_{dyn}^x = T \cdot [(P_{cores}^{x,j+1} - P_{cores}^{x,j}) \cdot (u - j/k) + P_{cores}^{x,j}] $$ (4)
根据公式4提供的物理机通用公式,可以通过定义在DCi中针对CN和基于SN的PM分别如何计算uCN和uSN,推导出我们两类PM的公式。对于存储节点(SN),我们假设在时间段T内的平均CPU利用率来确定其能耗,因此uSN是一个固定常量值。需要注意的是,基于SN的PM可能比其他PM拥有更多的磁盘。这种额外的能耗通过这些节点更高的空闲功耗反映在静态能耗部分(即公式1中的P_idle)。类似地,在分布式架构中,由于计算节点(CN)同时承担计算与存储的角色,其空闲功耗也更高。
对于属于CNi的CNs,在DCi的情况下,其CPU利用率取决于其所运行的服务和虚拟机。对于虚拟机而言,其虚拟CPU数量并不能准确反映其实际CPU利用率。事实上,典型的云用户倾向于对其虚拟机进行过度配置,他们以应对峰值使用为目标,未能充分利用资源弹性,从而导致虚拟机内部的CPU使用率较低[34]。此外,云服务提供商采用CPU超配技术,在无需额外投资的情况下提高收益[34]。因此,基于虚拟机的预留资源来估算物理机的能耗可能导致高估(i.e.,估算值甚至超过物理机的最大功耗)。另一种方法是获取物理机的实际CPU使用情况,然而,确定每台物理机上每个虚拟机的精确CPU使用率将非常繁琐,并且在生产基础设施上可能难以获取这些数据。此外,我们的模型并不追求对能耗进行细粒度计算,而是旨在相同初始工作负载条件下对与云相关的架构进行总体估算。因此,本文采用u_VM每个虚拟机CPU利用率的平均比率。同样,由于我们的目标并非评估虚拟机放置策略,我们在此考虑虚拟机在物理机上的均匀分配物理机。例如,这种均匀分布是知名云操作系统OpenStack[35]的默认调度行为。
每个虚拟机的平均CPU利用率uCN和每个计算节点的虚拟机数量提供了每台计算节点的CPU使用率的估算值。在此利用率基础上,我们增加一个固定值uH,以计入虚拟机管理程序的能耗以及与云相关的用于监控物理机的所有进程的能耗。基于计算节点的物理机动态能耗的整体模型如图5所示。因此,我们得到:
$$ u_{CN} = u_H + u_{VM} \cdot V / \sum_{N}^{i=1} |CN_i| $$ (5)
最后,利用公式4,与DCi中物理机相关的动态能耗为:
$$ E_{dyn}^{DC_i PM} = \sum_{a \in CN_i} E_{dyn}^a + \sum_{b \in SN_i} E_{dyn}^b $$ (6)
D. 数据中心内网络动态能耗
为了估算数据中心内部网络的动态能耗,我们需要估算每个数据中心内各交换机的动态负载相关能耗。此步骤适用于其数据中心包含交换机的与云相关的架构(i.e.,非完全分布式架构)。当交换机承载流量时,会因数据包处理以及在交换结构中存储和转发有效载荷而消耗额外的负载相关功耗[33],[36],[37]。这种额外的负载相关功耗即对应于交换机的动态能耗。
由于我们考虑的是具有相同交换机的数据中心内网络的胖树拓扑,因此它们的能耗特征是相同的。对于属于某个数据中心的给定交换机,我们用E_pkt_switch表示处理一个数据包所需的能量,用E_SF_switch表示存储和转发一个字节(来自数据包)所需的能量。在[33],中,作者表明,当正确实例化时,这种基于两个参数(即每个数据包和每字节的消耗)的模型与实际测量相比误差小于1%。
与虚拟机的CPU利用率类似,追踪每个数据包的大小是繁琐的,而且我们的模型不需要如此细粒度的精度。因此,我们假设整个基础设施中数据包的平均长度为L字节。因此,如果交换机在时间段T内接收了npT个数据包,则它必须在T内处理npT×L字节。
因此,对于给定的交换机,在时间段T内,其动态能耗计算如下:
$$ E_{dyn}^{switch} = E_{pkt}^{switch} \cdot np_T + E_{SF}^{switch} \cdot np_T \cdot L $$ (7)
为了估算npT,我们利用数据中心内网络的n元胖树拓扑结构特性。如图6所示,数据中心内部存在两种类型的流量DCi:内部流量(i.e.,数据中心内物理机之间交换的流量),记为V_in_DCi;以及外部流量(i.e.,数据中心内物理机与外部之间的流量)V_out_DCi。对于外部流量,其目的地或来源为终端用户或其他数据中心。首先,我们确定每种类型流量所经过的路径,然后量化每种流量的数据量。
采用三级胖树拓扑的数据中心,若使用具有n个端口的相似交换机,则最多可容纳n³/4台物理机和5n²/4台交换机[30]。由于该拓扑结构的特性,若数据包沿冗余路径均匀分布,则每台服务器均可实现线速传输。此外,对于此类拓扑结构,物理机之间的最长路径包含6跳,且在渐近意义上,三级胖树拓扑中跳数也趋向于6[38]。因此,我们估计在数据中心内部的流量平均经过5台交换机。从数据中心向外的流量经过3台交换机(i.e.,最短路径,包括1台接入、1台汇聚和1台核心交换机)。同样,从外部进入数据中心到达物理机的流量也经过3台交换机。
由于假设虚拟机在物理机之间均匀分布,并且产生的流量相同,因此我们假设每台虚拟机产生的流量在平均情况下也是均匀的。我们用λ表示一台物理机的平均流量速率(单位为比特每秒)。它取决于该物理机上托管的虚拟机平均数量。因此,在时间段T内,每台物理机产生的数据包平均数量为(λ·T/8L)(其中L为每个数据包的平均长度,单位为字节)。我们用q表示每台物理机发送给终端用户的分组平均比率。外部流量包括发送给终端用户的数据包以及发送给属于其他数据中心的物理机的数据包。一个给定的DCi包含pmi台物理机,且pmi=|CNi|+|SNi|。因此,对于DCi,在T期间有(pmi·q·λ·T/8L)个数据包被发送给最终用户。
由于假设虚拟机在物理机之间均匀分布,因此从某台物理机到其他物理机的流量在各物理机之间也是均匀分布的。这意味着我们可以计算p一台物理机为其他物理机产生的流量停留在其所在数据中心内的概率:
$$ p = (pm_i - 1) / (\sum_{N}^{i=1} pm_i - 1) $$ (9)
这些数据包有概率p留在数据中心内部(内部流量),以及概率(1−p)离开数据中心离开数据中心的流量(外部流量)。对于纳米数据中心(仅包含一个节点),p=0。因此,在T期间,每个DCi的物理机发送(p·λ(1−q)T/8L)个保留在DCi内部的数据包,以及((1−p)λ(1−q)T/8L)个平均均匀分布到其他数据中心的数据包。类似地,DCi从其他数据中心接收均匀分布的数据包。
对于来自最终用户的流量,我们用µ表示每个用户向数据中心产生的平均流量速率(单位:比特每秒)。因此,DCi在T期间从最终用户接收到(U·µ·T)/(8L·N),其中U为最终用户总数,N为数据中心数量。然后,我们可以将一个数据中心处理的总流量表示为以下各项之和:发送给最终用户的流量、其物理机之间交换的内部流量、发往其他数据中心的流量、来自其他数据中心的流量以及来自最终用户的流量。接着,npT表示在T期间每台交换机处理的数据包平均数量,等于在T期间该数据中心所有交换机处理的总流量除以DCi的交换机数量和数据包平均大小(8L,单位为比特):
$$ np_T = [3 \cdot q \cdot \lambda \cdot pm_i + 5 \cdot p \cdot \lambda \cdot (1 - q) \cdot pm_i + 3 \cdot (1 - p) \cdot \lambda \cdot (1 - q) \cdot pm_i + 3 \cdot \sum_{j \in {1…N} \setminus {i}} (1 - p) \cdot \lambda \cdot (1 - q) \cdot pm_j / (N - 1) + 3 \cdot U \cdot \mu / N] / [8 \cdot L \cdot 5 \cdot n^2 / 4] $$ (10)
最后,结合方程6和方程8,我们计算DCi的整体动态能耗:
$$ E_{dyn}^{DC_i} = (E_{dyn}^{DC_i PM} + E_{dyn}^{DC_i NE}) \cdot PUE_i $$ (11)
E. 电信网络动态能耗
现在我们详细说明如何计算连接数据中心之间以及数据中心与用户之间的电信网络的动态能耗。我们考虑一个完整的电信网络,包含四种不同类型的路由器:核心路由器、骨干路由器、城域路由器和接入路由器,这些均包含在RT中。类似于公式7中交换机的动态能耗,电信网络在时间段T内的动态能耗等于:
$$ E_{dyn}^{Net} = \sum_{r \in RT} (E_{pkt}^r \cdot npr_{,T} + E_{SF}^r \cdot npr_{,T} \cdot L) $$ (12)
其中npr,T表示在T期间由特定路由器r处理的平均数据包数量,E_pkt_r表示处理一个数据包所需的能量,E_SF_r表示存储和转发一个字节所需的能量。最后这两个参数取决于路由器类型,因为不同类型的路由器具有不同的架构和能耗特征。我们用n_C、n_B、n_M和n_F分别表示核心路由器、骨干路由器、城域路由器和接入路由器的数量(|RT| = n_C + n_B + n_M + n_F)。因此,若将公式12按每类路由器展开表示,则得到:
$$
\begin{align
}
E_{dyn}^{Net} &= n_C \cdot (E_{pkt}^{r_C} \cdot npr_{C,T} + E_{SF}^{r_C} \cdot npr_{C,T} \cdot L) \
&+ n_B \cdot (E_{pkt}^{r_B} \cdot npr_{B,T} + E_{SF}^{r_B} \cdot npr_{B,T} \cdot L) \
&+ n_M \cdot (E_{pkt}^{r_M} \cdot npr_{M,T} + E_{SF}^{r_M} \cdot npr_{M,T} \cdot L) \
&+ n_F \cdot (E_{pkt}^{r_F} \cdot npr_{F,T} + E_{SF}^{r_F} \cdot npr_{F,T} \cdot L)
\end{align
}
$$ (13)
为了估算每种类型路由器的平均数据包数量,我们需要详细说明可能路径根据流量估算每条路径的概率。使用电信网络的流量有三种类型:我们用npDC_DC_T、npEU_DC_T和npDC_EU_T分别表示在T期间通过数据中心之间、从最终用户到数据中心以及从数据中心到最终用户的电信网络传输的数据包总数量。根据前一小节,我们有:
$$
\begin{align
}
np_{DC_DC}^T &= \left(\sum_{i=1}^{N} (1 - p) \cdot \lambda \cdot (1 - q) \cdot pm_i\right) \cdot T / (8 \cdot L) \
np_{EU_DC}^T &= U \cdot \mu \cdot T / (8 \cdot L) \
np_{DC_EU}^T &= \left(\sum_{i=1}^{N} q \cdot \lambda \cdot pm_i\right) \cdot T / (8 \cdot L)
\end{align
}
$$ (14)
现在,对于每种流量类型,我们必须估算其可能经过的不同路径及其概率,以确定所有路由器(r ∈ RT)的npr,T。请注意,尽管流量大小不同,但从最终用户到数据中心以及从数据中心到最终用户的流量所经过的路径是相同的(方向相反)。每条路径取决于所考虑的架构,因此我们将针对给定的网络拓扑逐一详细说明各路径的概率。
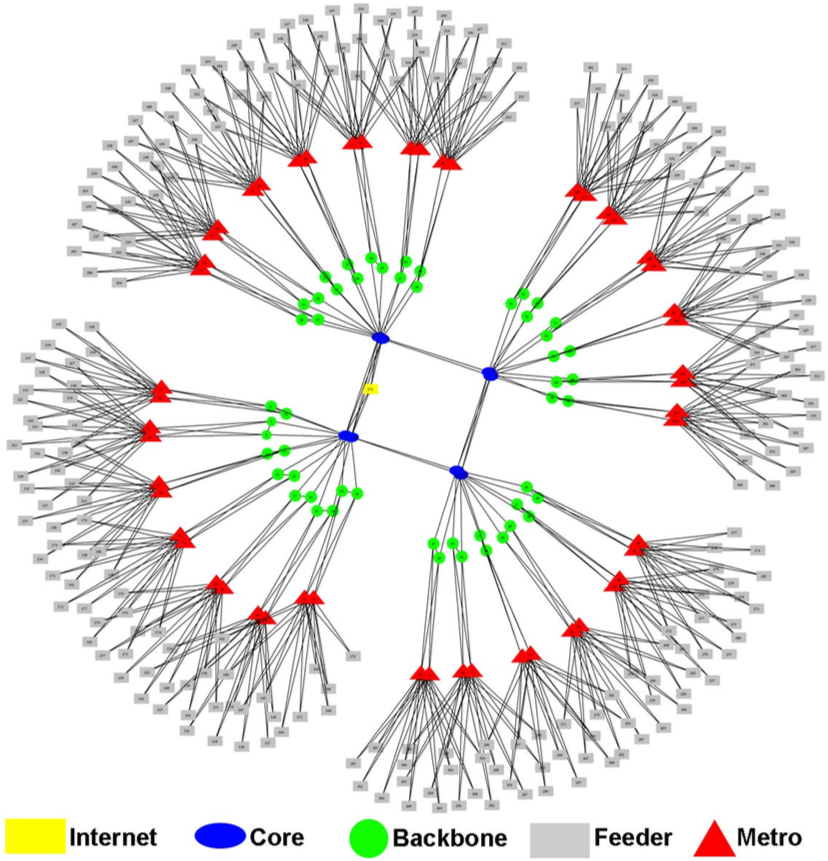
对于电信网络拓扑,我们采用[31]中提出的递归拓扑结构,作为国家级互联网服务提供商的一种现实且简化的模型。 为了简化模型,我们假设所有核心路由器都直接相互连接。
对于FC架构(完全集中式),唯一的数据中心连接到其中一个核心路由器(p=0)。因此,数据中心与最终用户之间的流量仅有两条可能路径:CBMF或CCBMF(当用户未连接到同一核心路由器时),其中C、B、M和F分别代表核心、骨干、城域和接入路由器。由于核心层包含n_C个路由器,且假设用户在接入层中均匀分布,第一条路径在每n_C种情况中出现一次,第二条路径在每n_C−1种情况中出现n_C次。这意味着对于FC架构,我们有:
$$
\begin{align
}
npr_{C,T}^{FC} &= \left( \frac{1}{n_C} + 2 \cdot \frac{n_C - 1}{n_C} \right) \cdot (np_{EU_DC}^T + np_{DC_EU}^T) / n_C \
npr_{B,T}^{FC} &= (np_{EU_DC}^T + np_{DC_EU}^T) / n_B \
npr_{M,T}^{FC} &= (np_{EU_DC}^T + np_{DC_EU}^T) / n_M \
npr_{F,T}^{FC} &= (np_{EU_DC}^T + np_{DC_EU}^T) / n_F
\end{align
}
$$ (15)
对于PD架构(部分分布式),数据中心可以连接到城域或骨干路由器。 表III 列出了可能路径及其概率(考虑虚拟机分配的均匀分布)。
表III 部分分布式云中的用户到数据中心及数据中心到数据中心路径;F:接入,M:城域,B:骨干,C:核心路由器
| 用户-数据中心路径 | 概率 | DC-DC 路径 | 概率 |
|---|---|---|---|
| FM | 1/nM | FMB | 1/nM |
| FMBC | 1/nC − 1/nM | FMBCB | 1/nC − 1/nM |
| FMBCB | 3/nC | FMBCB | 3/nC |
| MBM | 1/2nM | MBM | 1/2nM |
| MBC | 1/2nC − 1/2nM | MBCB | 1/2nC − 1/2nM |
| MBCCB | 3/2nC | MBCCB | 3/2nC |
| BB | 1/2nM | BCB | 1/2nC − 1/2nM |
| BCCB | 3/2nC | BCCB | 3/2nC |
利用表III,我们可以计算在PD架构下,每种类型的路由器在时间段T内处理的数据包数量:
$$
\begin{align
}
npr_{C,T}^{PD} &= \left( \frac{14}{n_C} - \frac{2}{n_M} \right) \cdot np_{DC_DC}^T / n_C + \left( \frac{14}{n_C} - \frac{2}{n_M} \right) \cdot (np_{EU_DC}^T + np_{DC_EU}^T) / n_C \
npr_{B,T}^{PD} &= \left( \frac{16}{n_C} - \frac{3}{2n_M} \right) \cdot np_{DC_DC}^T / n_B + \left( \frac{16}{n_C} - \frac{3}{n_M} \right) \cdot (np_{EU_DC}^T + np_{DC_EU}^T) / n_B \
npr_{M,T}^{PD} &= \left( \frac{8}{n_C} \right) \cdot np_{DC_DC}^T / n_M + \left( 1 + \frac{4}{n_C} - \frac{1}{n_M} \right) \cdot (np_{EU_DC}^T + np_{DC_EU}^T) / n_M \
npr_{F,T}^{PD} &= (np_{EU_DC}^T + np_{DC_EU}^T) / n_F
\end{align
}
$$ (16)
对于FD架构(完全分布式),数据中心连接到接入路由器。这意味着用户-数据中心路径与数据中心-数据中心路径相同。 表IV 列出了可能路径及其概率。
表IV FD云中的用户-数据中心和数据中心-数据中心路径;F:接入路由器,M:城域路由器,B:骨干路由器和C:核心路由器
| 用户-数据中心路径 | 概率 | DC-DC 路径 | 概率 |
|---|---|---|---|
| F | 1/nF | FMF | 2n_M/nF − 1/nF |
| FMBCBMF | 2/nC − 2n_M/nF | FMBCBMF | 2/nC − 2n_M/nF |
| FMBCCBMF | 6/nC | FMBCCBMF | 6/nC |
使用表IV,我们计算FD架构中每种类型的路由器在T期间处理的数据包数量:
$$
\begin{align
}
npr_{C,T}^{FD} &= \left( \frac{14}{n_C} - \frac{2n_M}{n_F} \right) \cdot np_{DC_DC}^T / n_C + \left( \frac{14}{n_C} - \frac{2n_M}{n_F} \right) \cdot (np_{EU_DC}^T + np_{DC_EU}^T) / n_C \
npr_{B,T}^{FD} &= \left( \frac{16}{n_C} - \frac{4n_M}{n_F} \right) \cdot np_{DC_DC}^T / n_B + \left( \frac{16}{n_C} - \frac{4n_M}{n_F} \right) \cdot (np_{EU_DC}^T + np_{DC_EU}^T) / n_B \
npr_{M,T}^{FD} &= \left( \frac{16}{n_C} - \frac{2n_M - 1}{n_F} \right) \cdot np_{DC_DC}^T / n_M + \left( \frac{16}{n_C} - \frac{2n_M - 1}{n_F} \right) \cdot (np_{EU_DC}^T + np_{DC_EU}^T) / n_M \
npr_{F,T}^{FD} &= \left( \frac{16}{n_C} - \frac{1}{n_F} \right) \cdot np_{DC_DC}^T / n_F + \left( \frac{16}{n_C} - \frac{1}{n_F} \right) \cdot (np_{EU_DC}^T + np_{DC_EU}^T) / n_F
\end{align
}
$$ (17)
最后,对于FD-CC架构,包含CN的DCs的位置与FD架构相同,但对于所有其他架构(数据中心内),CN和SN之间的流量是内部的,但在FD-CC架构中为外部流量。因此,与FD架构相比,这代表了额外的流量。我们用λSN表示一个CN发送到一个SN的平均流量(单位为bps)。这意味着λSN ≤ λ。DC-SN流量的路径为FMBC。因此,在T期间,每种类型的路由器相比FD架构都有额外的∑_i=1^N (λSN·pmi)·T/(8·L)个数据包流量。对于用户-数据中心流量,其主要由用户与CN之间的流量主导。
结合公式11和12可得与云相关的架构的总动态能耗:
$$ E_{dyn}^{total} = \sum_{i=1}^{N} E_{dyn}^{DC_i} + E_{dyn}^{Net} $$ (18)
最后,对于每种架构,其在T期间的静态能耗由公式3给出,动态能耗由方程18给出。
五、模型应用
本节使用所提出的能源模型,对四种不同类别的架构进行分析和比较。
A. 模型实例化
为了进行公平比较,我们为所有云架构考虑相同数量的CN:1,000个计算节点,持续时间为一小时。需要注意的是,在FD和FD-CC架构中,CN还支持SN和/或存储服务,因此这些架构中的CN功能更强大。我们考虑采用FC架构,该架构包含一个嵌入了1,000个计算节点的大型数据中心。PD基础设施包括8个中等规模的同构数据中心,每个包含125个计算节点。FD-CC架构由1,000个纳米数据中心(每个含1个计算节点)和8个中央小型控制数据中心(包含存储节点)组成。最后,FD架构与FD-CC类似,由1,000个纳米数据中心(每个含1个计算节点)构成。 表五 总结了每种架构的配置。
表五 架构特性
| 架构 | FC | PD | FD-CC | FD |
|---|---|---|---|---|
| 数据中心数量 (N) | 1 | 8 | 1008 | 1000 |
| 物理机数量 (∑pm_i) | 1016 | 1024 | 1024 | 1000 |
| CNs数量 (∑ | CN_i | ) | 1000 | 1000 |
| 存储节点数量 (∑ | SN_i | ) | 16 | 24 |
| 每个数据中心的交换机数量 ( | NE_i | ) | 320 | 80 |
| 核心路由器数量 (n_C) | 8 | 8 | 8 | 8 |
| 骨干路由器数量 (n_B) | 52 | 52 | 52 | 52 |
| 城域路由器数量 (n_M) | 52 | 52 | 52 | 52 |
| 接入路由器数量 (n_F) | 260 | 260 | 260 | 260 |
基于SN的PM数量取决于CN的数量和架构特性。对于FC或PD架构中的大型/微型数据中心,我们考虑配置3个全局SN(以确保高可用性),每100个CN额外增加1个SN。对于FD-CC,我们在网络核心的8个小型数据中心内各配置3个SN。对于FD架构,每个纳米数据中心仅有一个多用途PM。
为了获得物理机的实际能耗特征,我们在法国实验平台Grid’5000[39]的Taurus服务器(12核、32GB内存和598GB/SCSI存储)上进行了实验,这些服务器用于FC和PD云的物理机;以及Parasilo服务器(16核、128GB内存和5 600 GB HDD + 200 GB SSD/SAS存储)用于FD和FD-CC云的物理机。我们使用压力基准测试获取每个负载核心的功耗值(P_cores_x,j)。Grid’5000测试平台通过外接瓦特计对每台Taurus服务器提供功率测量,每秒一个数值,精度为0.125瓦特。 表VI *显示了这些测量的结果。
对于具有大型数据中心(i.e.,1000个计算节点和13个SN)的FC架构,采用16元胖树交换拓扑(i.e.,320个交换机)。由于PD架构的数据中心包含125个计算节点和3个SN,我们考虑使用8元胖树拓扑。在FD-CC类别中,一个中央控制数据中心包含3个基于SN的PM,因此每个数据中心需要一个交换机。对于FD类别,则不需要任何数据中心内网络。关于电信网络拓扑,如图7所示,受[31],启发,我们考虑一个实际的电信网络(i.e.,某互联网服务提供商的简化版本),该网络包括8个核心路由器、52个骨干路由器、52个城域路由器用于汇聚层,以及260个接入层接入设备(i.e.,总计372个路由器通过718条链路连接)。
对于虚拟机,我们假设每个虚拟机保留一个CPU核心(即小规模同构虚拟机),并且每个虚拟机平均使用其预留CPU的15%(u_VM)。该数值是在实际云服务提供商上测量得到的[34]。此外,由于Taurus的一个核心所使用的CPU资源与Parasilo的一个CPU核心之间没有明显差异,我们假设所有CPU核心是相似的(即在Taurus上保留的虚拟机与在Parasilo上保留的虚拟机之间的资源没有差异)。另一方面,由于工作负载的多样性和活跃物理机数量的变化,确定存储节点的平均CPU利用率(uSN)具有挑战性。因此,在我们的仿真中,我们简单假设基于SN的PM的平均CPU利用率为40%。
对于路由器的能耗特征,我们考虑[40]中提出的测量结果:核心、骨干、城域和接入路由器的空闲功耗(P_idle_r)分别为11,000、4,000、2,000和2,000瓦特。另一方面,对于数据中心内部的交换机,我们考虑一种16端口交换机(即,16元胖树拓扑):思科WS-C6503交换机,仅配备一块16端口WS-X6516-GE-TX线卡。根据思科电源计算器[41],其功耗约为280瓦特。此外,受[42],启发,我们认为大型和微型数据中心的总流量中有70%保留在其内部。[33],[36]中的实际测量表明,不同路由器的E_pkt_r之间没有明显差异。因此,我们简单假设所有类型的路由器和交换机均采用相同的1,300纳焦/包。类似地,我们考虑所有网络设备的E_SF_r=14纳焦/字节。
我们假设FC和PD架构中所有大型和微型数据中心的PUE值为1.2。作为对比,谷歌当前在其数据中心的平均PUE为1.11[43]。为了消除不同能源管理技术(即控制设备的睡眠和活动模式)对评估云能耗的影响,我们假设所有物理机和网络设备始终处于活动状态。
表VI PM能源配置文件
| 活动核心数量 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Taurus | 97 | 128 | 150 | 158 | 165 | 171 | 177 | 185 | 195 | 200 | 204 | 212 | 220 | ||||
| Parasilo | 98 | 148 | 161 | 176 | 178 | 180 | 184 | 200 | 208 | 212 | 215 | 217 | 218 | 221 | 230 | 237 | 241 |
B. 模拟结果
我们考虑一个通用场景,即一组最终用户请求了10,000个虚拟机。这些虚拟机已被分配,并在所考虑的时间段T(1小时)内持续运行。这意味着每个计算节点平均托管10个虚拟机。基于提出模型,我们计算每种架构的能耗。变量包括单台物理机产生的平均流量(i.e.,λ:250、500和1000 Mbps)以及平均包长度(L:100、576和1000字节)。需要注意的是,对于给定的流量,数据包长度会变化,从而影响数据包数量,但不影响总数据量。
图8显示了四种与云相关的架构的总能耗。在所有情况下,FD架构在能耗方面均优于其他架构。特别是,在最高流量速率(即1,000 Mbps)下,其能耗分别比FC和PD架构低14%至25%。FD-CC在所考虑的流量速率下(每台物理机最高1,000 Mbps)表现出接近FD的性能。
为了更详细地观察结果,我们参考了 表七 中列出的静态能耗部分(由公式3提供)以及图9中放大的动态部分(由公式18给出)。
表七 不同云类别的静态(基础设施)能耗(单位:千瓦时)
| FC | PD | FD-CC | FD | |
|---|---|---|---|---|
| CNs | 116.4 (10%) | 116.4 (9%) | 98 (10%) | 98 (10%) |
| SNs | 1.51 (<1%) | 2.8 (<1%) | 2.4 (<1%) | 0.0 (<1%) |
| 交换机 | 107.5 (9%) | 215 (19%) | 2.2 (<1%) | 0.0 (<1%) |
| 核心路由器 | 88 (8%) | 88 (7%) | 88 (9%) | 88 (9%) |
| 骨干/城域路由器 | 208 (18%) / 104 (9%) | 208 (17%) / 104 (8%) | 208 (20%) / 104 (10%) | 208 (20%) / 104 (10%) |
| 接入路由器 | 520 (46%) | 520 (42%) | 520 (51%) | 520 (51%) |
| 总计 | 1145.3 | 1254.2 | 1022.5 | 1017.8 |
表七显示,FD基础设施的能耗低于其他架构。如预期,由于PMs规模(因此能耗)不同,FD和FD-CC架构中CNs的静态能耗总量略高于FC和PD架构。关于SNs的静态能耗,由于使用了更多的SNs,PD和FD-CC云在此部分的能耗高于FC架构。然而,尽管FD-CC架构使用的SNs数量更多,其SNs的静态能耗总量仍低于FC云,这归因于FD-CC架构具有更低的PUE。对于数据中心内网络,PD架构消耗更多静态能耗,因其使用的交换机数量多于其他架构。此外,FD架构在该部分可显著节约能源,因为它不需要任何交换机。关于电信网络路由器,在所有情况下均相同。我们可以观察到,尽管一台核心路由器的能耗最高,但总体而言,接入路由器的消耗因其数量众多而在这部分静态能耗中占据主导地位。
在静态能耗部分,数据中心内部交换机的数量对与云相关的架构的能耗起着重要作用。影响静态能效的其他因素包括存储节点数量、物理机的能量效率以及电能使用效率。
图9显示了四种架构的总动态能耗。在低流量(i.e.,λ=250 Mbps)情况下,数据包长度对动态能耗的影响不大,但在较高速率(i.e.,500和1000 Mbps)下,其影响较为显著。图9还表明,FD架构由于没有数据中心内网络,其动态能耗通常低于其他架构。
由于FD-CC和FD架构使用了更多能耗较高的CN,因此其由物理机引起的动态能耗高于其他架构。此外,FD-CC架构使用了最多数量的服务节点,因而消耗的能量也高于其他架构。关于交换机的动态能耗,FD基础设施的交换机动态能耗为零。FD-CC云的能耗低于FC和PD架构,因为FD-CC仅需少量交换机即可连接其服务节点。尽管总体而言FC和PD架构的结果差异可忽略不计,但在流量增加时,PD架构的表现略优于FC架构。这是由于在大规模数据中心中,物理机之间的路径更长所致。
关于路由器的动态能耗,数据中心的位置与流量对能耗的影响之间存在直接关系。尽管FD架构的路由器动态能耗略低于FD-CC,但对于在控制器(SNs)与CN之间具有高流量交换的应用,两者之间的差异应更为显著。
C. 讨论
在本部分中,我们总结了主要发现。
Telecommunication network :由于我们考虑了数据中心与最终用户之间整个网络的能耗,其能耗在总能耗中占据主导地位。这与文献中的观点一致,即电信网络在包括终端设备在内的整体信息通信技术能耗中占主要部分(2014年为37%)[44]。未来的分布式云架构可以通过尽可能保持流量本地化,减少对网络路由器的需求。
数据包长度 :结果表明,在高流量速率下,数据包长度对所有架构的动态能耗有重要影响。
PUE :电能使用效率对中大型数据中心架构的能耗影响巨大。信息通信技术设备能效的提升可能会因高电能使用效率而被抵消。
数据中心内网络能耗 :在FC和PD架构中,数据中心内交换机的能耗可能超过数据中心总能耗的50%,甚至高达基础设施总能耗的20%。选择合适的网络架构和交换机规模可显著提升基础设施的能效。
总体能耗 :FD架构不需要数据中心内交换机,也不需要数据中心,因此其电能使用效率等于1(无需空调设备)。这使得FD乃至FD-CC架构比其他架构更节能。然而,本文考虑的是所有架构中性能相似的计算节点。在某些未来的雾计算与边缘计算基础设施中,若采用异构终端用户设备,则情况可能不同。
VI. 结论
通过增加从完全集中式到完全分布式的与云相关的架构数量,许多云研究人员和服务提供商都希望了解哪种基础设施能更节能。本文探讨了这一问题。
首先,提出了一种分类法,用于对云相关架构进行分类,并识别它们之间的主要拓扑差异。受此分类法启发,构建了一个全面的然后提出了一种易于使用且可扩展的能源模型。该模型准确地突出了基础设施在能耗方面的架构差异。
使用能源模型分析了四种不同的与云相关的架构(即FC、PD、FD-CC和FD)。结果表明,完全分布式架构(FD)的能耗分别比完全集中式(FC)和部分分布式(PD)架构低14%至25%。通过采用电源使用效率(PUE)指标,提出模型捕捉到了冷却系统的影响,而冷却系统在当前的能耗中已不可忽略。
根据这一分析,未来关于绿色新兴云架构的研究应集中在改善其电信网络使用、计算基础设施的效率(即,PUE)以及利用异构基础设施以更好地满足用户需求。
尽管该模型考虑了许多重要的技术要点,但仍有一些改进可以作为未来的工作。例如,该模型目前假定最终用户的分布是均匀的。但在实际环境中,最终用户的分布可能是不均匀的。我们还计划将该模型扩展以支持其他技术(容器、VNFs)和架构(异构通信网络,移动网络)。

















 16
16

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









