









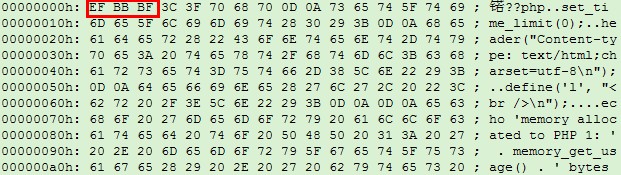
如果文件的编码采用utf8格式,且在文件的开头写入了UTF8 BOM(即第一到第三个字符的十六进制分别是EF BB BF,用UltraEdit打开切换到十六进制可以看到),则可以通过下面的isUtf8函数判断文件本身的编码。
function isUtf8($file) {
$content = file_get_contents($file);
$charset[1] = substr($content, 0, 1);
$charset[2] = substr($content, 1, 1);
$charset[3] = substr($content, 2, 1);
if (ord($charset[1]) == 239 && ord($charset[2]) == 187 && ord($charset[3]) == 191){
return true;
} else {
return false;
}
}
var_dump(isUtf8('test2.php'));
如果某个文件本身是UTF8编码,但是前面三个字符不是EF BB BF,则表示没有写入BOM。例如我打开某个UTF8编码的文件前面三个字符分别是3C 3F 70,实际上是<?p三个字符,具体可以看 ascii table 。

判断中文和编码有关,gbk是双字节,utf8是三字节,可以根据中文的范围来判断。
编码范围
1. GBK (GB2312/GB18030)
\x00-\xff GBK双字节编码范围
\x20-\x7f ASCII
\xa1-\xff 中文
\x80-\xff 中文
2. UTF-8 (Unicode)
\u4e00-\u9fa5 (中文)
\x3130-\x318F (韩文
\xAC00-\xD7A3 (韩文)
\u0800-\u4e00 (日文)
if(preg_match('/[\x{4e00}-\x{9fa5}]/u',$str)==1)
{
echo "含有中文字符\n";
}
假设某个文件前面三个字符不是EF BB BF,而文件本身的编码不确认,你的系统的数据库编码是UTF8,为了保证将此文件中的数据导入到数据库后不乱码,则需要作一下判断,如果文件中的中文是UTF8编码,则不需要进行编码转换,否则需要进行编码转换。
下面做个测试
文件本身是utf-8编码的。
<?php
$str = 'utf8编码的汉字测试';
if (preg_match('/[\x{4e00}-\x{9fa5}]/u', $str) == 1) {
echo "含有UTF8编码的中文字符\n";
} else {
echo "不含有UTF8编码的中文字符\n";
}
?>
输出:
含有UTF8编码的中文字符
<?php
$str = 'utf8编码的汉字测试';
$str = iconv('UTF-8', 'GBK', $str);
if (preg_match('/[\x{4e00}-\x{9fa5}]/u', $str) == 1) {
echo "含有UTF8编码的中文字符\n";
} else {
echo "不含有UTF8编码的中文字符\n";
}
?>
输出:
不含有UTF8编码的中文字符
function isUtf8($file) {
$content = file_get_contents($file);
$charset[1] = substr($content, 0, 1);
$charset[2] = substr($content, 1, 1);
$charset[3] = substr($content, 2, 1);
if (ord($charset[1]) == 239 && ord($charset[2]) == 187 && ord($charset[3]) == 191){
return true;
} else {
return false;
}
}
var_dump(isUtf8('test2.php'));
如果某个文件本身是UTF8编码,但是前面三个字符不是EF BB BF,则表示没有写入BOM。例如我打开某个UTF8编码的文件前面三个字符分别是3C 3F 70,实际上是<?p三个字符,具体可以看 ascii table 。
判断中文和编码有关,gbk是双字节,utf8是三字节,可以根据中文的范围来判断。
编码范围
1. GBK (GB2312/GB18030)
\x00-\xff GBK双字节编码范围
\x20-\x7f ASCII
\xa1-\xff 中文
\x80-\xff 中文
2. UTF-8 (Unicode)
\u4e00-\u9fa5 (中文)
\x3130-\x318F (韩文
\xAC00-\xD7A3 (韩文)
\u0800-\u4e00 (日文)
if(preg_match('/[\x{4e00}-\x{9fa5}]/u',$str)==1)
{
echo "含有中文字符\n";
}
假设某个文件前面三个字符不是EF BB BF,而文件本身的编码不确认,你的系统的数据库编码是UTF8,为了保证将此文件中的数据导入到数据库后不乱码,则需要作一下判断,如果文件中的中文是UTF8编码,则不需要进行编码转换,否则需要进行编码转换。
下面做个测试
文件本身是utf-8编码的。
<?php
$str = 'utf8编码的汉字测试';
if (preg_match('/[\x{4e00}-\x{9fa5}]/u', $str) == 1) {
echo "含有UTF8编码的中文字符\n";
} else {
echo "不含有UTF8编码的中文字符\n";
}
?>
输出:
含有UTF8编码的中文字符
<?php
$str = 'utf8编码的汉字测试';
$str = iconv('UTF-8', 'GBK', $str);
if (preg_match('/[\x{4e00}-\x{9fa5}]/u', $str) == 1) {
echo "含有UTF8编码的中文字符\n";
} else {
echo "不含有UTF8编码的中文字符\n";
}
?>
输出:
不含有UTF8编码的中文字符


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









