




拉勾网: 是一家专为拥有3至10年工作经验的资深互联网从业者,提供工作机会的招聘网站。拉勾网专注于在为求职者提供更人性化、专业化服务的同时,降低企业端寻觅良才的时间和成本。拉勾网致力于帮助互联网人士做出更好的职业选择,让求职者每一次职业选择变的更加明智。
官网: https://www.lagou.com/
技术难度: 爬取拉勾网的技术难点主要是在它的反反爬虫机制,很容易就会触发它。我曾经看网上的视频教程,拉勾网的反爬虫做了很多的更新,所有直接就连网页的源码也获取不了就被反爬虫了。后来尝试了headers,cookie,代理IP,但是都失败了。每次拉勾网的网页加载后,它的cookie值都是变化的,并且只能使用一次。
数据加载方式: 拉勾网的数据加载方式和很多的网站一样,使用json文件加载,随便搜索一个职位看看
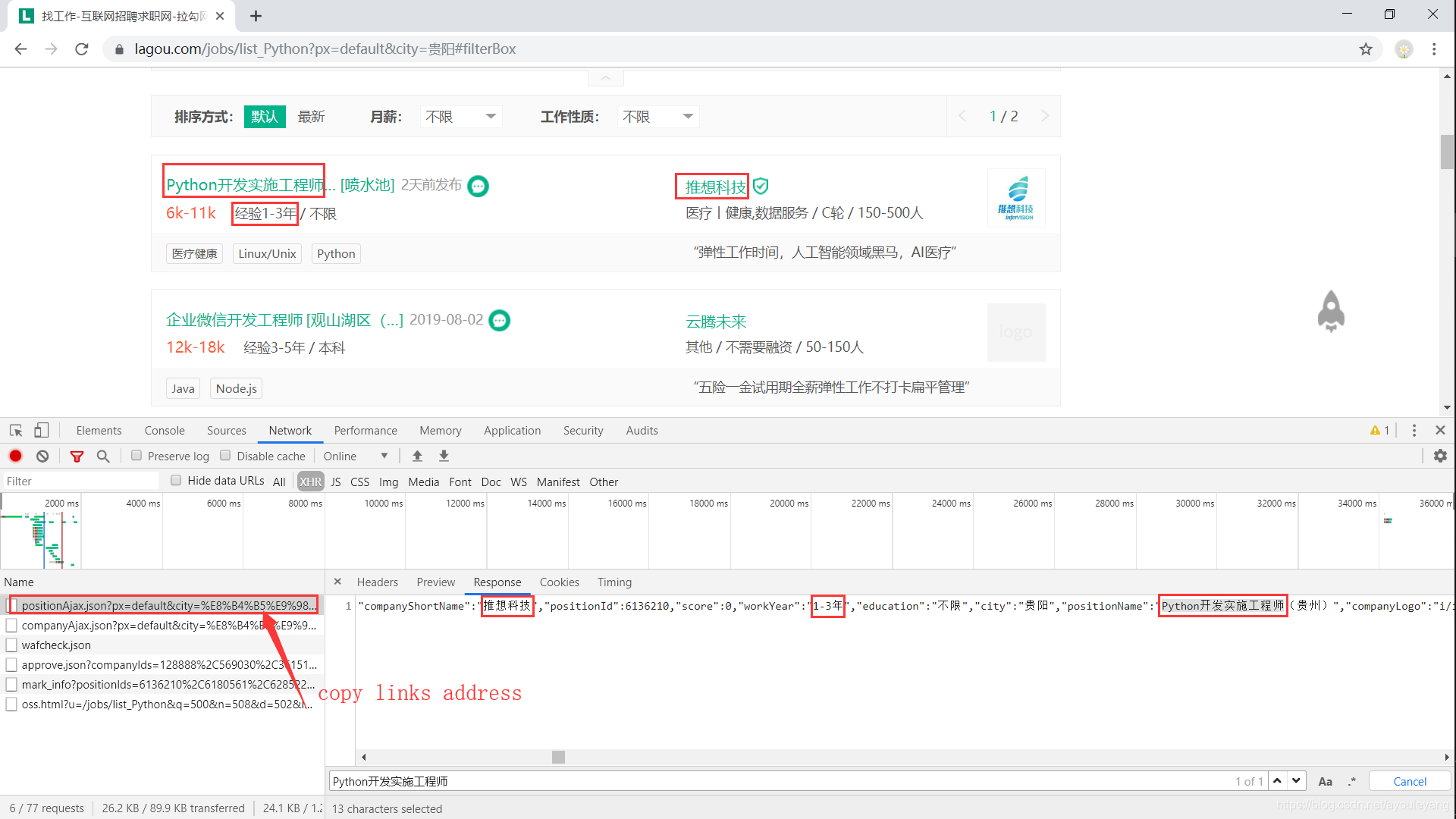
从图中可以看出就是通过它加载这些数据信息的,复制它的路径在该浏览器打开试试

“操作频繁”,这不可能,我只是把它复制到浏览器打开而已,等了一段时间后,它还是这样。其实这就是遇到它的反爬虫了,就在当前浏览器打开也不行,因为它的cookie值就只能用一次。
解决方法: 使用selenium库,它可以模拟人做自动化测试,对付这个反爬虫虽说有点杀鸡用牛刀的嫌疑,但是效果的确非常棒。它可以获取网页源码,却不能解析网页源码,所以还导入lxml来提取HTML的信息。
实现思路
1、获取拉勾网URL
selenium可以从拉勾网的官网一步一步的自动进行,为了简便,就直接从选好工作后的链接进行了。在官网搜索职位,选择一个城市,就得到了URL。
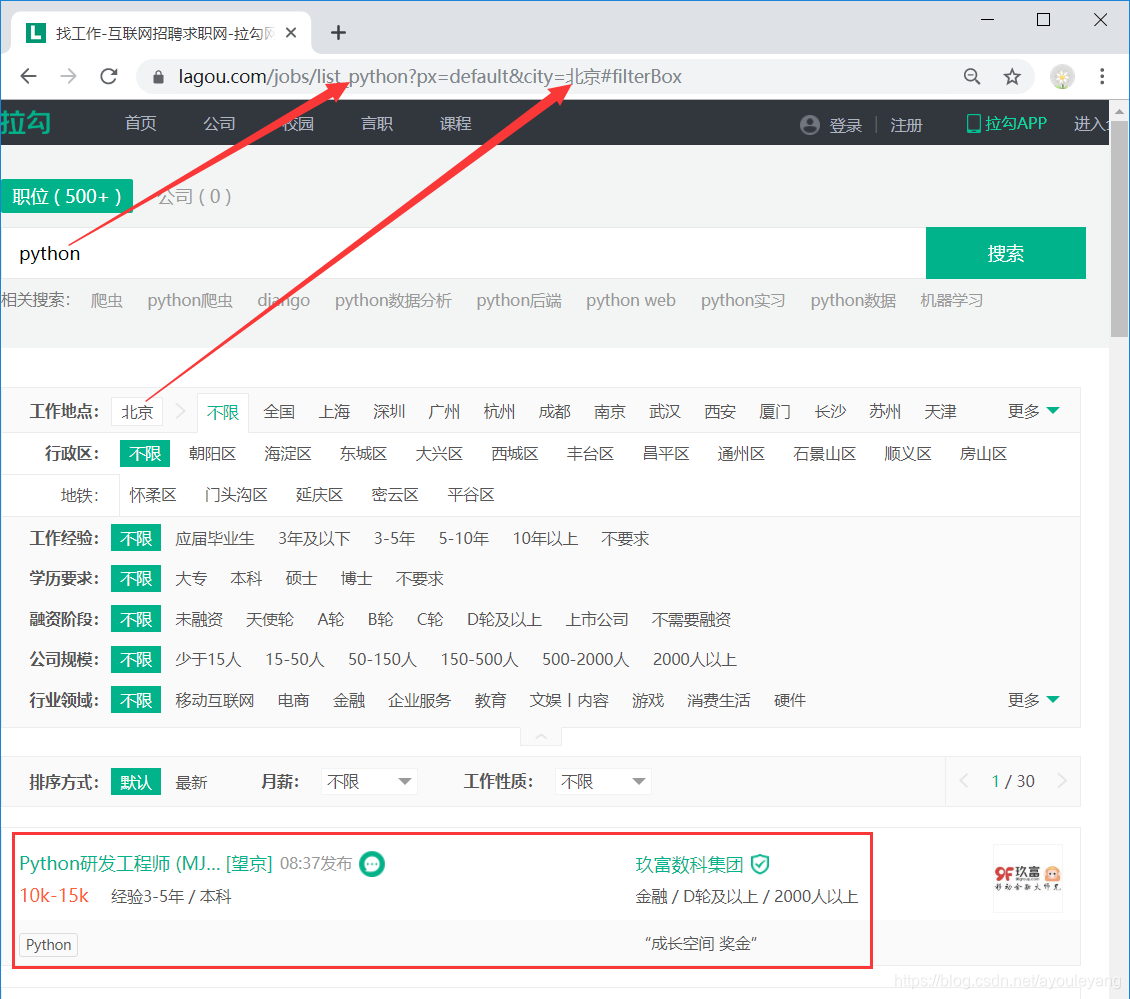
现在就可以直接构造一个链接,把它的职位和城市传进去,为了模拟搜索,我就只是传了城市进去。
city = input("请输入您要查询的城市:")
url = 'https://www.lagou.com/jobs/list_python?px=default&city='+str(city)+'#filterBox'
模拟浏览器清空搜索框的职位后,重新输入职位信息
major = input("请输入您要查询的工作:")
driver = webdriver.Chrome()#控制浏览器,自动化
url = 'https://www.lagou.com/jobs/list_python?px=default&city='+str(city)+'#filterBox'
driver.get(url)#打开网页
inputJob = driver.find_element_by_xpath('//*[@id="keyword"]')#找到输入框
inputJob.clear()#清空输入框
inputJob.send_keys(major)#获得并输入刚才输入的工作
inputJob.send_keys(Keys.ENTER)#按回车键
2、自动获取网页中职位信息的页数
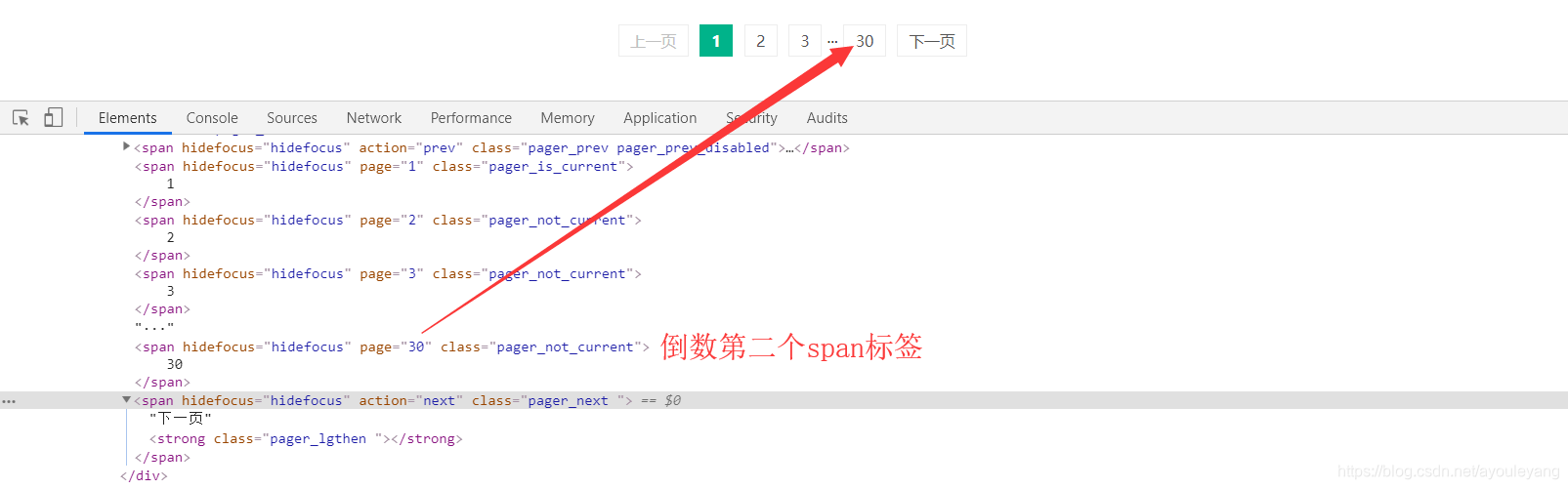
2.1、获取最大页数
从中可以看出最大的页数值就在倒数的第二个标签中,从倒数第二个span就可以获得它,并把它的类型转化成int型,作为循环的次数。
last_page = driver.find_element_by_xpath("//div[@class='pager_container']/span[last()-1]")
last_page = int(last_page.get_attribute("page"))#取到页数的数字
for i in range(1,last_page+1,1):#判断页面并限制循环次数,每个页面爬取一次
print ("正在爬取第%s页......\n"% i)
2.2、点击下一页
拉勾网加载下一页后,该页面的URL并不会发生变化,所以就不能从URL入手了,只能通过点击下一页来完成获取下一个页面的信息。但是第一个页面的信息要完全获取完后才能点击下一页,在点击前必须要进行判断。
while i>1:#第一次不执行,停止由最大页数循环控制
next_page = driver.find_element_by_xpath("//div[@class='pager_container']/span[last()]")#获取下一页按钮
next_page.click()#点击下一页
break #跳出while循环,每次只做一次循环
3、获取网页源码
在获取网页或加载数据的地方,最好停5秒钟以上,防止被识破是爬虫程序
time.sleep(5) #暂停五秒,注意反爬虫
source = driver.page_source#获取该网页源码
4、解析并提取信息
html = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









