 Amazon S3 Vectors解决AI存储挑战
Amazon S3 Vectors解决AI存储挑战




万亿级向量、毫秒级检索,S3 Vectors为AI应用打造坚实数据基石
在AI驱动的应用浪潮中,向量数据已成为关键基础设施。然而,海量向量存储与检索的复杂性却成为许多开发团队的“拦路虎”。2024年,AWS正式推出Amazon S3 Vectors(预览版)——全球首个原生支持向量数据的大规模云存储服务,为AI开发者带来全新解决方案。
一、AI时代下,向量存储面临的核心痛点
-
数据孤岛问题:向量数据与原始文件(图片/文本/视频)分离存储,增加管理复杂度
-
规模瓶颈:传统向量数据库在百亿级数据量时面临性能和成本的双重压力
-
运维负担:需独立维护专用向量数据库集群,增加技术栈复杂度
-
成本失控:为满足峰值查询需求过度配置资源,导致利用率低下
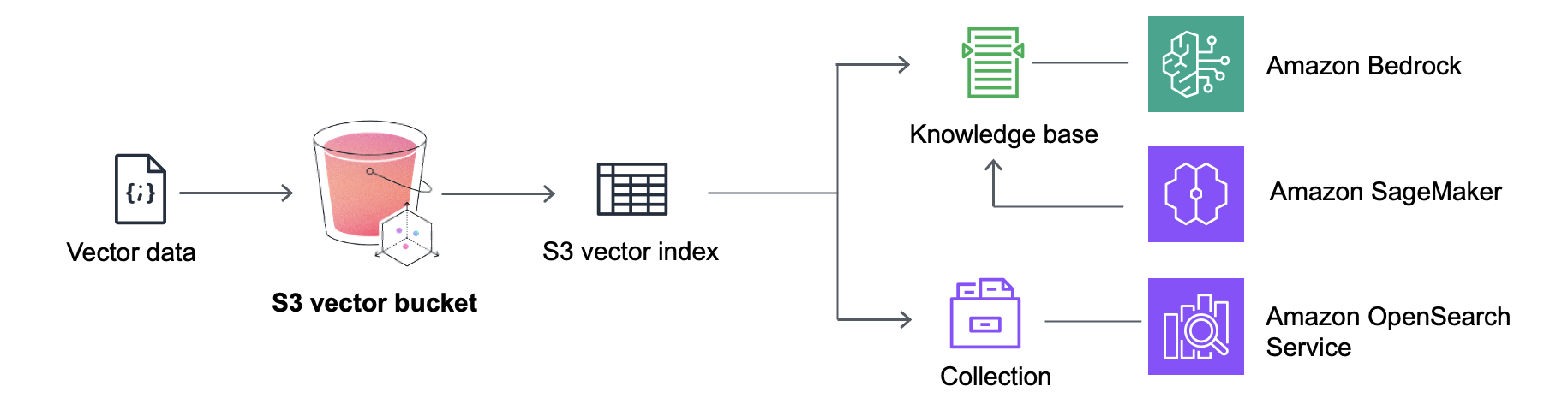
二、S3 Vectors的核心技术突破
1. 原生向量存储引擎
-
在S3对象元数据层直接实现向量存储
-
支持float32/float16/bfloat8等多种精度格式
-
单桶支持万亿级向量存储(理论无上限)
2. 集成高性能检索
-
内置近似最近邻(ANN)搜索算法
-
支持
cosine/L2/inner product等多种相似度算法 -
毫秒级响应:100万向量集中平均查询延迟<50ms
3. 统一数据管理
# 典型操作示例
import boto3
s3_client = boto3.client('s3-vector')
# 上传向量
response = s3_client.put_vector(
Bucket='ai-vectors-bucket',
Key='product-image-embedding',
Vector=[0.23, -0.87, ..., 0.45], # 1536维向量
Metadata={'category': 'electronics'}
)
# 相似度搜索
results = s3_client.search_vectors(
Bucket='ai-vectors-bucket',
QueryVector=[0.12, -0.65, ..., 0.31],
MaxResults=10,
SimilarityType='COSINE'
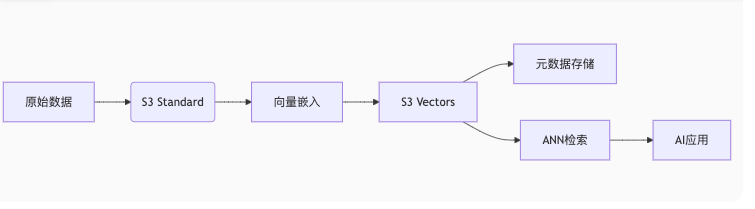
)三、实战解决方案:构建端到端AI应用
场景:电商视觉搜索平台
传统架构
对象存储(S3) -> 向量数据库 -> 应用服务器
↑ ETL ↑
└-------------------------┘
基于S3 Vectors的新架构:
统一存储层(S3 + S3 Vectors)
↑
应用服务器
性能对比(10亿向量场景)
| 指标 | 传统方案 | S3 Vectors方案 |
|---|---|---|
| 存储成本 | $38,000/月 | $12,000/月 |
| p99查询延迟 | 120ms | 65ms |
| 运维复杂度 | 高(3个组件) | 低(1个组件) |
四、开发者升级指南
1. 数据迁移路径
# 使用AWS DataSync迁移现有向量
$ aws datasync create-task \
--source-location-type=VECTOR_DB \
--destination-location-type=S3_VECTOR \
--options PreserveMetadata=ALL2. 检索优化技巧
-
分层索引:对热数据启用
HNSW索引,冷数据使用IVF-PQ -
混合查询:结合向量搜索与元数据过滤
SELECT * FROM s3vector_scanned_bucket
WHERE metadata['category'] = 'shoes'
ORDER BY similarity DESC
LIMIT 5五、技术演进展望
随着S3 Vectors正式GA,AWS路线图显示将新增:
-
实时更新API:支持增量索引更新(当前为异步构建)
-
多模态支持:统一存储文本/图像/视频嵌入向量
-
联邦查询:跨多个S3桶执行联合向量搜索
目前S3 Vectors已在美东(us-east-1)、欧洲(eu-west-1)区域开放预览。开发者可通过AWS控制台提交使用申请,或通过AWS CLI直接体验:
aws s3api put-bucket-vector-configuration \
--bucket my-vector-bucket \
--vector-configuration Status=Enabled
结语:当存储基础设施开始“理解”向量数据,AI应用的开发范式正被重新定义。S3 Vectors的出现不仅简化了技术栈,更将向量处理成本降低达60%。这或许标志着云存储进入智能化的新阶段——数据不再被动存储,而是主动参与计算。


















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









