



新爬虫笔记:
新笔记:
python对象和json对象的转换:


urllib的一个类型,六个方法。

urllib的下载的三个步骤:
1.request的封装
2.发送请求并转换格式
3.保存
urllib下载网页和视频
第一个参数是内容第二个是位置

Post请求参数
post的data一定要两次编码


代理和动态cooker的使用

懒加载,在图片网站没有加载完图片的时候,会是另外个名字
代理池的使用
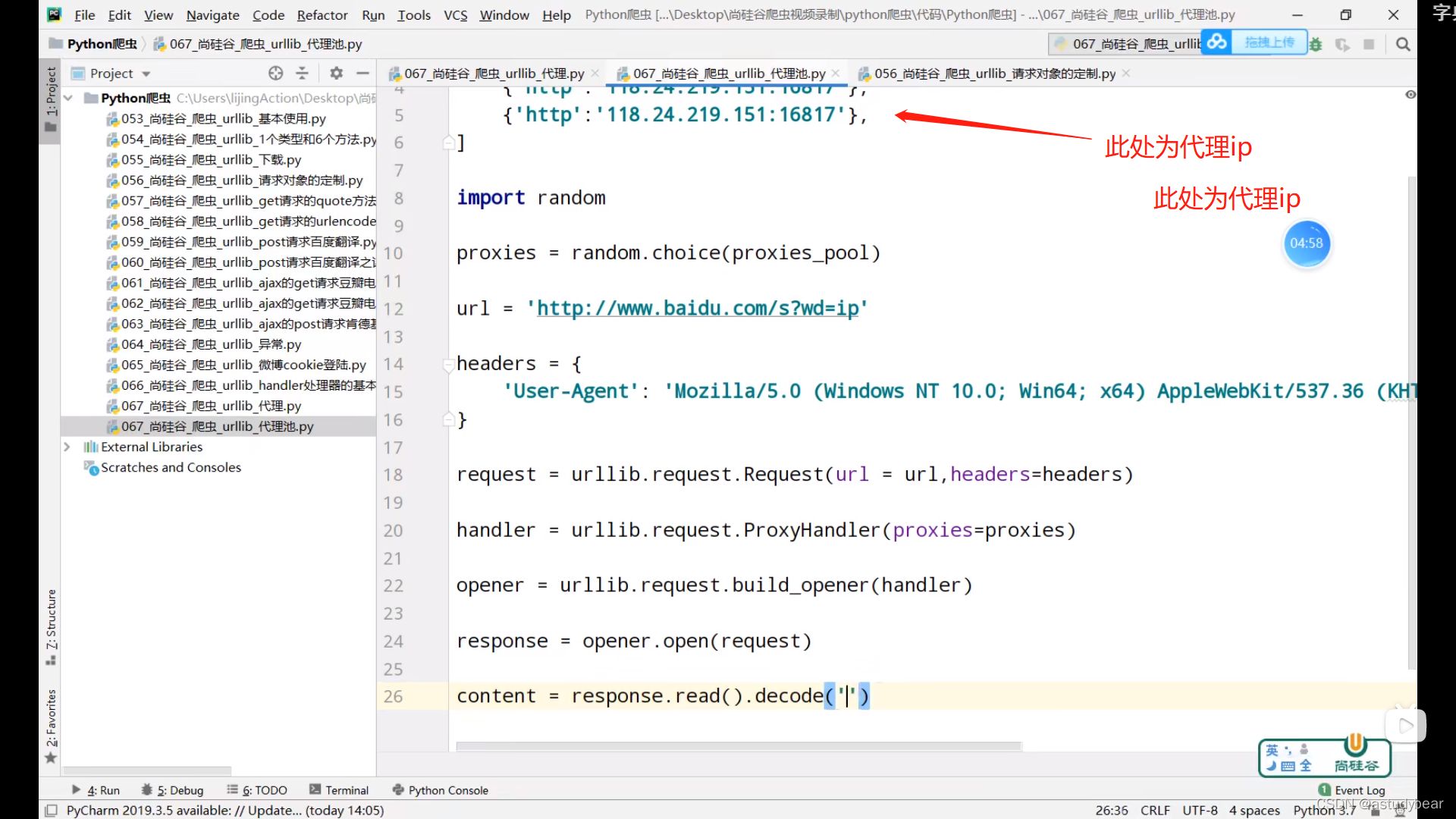
jsonpath:

请求接口后返回的json数据要处理一下才是真正的json数据
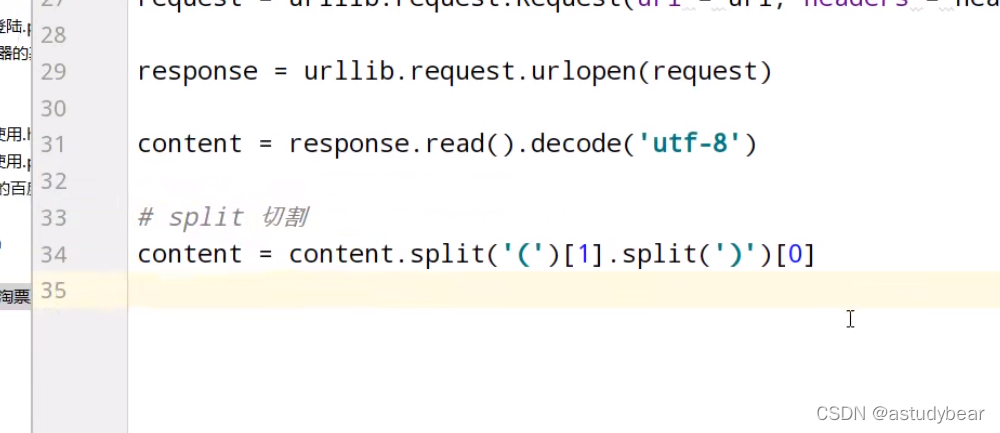
jsonpath只能对本地的数据进行解析,所以爬取到的json要先放在本地,然后在读取再解析数据
json.cn

![]()
可以通过selenium的page_source获取网页源码

六种定位方式
chromedriver.storage.googleapis.com/index.html
驱动下载地址


无界面的selenium

selenium的键盘操作

封装起来

requests的基本使用:

requests的get请求

requests的post请求

requests的代理

一般好的反扒手段,会有隐藏域,就是在源码中显示但是没有在页面中显示,每一次大的隐藏域不一样,所以得先获取源码解析出隐藏域后再给data

如果对网页有二次操作的话一定要声明一个session
代码:
import requests
# 登录古诗文网
url = '登录古诗文网'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56'
}
session = requests.session()
response = session.get(url=url,headers=headers)
#获取两个隐藏域
from lxml import etree
html = response.content.decode("utf8")
text = etree.HTML(html)
VIEWSTATE = text.xpath('//input[@id="__VIEWSTATE"]/@value')[0]
VIEWSTATEGENERATOR = text.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0]
#验证码
src=text.xpath('//img[@id="imgCode"]/@src')[0]
url_code = "https://so.gushiwen.cn"+ src
response_code = session.get(url_code)
with open('code.jpg','wb')as pt:
pt.write(response_code.content)
code = input("验证码:")
data = {
'__VIEWSTATE': VIEWSTATE ,
'__VIEWSTATEGENERATOR': VIEWSTATEGENERATOR,
'from': '登录古诗文网',
'email': '13266852809',
'pwd': '123456',
'code': code,
'denglu': '登录'
}
content = session.post(url=url,headers=headers,data=data)
with open("gushjiwen.html","w",encoding="utf8") as p:
p.write(content.text)
scrapy框架的使用:


scrapy shell的使用:
直接再cmd输入scrapy shell 网址,然后就有很多属性用

多条管道的开启:

下载多页:
还需要将allowed_domains改成域名

对第二页的内容进行访问,本页面->下一个页面
如果是访问多页的话,callback函数就是本身,如果是对访问的这个页面的下一个的话就是callback就要重写一个函数,然后通过meta传递值给函数

链接跟进:
就是使用crawlspider然后根据rules的正则表达式,满足表达式的链接就执行


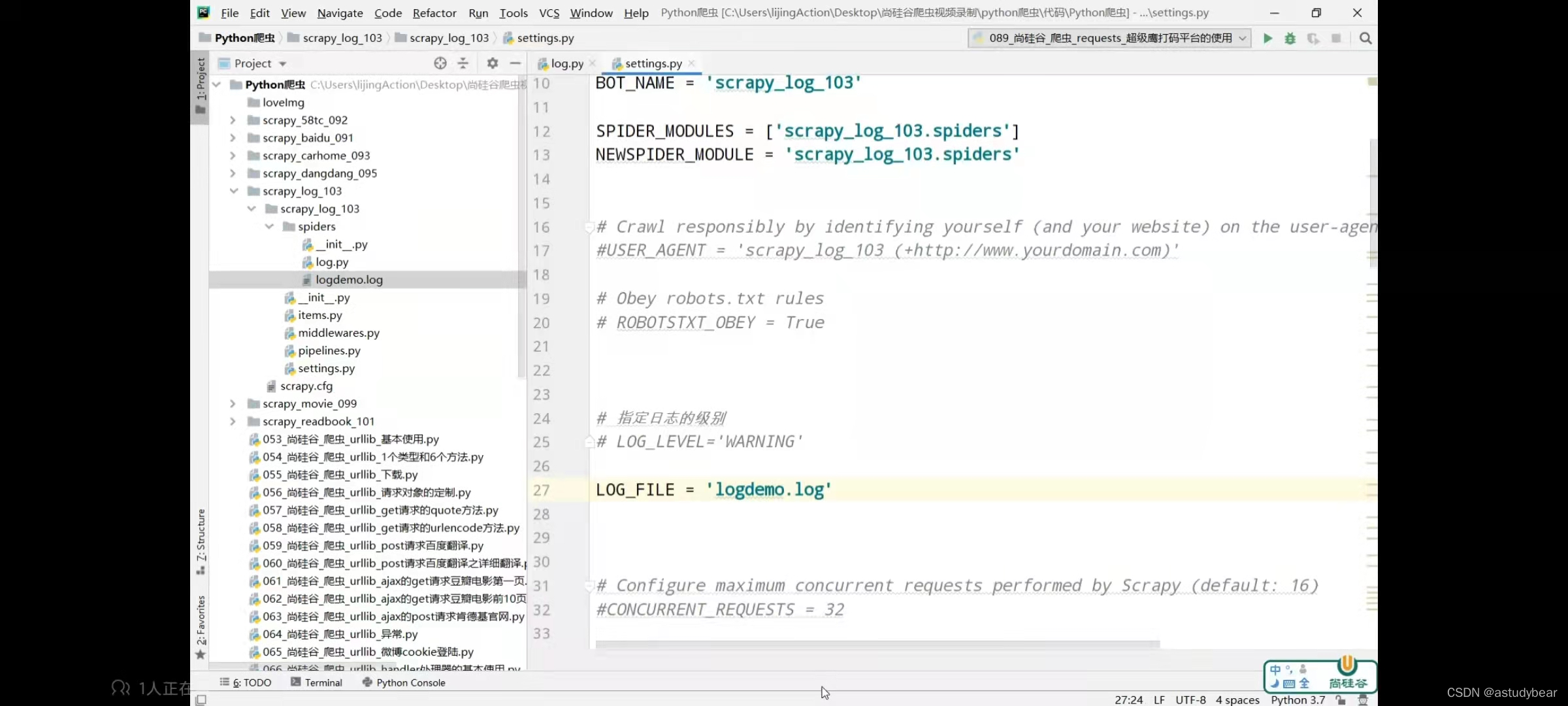
pymysql在scrapy中的使用步骤:
先开启一个管道,在settings里面开启,然后在settings里面写host、port、user、password、name、chatset这六个属性
然后在管道文件里面写一个管道,里面去读取settings和使用pymysql,读取settings的语句为settings = get_project_settings(),导入为:
from scrapy.utils.project import

链接跟进:
根据源码上的链接,在正则匹配,匹配成功就继续爬。
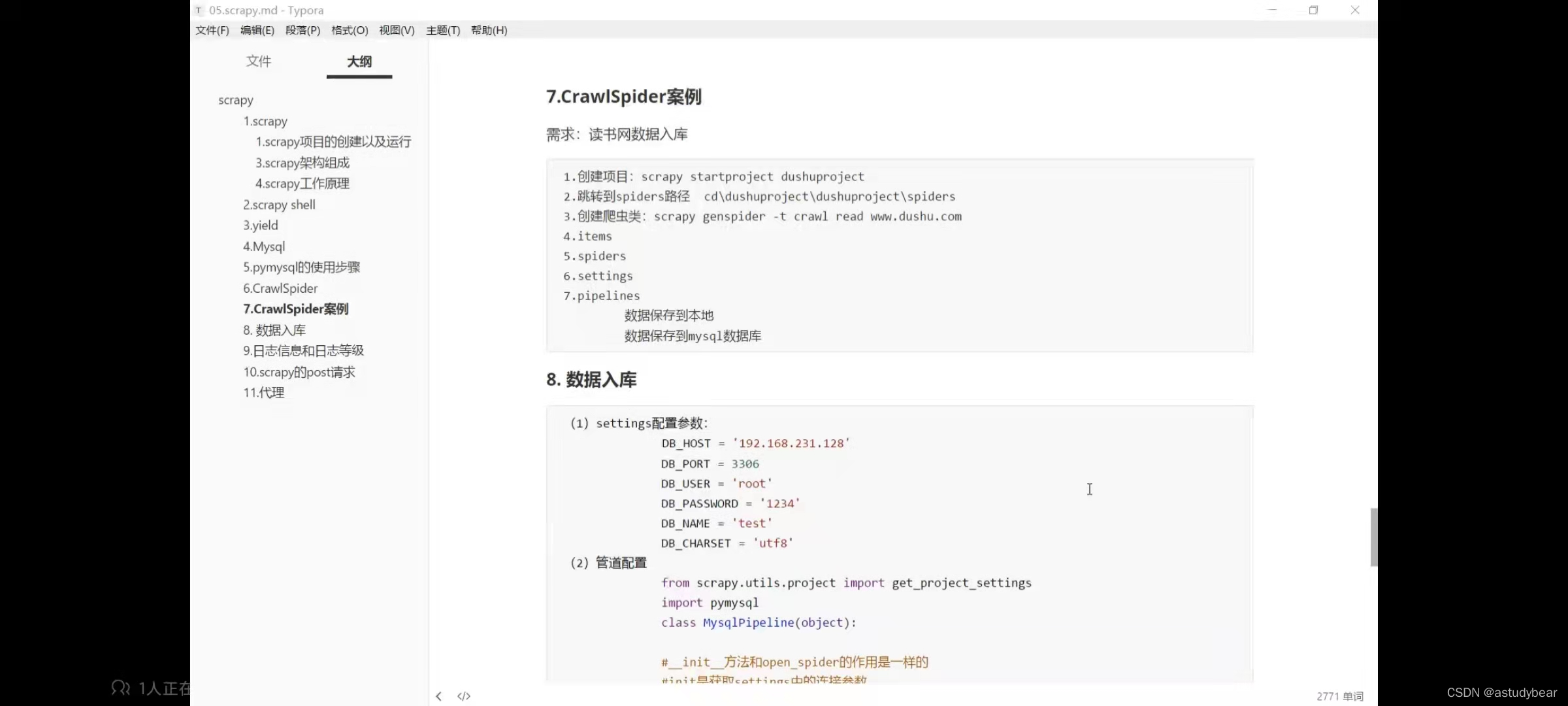

爬虫的日志想不出现在cmd中的话可以设置两个方法,一个是设置日志级别一个是设置日志输出位置(推荐):

scrapy的post请求:


















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









