




 本文详细探讨了MySQL数据库性能优化的关键因素,包括合理设计数据库结构(遵循范式)、选择合适的存储引擎(InnoDB与MyISAM对比)、优化SQL语句、调整数据库参数、服务器硬件与操作系统配合,以及分库分表、主从复制和硬件调优技巧。
本文详细探讨了MySQL数据库性能优化的关键因素,包括合理设计数据库结构(遵循范式)、选择合适的存储引擎(InnoDB与MyISAM对比)、优化SQL语句、调整数据库参数、服务器硬件与操作系统配合,以及分库分表、主从复制和硬件调优技巧。
|
学生信息 |
|
张三,23,180,2019-04-01 |
|
李四,26,167,2019-04-01 |
|
王五,23,182,2019-04-01 |
:每一行可以拆分为:‘姓名’,‘年龄’,
‘身高’,‘出生日期’四个字段,每个字段有各自对应的数据类型。例子中对应‘字符’,‘数字’,‘数字’,‘日期’类型;
正确例子:
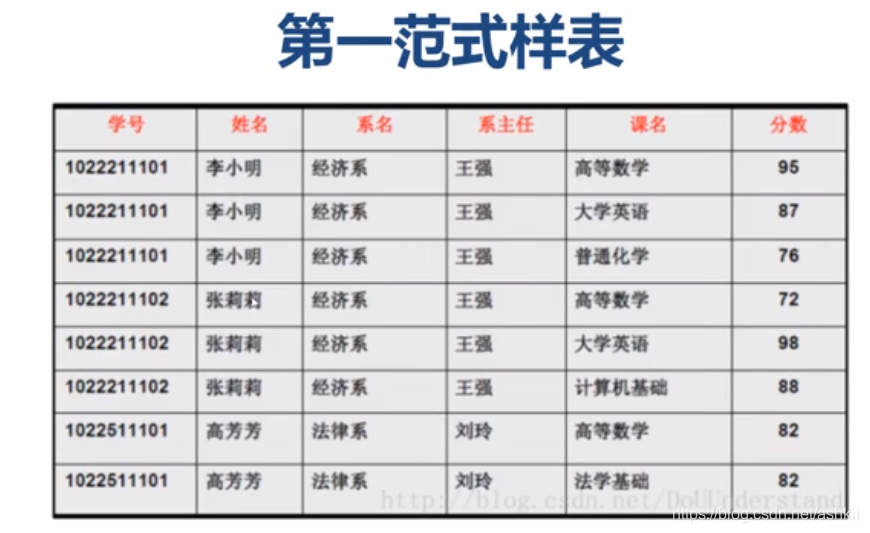
注意:此时数据存在大量重复的数据,比如:张莉莉出现了多次,同时这张表出现了新增异常,修改异常,删除异常的问题
插入异常:假设三月份学校学校开了系名,但是到九月份才开始招生,这时候只有一部分有数据,只有系名却没有学生姓名与分数等信息,这叫做插入异常
修改异常:加入李小明同学需要从经济系转到法律系,此时系主任也要从王强改为刘玲才行,这叫做修改异常、
删除异常:加入高芳芳同学需要转学,此时删除高芳芳同学会把法律系也被删除,此时学校没有了法律系了,这种情况叫做删除异常
此时需要引入第二范式
2、第二范式:
①要求符合第一范式
②表必须有一个主键(一列或多列)
③其他字段可由主键确定
④二范式目的是通过拆表减少数据冗余
二范式正确例子
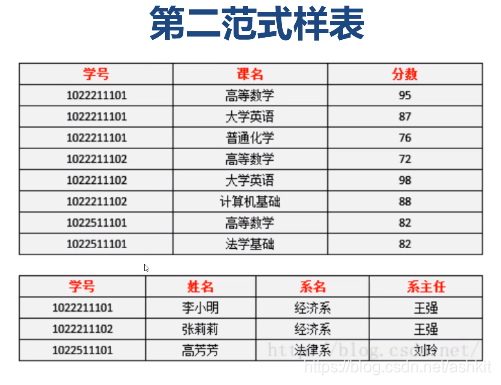
二范式不能解决删除异常,插入异常,修改异常的问题,此时需要第三范式
3、第三范式:
①要求符合第二范式
②字段要求直接依赖主键,不允许间接依赖
③第三范式目的在于拆分实体(完善主从表)
三范式正确例子
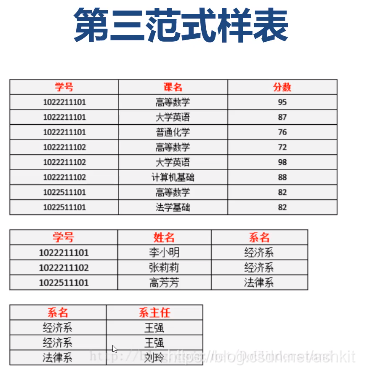
数据三范式各自的目的:
第一范式:每个字段的数据不能再被拆分
第二范式:通过超表的方式减少数据冗余
第三范式:通过分析实体的关系来形成主表与从表
采用一些反范式的设计可以减少SQL的复杂度,提高SQL执行效率
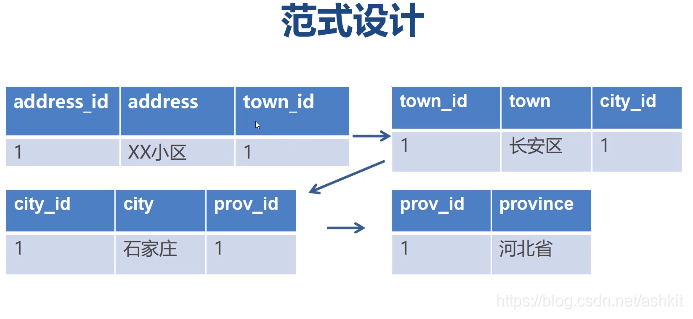
如果我要提取,省,市,县需要这样写:
SELECT
a.* , p.province , c.city , t.town
FROM
address a, province p, city c, town t
WHERE
a.town_id = t.town_id and
t.city = c.city and
c.prov_id = p.prov_id
如果采用反范式设计可以这样设计:
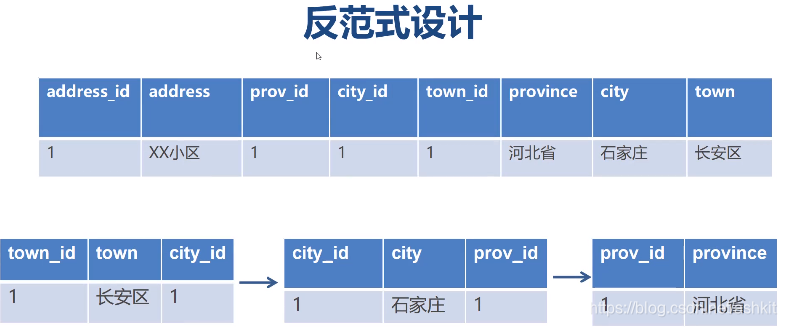
SELECT a.* FROM address a
反范式就是有意识地增加一些冗余数据,来降低SQL语句的复杂度,使得维护更加轻松
反范式优缺点:
①单表查询易于优化,易于管理
②SQL语句简单,有利于程序开发,团队协作
③存在数据冗余,写操作需要额外更新从表数据
(例如上图中长安区改成天河区,需要改两张表才能保证数据的一致性)
④不合理的反范式设计会让表变得臃肿不堪
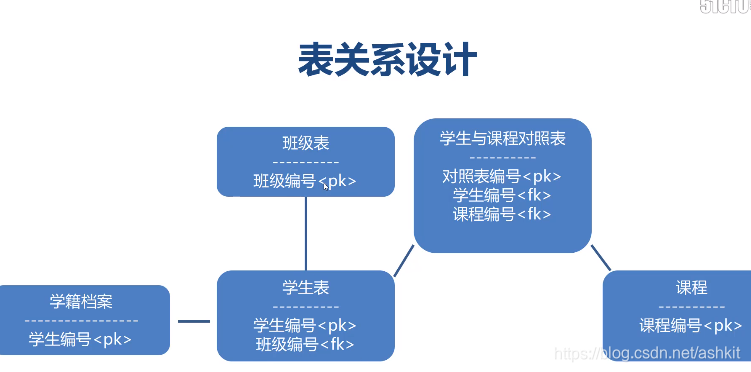
⑶实体关系分析
⒈实体关系是指系统事物之间的联系
⒉实体关系需要双向分析
⒊实体关系决定表
实体之间的关系
①一对一
②一对多
③多对多
表关系设计
①一对一,通过主键关联
②一对多,在多的一方设置外键
③多对多,增加中间表,持有双方外键
|
列类型
|
存储空间
|
取值范围
| |
|
tinyint
|
1字节
|
-128~127
| |
|
smallint
|
2字节
| ||
|
mediumint
|
3字节
| ||
|
int
|
4字节
| ||
|
bigint
|
8字节
| ||
|
列类型
|
存储空间
|
是否精确类型
|
|
FLOAT
|
4个字节
|
否
|
|
DOUBLE
|
8个字节
|
否
|
|
DECIMAL
|
每4个字节存9个数字,小数点占一个字节
|
是
|

|
职责分类
|
粒度分类
|
|
共享锁-读锁(这个数据被所有进程访问)
|
行级锁
|
|
独占锁(排他锁)-写锁(当某个线程获得了某一条数据,其他所有线程都要等待前面的线程释放锁才能访问数据)
|
表级锁
|
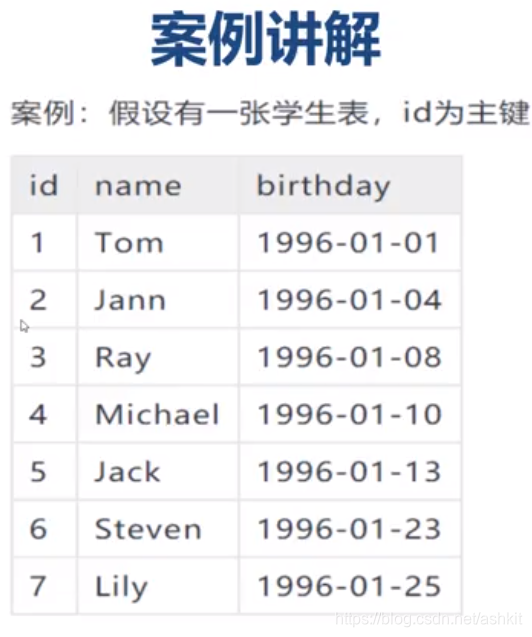
如果我要获取主键 2~4的数据,则需要从主键1找到主键7才能确定我们要找的数据,这是最差的情况,使用全表扫描
为了避免全表扫描:可以在id上创建B+Tree索引,那么表在InnoDB引擎中的存储结构如下:
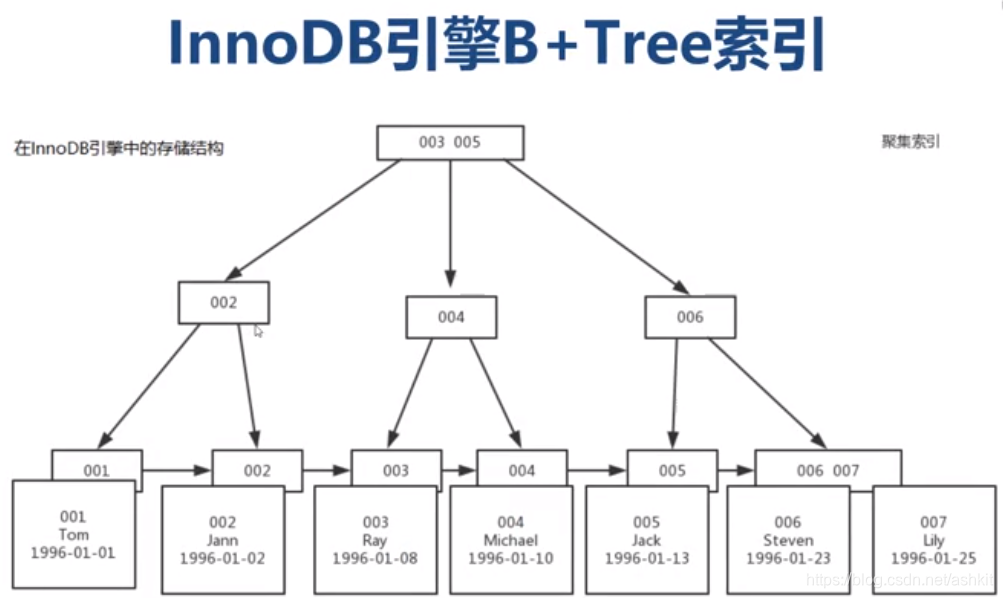
到这里就知道了为什么B+Tree适合范围查询了,是因为在底层B+Tree对数据进行的聚集排列,按照数据的顺序进行了组织,这样一来我们查找2~4的数据就可以快速找到
如果在一个表中建立了多个索引,在索引中是如何做到的?
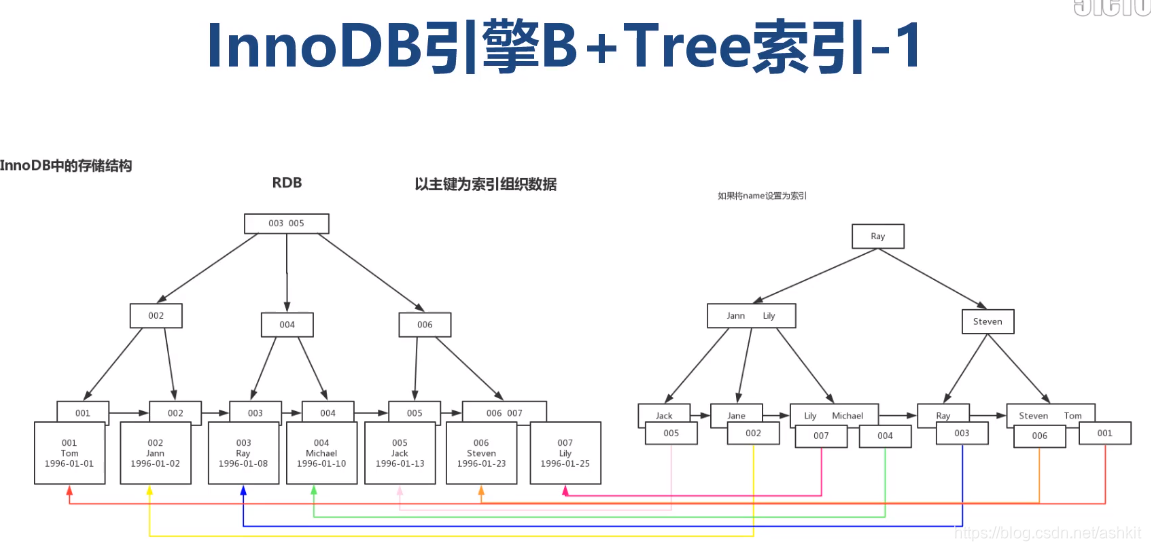
首先以id主键作为数据的物理组织形式,按照主键的顺序对数据进行前后排列。假设在name名称上建立索引
为什么官方推荐使用自增主键作为索引?
因为自增长主键每次添加的值都是最大的,所以直接在最后添加数据,如果使用其他字段作为索引,每次插入数据都要重新组织索引,非常的麻烦
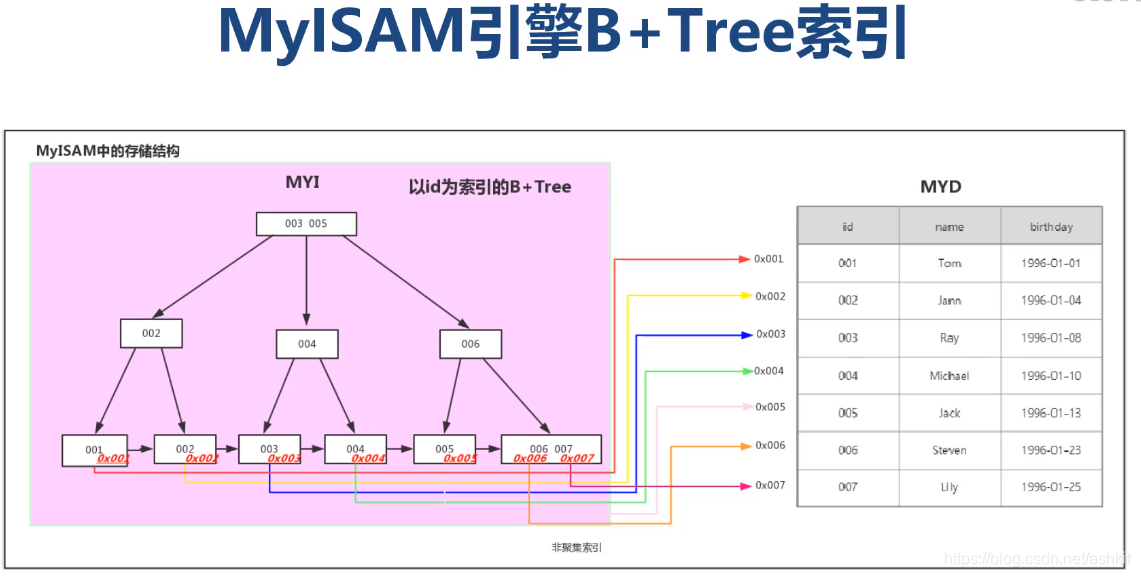
MyISAM引擎B+Tree索引
|
fname
|
lname
|
|
Arjen
| Lentz |
|
Baron
|
Schwartz
|
|
Peter
|
Zaitsev
|
|
Vadim
|
Tkachenko
|
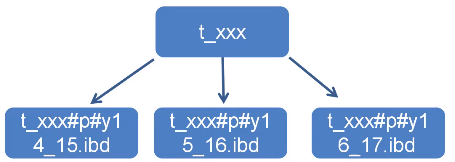
分区表的优点
①更少的数据检索范围
②拆分超级大的表,将部分数据加载至内存
③分区表的数据更容易维护
④分区表数据文件可以分布在不同的硬盘上,并发IO
⑤减少锁的范围,避免大表锁表
⑥可独立备份,恢复分区数据
创建分区表的语法:
DROP TABLE test_partition;
CREATE TABLE test_partition(
id INT(11) NOT NULL,
create_time DATETIME NOT NULL,
cyear INT,
PRIMARY KEY (id,create_time,cyear)
)ENGINE = INNODB DEFAULT CHARSET = utf8
PARTITION BY RANGE (cyear)
(
PARTITION y14before VALUES LESS THAN(2014),
PARTITION y14_15 VALUES LESS THAN(2015),
PARTITION y15_16 VALUES LESS THAN(2016),
PARTITION y16_17 VALUES LESS THAN(2017),
PARTITION y17_18 VALUES LESS THAN(2018),
PARTITION y18_19 VALUES LESS THAN(2019),
PARTITION y19_20 VALUES LESS THAN(2020),
PARTITION y20after VALUES LESS THAN maxvalue ENGINE = INNODB);
分区表的使用限制:
①查询必须包含分区列,不允许对分区列进行计算
②分区列必须是数字类型
③分区表不支持建立外键索引
④建表时主键必须包含所有的列
⑤最多1024个分区
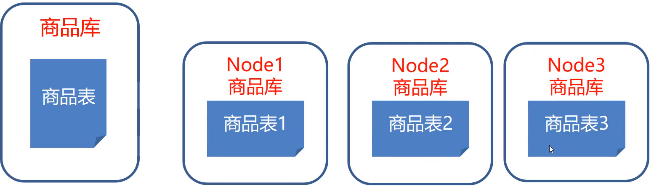
分库分表介绍
①将数据库存放在多台MySQL服务器
②缺点:数据分布不均匀,未能根本解决海量数据存储问题
数据分表:将一张大数据量的表分解成几张表,每张表的结构都一样,通过一定算法来
分库分表中间件:
|
支持分库 |
支持分表 |
中间层 |
开元 |
数据库支持 |
支持语言 |
跟新频率 | |
|
MyCat |
支持 |
支持 |
是 |
是 |
MySQL |
任意 | |
|
Cobar |
支持 |
不支持 |
是 |
是 |
MySQL |
任意 | |
|
Altlas |
支持 |
支持 |
是 |
是 | MySQL |
任意 | |
|
TDDL |
支持 |
支持 | 否 | 是 |
任意 |
Java | |
|
OneProxy |
支持 |
支持 |
是 |
否 |
MySQL |
任意 | |
|
Sharding SPhere |
支持 |
支持 |
否 |
是 |
任意 |
Java |
Sharding Sphere 介绍
Sharding Sphere 分库分表框架入门
Sharding Sphere结构:
①Sharding Sphere是一套开源的分布式数据库中间件解决方案组成的生态圈
②Sharding Sphere前身是ShardingJDBC
③Sharding Sphere是为数不多的国产活跃的数据库中间件
④目前最新版本4.X
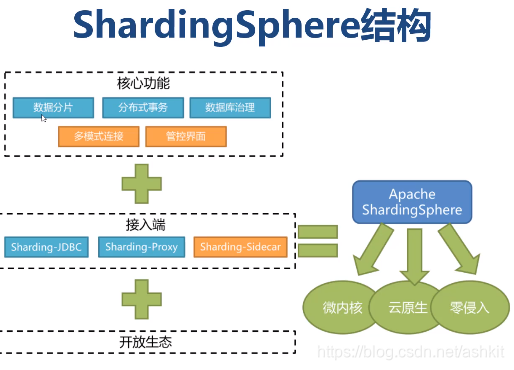
Sharding-JDBC:
①定位为轻量级Java框架,在Java的JDBC层提供的额外服务
②他使用客户端直连数据库,以jar形式提供服务
③可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架
Sharding - JDBC分库分表配置
Sharding-JDBC分库分表
<sharding:inline-strategy id="databaseStrategy" sharding-column="user_id"
algorithm-expression="ds$->{user_id % 2}"/>
<sharding:inline-strategy id="orderTableStrategy" sharding-column="order_id" algorithm-expression="t_order_$->{order_id % 2}"/>
<sharding:key-generator id="orderKeyGenerator" type="SNOWFLAKE" column="order_id"/>
<sharding:data-source id="shardingDataSource">
<!--
sharding:sharding-rule定义分表规则:
data-source-names="ds0,ds1" 说明有几个数据源
sharding:table-rule 节点定义数据存储规则
logic-table="t_order" 代表逻辑表名
actual-data-nodes="ds$->{0..1}.t_order_$->{0..1}"
说明数据分布在ds0与ds1两个数据源,物理表存在t_order_0与t_order_1
database-strategy-ref="databaseStrategy" 说明order表分库策略
基于order.user_id值对2取余保存到ds0或ds1的数据库中
table-strategy-ref="orderTableStrategy"
基于order.order_id对2取余决定存储在对应数据库的 t_order_0或者t_order_1表中
实例:
insert into t_order(order_id , user_id,status) values( ? , ? , 'N')
order_id user_id
1 2 -> ds0.order_1
2 2 -> ds0.order_0
3 1 -> ds1.order_1
4 1 -> ds1.order_0
-->
<sharding:sharding-rule data-source-names="ds0,ds1">
<sharding:table-rules>
<sharding:table-rule logic-table="t_order"
actual-data-nodes="ds$->{0..1}.t_order_$->{0..1}"
database-strategy-ref="databaseStrategy"
table-strategy-ref="orderTableStrategy"
key-generator-ref="orderKeyGenerator"
/>
</sharding:table-rules>
</sharding:sharding-rule>
</sharding:data-source>
主多从数据同步
①修改MySQL配置文件my.ini,将server_id 设置成唯一的值
②在MySQL实力中设置
主服务器配置:
#'salve'@'本机IP地址'
#salve 是用户名 后面 salve 是密码
#‘IP地址’是允许访问的远程IP地址,这里写从属服务器的IP
create user 'salve'@'IP地址' IDENTIFIED by 'salve';
#为salve 用户授予主从复制的权限
grant replication salve on *.* to 'salve'@'IP地址';
#激活权限
flush privileges;
show master status;
show binlog events in ‘mysql-bin.000001’;
从服务器配置:
CHANGE MASTER TO
MASTER_HOST=‘主机服务器IP’,
MASTER_PORT=3307,
MASTER_USER=‘salve’,
MASTER_PASSWORD=‘salve’
MASTER_LOG_FILE=‘mysql-bin.000001’,
MASTER_LOG_POS=951;
start salve;
show salve status;
ShardingJDBC配置读写分离
①引入ShardingJDBC的JAR包
②配置多个数据源,主从服务器,以及ShardingJDBC读写数据库
第五章、MySQL服务器与硬件调优
设置MySQL应用参数的三种方式
①set[session]参数名=参数值;#设置当前会话(连接)参数
#set session 代表在当前会话(窗口/连接)才有效,关闭会话后自动失效
#参数设置的优先级 session > global >配置文件
②set global 参数名 = 参数值;#设置全局参数
#set global 在MySQL服务器运行过程中会一直生效,知道MySQL关闭
#值得注意的是:部分参数在set global 并不会立即生效,需要重新建立连接后才会有效
③设置应用配置文件:
. window 将存放到my.ini 应用程序根目录
. Linux 保存在/etc/my.conf
#在MySQL安装路径上创建my.ini文件,打开配置如下:
[mysqld]
port = 3307
max_connection = 100
重启MySQL;
Connection 连接参数
#max_connections 代表数据库同时允许的最大允许连接数
#连接有两种常见的状态:sleep / query
#sleep 代表连接处于闲置状态
#query 代表连接正处于处理任务的状态
#sleep + query 连接的总量不能超过max_connections的设置值
#否则会出现经典错误:"ERROR 1040:TOO many connections"
show VARIABLES like 'max_connections'
set global max_connections = 300;
show status like 'Threads%';
#Threads_connected 代表当前已经有多少连接(sleep + query)
#Threads_created 代表历史总共创建过多少数据库连接
#Threads_running 代表有几个连接正处在“工作”状态吗,也是目前的并发数
#Threads_cached
共缓存过多少连接,如果我们在MySQL服务器配置文件中设置了thread_cache_size ,当客户端断开之后
,服务器处理此客户的线程将会缓存起来以响应下一个客户而不是销毁(前提是缓存数未达上限)
set global thread_cache_size = 80;#代表数据库最大允许缓存80个数据库连接,超出80个之后就是关闭了再重建
#MySQL 历史运行过程中最大连接的数量及时点
show status like ‘Max_used_connections%’;
参数back_kog: 设置保存多少数据库请求到堆栈(缓冲区)中,
#也就是说,如果MySQL的连接数达到max_connections时,新来的请求将会被存到堆栈中,以等待某一连接释放资源,该堆栈的数量即
back_log,如果等待连接的数量超过back_log,将不会授予连接资源。将会报:
unauthenticated user | xxx.xxx.xxx.xxx | NULL | Connect | NULL | login | NULL 的呆连接进程时。
参数:wait_timeout和interactive_timeout
#这两个参数都是至超过一段时间后,数据库连接自动关闭(默认28800秒,即8小时)
#interactive_timeout针对交互式连接,wait_timeout针对非交互式连接。
#说得直白一点,通过MySQL 客户端连接数据库是交互式连接,通过jdbc连接数据库是非交互式连接
show variables like 'wait_timeout';
show variables like 'interactive_timeout';
show processlist;
#查看当前数据库连接的数据库信息
查询缓存(QC)参数设置
查询缓存(Query Cache)
①使用查询缓存,MySQL将查询结果存放在缓存区(内存)中
②今后对同样的select 语句(区分大小写),将直接从缓冲区中读取结果。
set global query_cache_size = 1024000000;
show status like 'Qcache%';
#Qcache_free_memory:Quert Cache
中目前剩下的内存大小。通过这个参数我们可以较为准确的观察当前系统中的Query
Cache内存大小是否足够,是需要增多还是过多了。
#Qcache_lowmen_prunes :多少条Query 因为内存不足而被清除出Query Cache
通过 Qcache_lowmen_prunes 和 Qcache_free_memory
相互结合,能够更清楚的了解到我们系统中Query Cache 的内存大小是否真的足够,是否非常频繁地出现因为内存不足而有Query被换 出。这个数字最好是长时间来看,如果这个数字在不断增长,就表示可能碎片化非常严重,或者内存很少
#Qcache_total_blocks:当前Query Cache中block的数量
#Qcache_free_blocks:缓存中相邻内存块的个数。如果该值显示过大,则说明Query
Cache中的内存中的碎片较多了
#查询缓存碎片率:QCache_free_block/Qcache_total_block*100%
#如果查询缓存碎片率超过20%,可以用flush query cache 整理碎片
#block默认是4KB,设置大小对大数据查询有好处,但是如果查询的都是小数据查询,就容易造成内存碎片和浪费。
#Qcache_hits:表示有多少次命中缓存。我们主要可以通过该值来验证我们查询能缓存的效果,
数字越大缓存效果月理想
#Qcache_inserts: 表示多少次未命中而插入,意思是新来的SQL请求缓存中未找到,不得不执行查询处理,执行查询处理后把结果inset带 查询缓存中。这样的情况越多,表示查询缓存应用到的比较少,效果也就不理想。
#Qcache_queries_in_cache: 当前Query Cache 中cache的Query数量
#Qcache_queries_in_cache: 当前缓存中缓存的查询数量
#Qcache_not_cached:未进入查询的select个数

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









