



舌诊 AI 分析(文章末尾补充了实时视频检测,验证稳定性)


技术分享
# 实现思路
# 分割模型
import torch
import torch.nn as nn
# SCSE 注意力模块:通道注意力 + 空间注意力
class SCSEBlock(nn.Module):
def __init__(self, in_channels):
super(SCSEBlock, self).__init__()
# 通道注意力分支
self.channel_excitation = nn.Sequential(
nn.AdaptiveAvgPool2d(1), # 全局平均池化
nn.Conv2d(in_channels, in_channels // 16, kernel_size=1), # 降维
nn.LeakyReLU(inplace=True), # LeakyReLU 激活
nn.Conv2d(in_channels // 16, in_channels, kernel_size=1), # 升维
nn.Sigmoid() # Sigmoid 激活生成通道权重
)
# 空间注意力分支
self.spatial_excitation = nn.Sequential(
nn.Conv2d(in_channels, 1, kernel_size=1), # 生成空间注意图
nn.Sigmoid()
)
def forward(self, x):
chn_se = self.channel_excitation(x) # 通道注意力
spa_se = self.spatial_excitation(x) # 空间注意力
return x * chn_se * spa_se # 同时作用于输入
# 残差双卷积模块(可选 SCSE 注意力)
class ResidualDoubleConv(nn.Module):
def __init__(self, in_channels, out_channels, use_scse=False, dropout_rate=0.2):
super(ResidualDoubleConv, self).__init__()
self.use_scse = use_scse
self.same_channels = (in_channels == out_channels)
# 主路径卷积层(两层3x3卷积 + BN + LeakyReLU)
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels)
)
# 如果输入输出通道不一致,调整残差路径
self.residual = nn.Identity() if self.same_channels else nn.Conv2d(in_channels, out_channels, kernel_size=1)
# 可选的 SCSE 注意力模块
if use_scse:
self.scse = SCSEBlock(out_channels)
# 可选的 Dropout(在解码器使用)
self.dropout = nn.Dropout2d(p=dropout_rate) if dropout_rate > 0 else nn.Identity()
self.relu = nn.LeakyReLU(inplace=True) # 使用 LeakyReLU 替代 ReLU
def forward(self, x):
identity = self.residual(x) # 残差路径
out = self.conv(x) # 主路径卷积
if self.use_scse:
out = self.scse(out) # 加 SCSE 注意力
out = self.dropout(out) # 加 Dropout(防过拟合)
out += identity # 残差相加
return self.relu(out) # 激活输出
# ResUNet 主体结构
class ResUNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1, use_attention=True, base_channels=16, max_channels=512,
dropout_rate=0.2):
super(ResUNet, self).__init__()
# 逐层计算通道数,控制上限不超过 max_channels
c1 = base_channels
c2 = min(c1 * 2, max_channels)
c3 = min(c2 * 2, max_channels)
c4 = min(c3 * 2, max_channels)
c5 = min(c4 * 2, max_channels) # bottleneck 层通道
# 编码器部分
self.enc1 = ResidualDoubleConv(in_channels, c1, use_scse=use_attention)
self.pool1 = nn.MaxPool2d(2)
self.enc2 = ResidualDoubleConv(c1, c2, use_scse=use_attention)
self.pool2 = nn.MaxPool2d(2)
self.enc3 = ResidualDoubleConv(c2, c3, use_scse=use_attention)
self.pool3 = nn.MaxPool2d(2)
self.enc4 = ResidualDoubleConv(c3, c4, use_scse=use_attention)
self.pool4 = nn.MaxPool2d(2)
self.bottleneck = ResidualDoubleConv(c4, c5, use_scse=use_attention)
# 解码器部分(每层加入 Dropout)
self.up4 = nn.ConvTranspose2d(c5, c4, kernel_size=2, stride=2)
self.dec4 = ResidualDoubleConv(c4 * 2, c4, use_scse=use_attention, dropout_rate=dropout_rate)
self.up3 = nn.ConvTranspose2d(c4, c3, kernel_size=2, stride=2)
self.dec3 = ResidualDoubleConv(c3 * 2, c3, use_scse=use_attention, dropout_rate=dropout_rate)
self.up2 = nn.ConvTranspose2d(c3, c2, kernel_size=2, stride=2)
self.dec2 = ResidualDoubleConv(c2 * 2, c2, use_scse=use_attention, dropout_rate=dropout_rate)
self.up1 = nn.ConvTranspose2d(c2, c1, kernel_size=2, stride=2)
self.dec1 = ResidualDoubleConv(c1 * 2, c1, use_scse=use_attention, dropout_rate=dropout_rate)
self.conv_last = nn.Conv2d(c1, out_channels, kernel_size=1) # 最后输出层
# 使用nn.BCEWithLogitsLoss() 内部会自动做 Sigmoid
# self.activation = nn.Sigmoid() # 输出归一化到 [0, 1](适用于二分类)
def forward(self, x):
# 编码器前向传播 + 跳跃连接
x1 = self.enc1(x)
p1 = self.pool1(x1)
x2 = self.enc2(p1)
p2 = self.pool2(x2)
x3 = self.enc3(p2)
p3 = self.pool3(x3)
x4 = self.enc4(p3)
p4 = self.pool4(x4)
bn = self.bottleneck(p4) # bottleneck 层
# 解码器前向传播,拼接跳跃连接特征
u4 = self.up4(bn)
u4 = torch.cat([u4, x4], dim=1)
d4 = self.dec4(u4)
u3 = self.up3(d4)
u3 = torch.cat([u3, x3], dim=1)
d3 = self.dec3(u3)
u2 = self.up2(d3)
u2 = torch.cat([u2, x2], dim=1)
d2 = self.dec2(u2)
u1 = self.up1(d2)
u1 = torch.cat([u1, x1], dim=1)
d1 = self.dec1(u1)
out = self.conv_last(d1) # 输出层卷积
# return self.activation(out) # 使用 Sigmoid 激活做归一化(适合二分类)
return out
# 分类模型
import torch
import torch.nn as nn
from torchvision.models import efficientnet_b0, EfficientNet_B0_Weights
class MultiTaskEfficientNetB0(nn.Module):
def __init__(self, pretrained=True):
super(MultiTaskEfficientNetB0, self).__init__()
weights = EfficientNet_B0_Weights.IMAGENET1K_V1 if pretrained else None
base_model = efficientnet_b0(weights=weights)
# 去掉最后的分类头,只保留特征提取部分
self.backbone = base_model.features # 输出 shape: (B, 1280, 7, 7)
self.pooling = nn.AdaptiveAvgPool2d(1) # -> (B, 1280, 1, 1)
self.dropout = nn.Dropout(0.5)
# EfficientNet-B0 最后输出通道数是 1280
self.tongue_color_fc = nn.Linear(1280, 5) # 舌色(单标签)
self.tongue_quality_fc = nn.Linear(1280, 5) # 舌质(多标签)
self.coating_color_fc = nn.Linear(1280, 4) # 苔色(单标签)
self.coating_thickness_fc = nn.Linear(1280, 2) # 苔质厚薄(单标签)
self.coating_quality_fc = nn.Linear(1280, 5) # 苔质其他(多标签)
def forward(self, x):
x = self.backbone(x)
x = self.pooling(x) # -> (B, 1280, 1, 1)
x = x.view(x.size(0), -1) # -> (B, 1280)
x = self.dropout(x)
tongue_color = self.tongue_color_fc(x)
tongue_quality = self.tongue_quality_fc(x)
coating_color = self.coating_color_fc(x)
coating_thickness = self.coating_thickness_fc(x)
coating_quality = self.coating_quality_fc(x)
return tongue_color, tongue_quality, coating_color, coating_thickness, coating_quality
通过模型对图片进行预测分割,精确分割舌体部分
使用分割舌体进行舌体类别进行标注
通过标注后的数据训练舌体分类模型进行预测
一、接口概述
舌诊 AI 分析接口是基于人工智能与中医舌诊理论相结合的健康分析服务。用户只需上传或输入舌象图片 URL,接口即可完成自动识别与诊断特征提取,并输出详细的舌象分析、体质判定以及健康调理参考。
它适用于:
- 健康管理平台
- 中医养生类 APP
- 智慧诊所、远程问诊系统
- 企业健康服务、体质评估工具
二、核心功能
-
舌象自动识别
- 支持输入图片 URL 或本地上传后转 URL。
@predict_bp.route('/predict_path', methods=['POST'])
# @require_api_key # 请求验证
def predict_path():
data = request.get_json()
image_path = data.get('path')
result = process_image(image_path, seg_model, cls_model, device)
return jsonify(result)
- 自动完成舌体区域检测与裁剪,保证分析精准。
def process_image(file, seg_model, cls_model, device):
start = time.time()
# 舌体分割
tongue_rgba = extract_tongue(file, seg_model, device) # 返回掩膜
if tongue_rgba is None:
return {"error": "未检测到舌体区域"}
mid = time.time()
logger.info(f"[⏱️ 分割] 处理: {mid - start:.3f}s")
# 舌体特征识别
start1 = time.time()
result = type_tongue(tongue_rgba, cls_model, device)
result["cropTongue"] = file
mid1 = time.time()
logger.info(f"[⏱️ 分类] 处理: {mid1 - start1:.3f}s")
return result
-
舌象特征分析(tezheng 字段)
- 舌色:如红舌、淡白舌、紫舌等,并提供对应的中医解释。
- 舌形:识别齿痕、裂纹、舌刺、胖大舌、瘦薄舌等,结合对应病理意义。
- 苔色:如浅白苔、浅黄苔、深黄苔等,提示寒热虚实。
- 苔质:厚薄、腻苔、滑苔、润苔、剥苔、腐苔等,结合湿热、食积、阳气虚衰等证候。
- 每一项特征均附带置信度分值和医学解释,支持前端直观展示。
-
体质智能判定(tizhiType 字段)
-
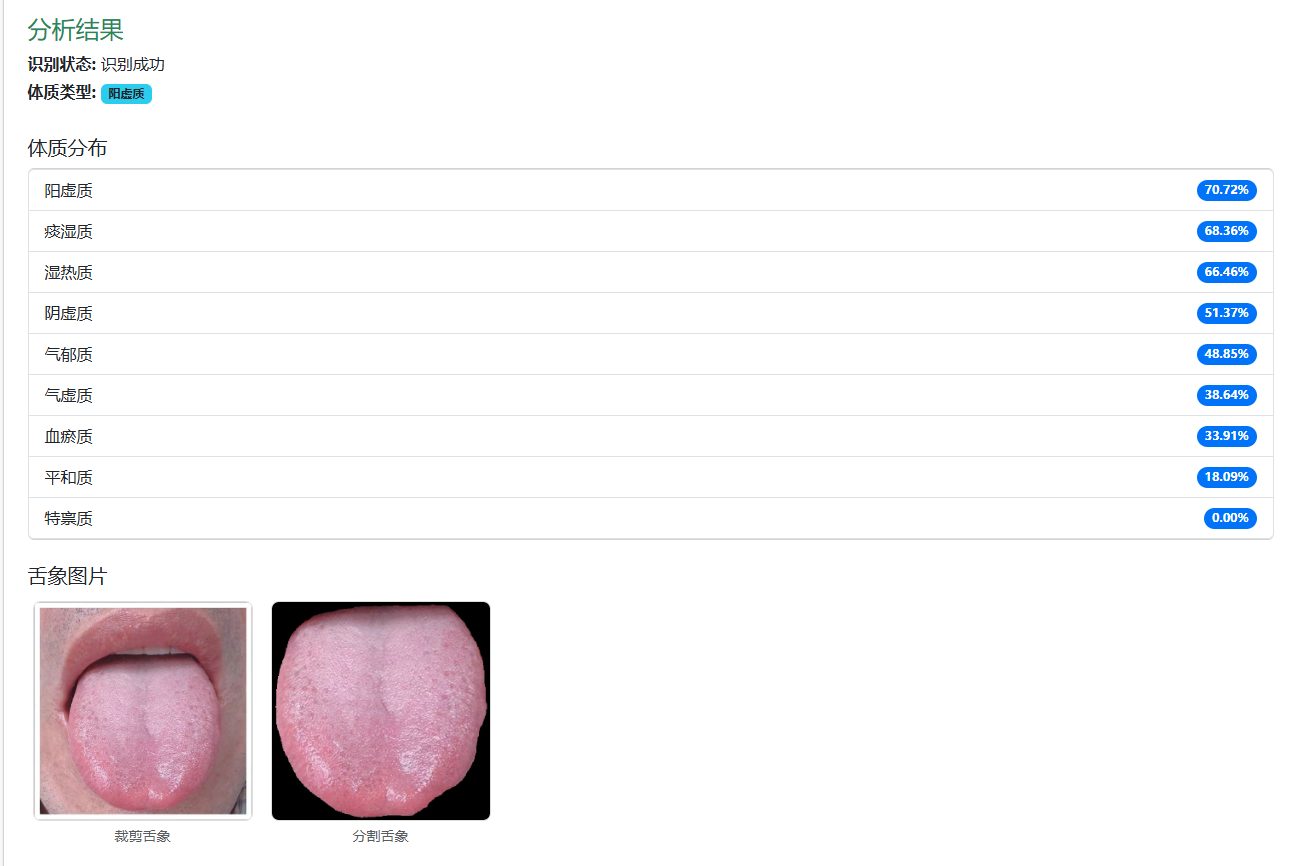
根据舌象特征结合 AI 模型综合评估,输出 9 大中医体质类型:
平和质、气虚质、阳虚质、阴虚质、痰湿质、湿热质、血瘀质、气郁质、特禀质。 -
返回结果包括:
- 主体质(tizhiType)
- 全部体质分布(tizhiDistribution),便于量化对比。
-
# 体质归一化核心
def calc_constitution_scores(
tag_probs_raw: dict,
weight_map: dict,
threshold: float = 0.5, # 过滤阈值(若想保留全部信息设为0)
method: str = "noisy_or", # "noisy_or" 或 "sum_clip"
damping: float = 0.9, # 衰减系数,防止多证据过快饱和,0.7~0.95 可调
priors: dict | None = None, # 先验,如 {'平和质': 0.05}
all_constitutions: list | None = None
):
"""返回 {体质: 分数 in [0,1]}"""
if all_constitutions is None:
all_constitutions = ['平和质', '气虚质', '阳虚质', '阴虚质',
'痰湿质', '湿热质', '血瘀质', '气郁质', '特禀质']
# 1) 过滤
tag_probs = {t: p for t, p in tag_probs_raw.items() if p > threshold}
# 2) 聚合
scores = {c: 0.0 for c in all_constitutions}
if method == "sum_clip":
# 线性加和 + 截断到1
for tag, p in tag_probs.items():
if tag in weight_map:
for c, w in weight_map[tag].items():
scores[c] = min(1.0, scores[c] + p * w)
else:
# Noisy-OR: 1 - ∏(1 - damping*w*p)
for c in all_constitutions:
factors = []
for tag, p in tag_probs.items():
if tag in weight_map and c in weight_map[tag]:
factors.append(1 - damping * weight_map[tag][c] * p)
scores[c] = 0.0 if not factors else max(0.0, min(1.0, 1 - prod(factors)))
# 3) 合并先验: s = 1 - (1 - s)*(1 - prior)
if priors:
for c, prior in priors.items():
# 与观测独立:合并为 1 - (1 - 分数)*(1 - 先验)
scores[c] = 1 - (1 - scores.get(c, 0.0)) * (1 - prior)
return {c: float(f"{v:.4f}") for c, v in scores.items()}
-
健康调理建议(tiaoli 字段)
-
提供体质对应的调养方向,包括:
- 起居调摄
- 饮食疗法
- 情志调理
- 运动锻炼
- 药食养生参考
-
可作为健康管理系统的辅助功能。
-
-
图片可视化
- 返回裁剪后的舌象图片(cropTongue)和分割后的舌象图(cutTongue),便于前端直接展示分析结果。
三、返回数据示例
接口返回标准 JSON,主要字段说明:
- message:识别状态(如“识别成功”)
- tezheng:舌色、舌形、苔色、苔质等详细特征及说明
- tizhiType:判定的主体质类型
- tizhiDistribution:9 种体质的分布概率
- tiaoli:对应体质的调养建议
- cropTongue / cutTongue:舌象图片链接
四、领域擅长
- 专业性:结合现代深度学习模型与传统中医理论,保证分析科学性。
- 智能化:实现全流程自动化,减少人工辨舌的主观差异。
- 可扩展:支持二次开发,可嵌入到移动 APP、小程序、Web 平台或硬件设备。
- 市场化:适合健康管理 SaaS、养生馆、保险健康服务平台作为增值服务。
五、实时视频流识别

间断抓取视频帧,识别结果一致

快速接入,立刻体验
只需 3 步:
- 获取 API Key
- 调用接口上传舌象图片
- 获取舌诊分析与健康报告
- 体验可留言

















 1625
1625



 到【灌水乐园】发言
到【灌水乐园】发言







