




- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境
语言环境:python 3.7.12
编译器:pycharm
深度学习环境:tensorflow 2.7.0
数据:本地数据集superstar-data
目录
一、总结
使用 TensorFlow 和 Keras 创建一个基于 VGG16 预训练模型的自定义深度学习模型并使用不同优化器。VGG16 是一个在 ImageNet 数据集上预训练过的卷积神经网络(CNN),常用于图像分类任务。通过冻结 VGG16 的基础层并添加自定义的全连接层,我们可以利用迁移学习来快速构建一个针对特定任务的模型。
代码解析
导入必要的模块
from tensorflow.keras.layers import Dropout, Dense, BatchNormalization
from tensorflow.keras.models import Model
Dropout:用于防止过拟合的技术,随机丢弃一定比例的神经元。Dense:全连接层,用于将输入数据映射到指定数量的输出单元。BatchNormalization:批量归一化层,帮助加速训练过程并提高模型稳定性。Model:Keras 中的模型类,用于定义和编译模型。
定义 create_model 函数
def create_model(optimizer='adam'):
# 加载预训练模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='avg')
for layer in vgg16_base_model.layers:
layer.trainable = False
X = vgg16_base_model.output
X = Dense(170, activation='relu')(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
output = Dense(len(class_names), activation='softmax')(X)
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return vgg16_model
1. 加载预训练的 VGG16 模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='avg')
weights='imagenet':使用在 ImageNet 数据集上预训练的权重。include_top=False:不包含 VGG16 的顶层(即全连接层),因为我们想要添加自己的分类层。input_shape=(img_width, img_height, 3):指定输入图像的尺寸,其中img_width和img_height是图像的宽度和高度,3表示 RGB 三通道。pooling='avg':在最后的卷积层之后添加全局平均池化层,将特征图压缩为固定大小的向量。
2. 冻结 VGG16 的基础层
for layer in vgg16_base_model.layers:
layer.trainable = False
- 通过设置
trainable=False,我们冻结了 VGG16 的所有层,这意味着这些层的权重在训练过程中不会更新。这样做可以保留预训练模型中已经学到的特征,同时减少训练时间和计算资源的消耗。
3. 添加自定义的全连接层
X = Dense(170, activation='relu')(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
Dense(170, activation='relu'):添加一个具有 170 个神经元的全连接层,使用 ReLU 激活函数。BatchNormalization():对前一层的输出进行批量归一化,以加速训练并提高模型的泛化能力。Dropout(0.5):应用 50% 的 Dropout,随机丢弃一半的神经元,以防止过拟合。
4. 添加输出层
output = Dense(len(class_names), activation='softmax')(X)
Dense(len(class_names), activation='softmax'):添加一个全连接层,其神经元数量等于类别数(len(class_names)),并使用 Softmax 激活函数。Softmax 会将输出转换为概率分布,适用于多分类任务。
5. 构建并编译模型
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Model(inputs=vgg16_base_model.input, outputs=output):创建一个新的模型,输入是 VGG16 的输入层,输出是我们自定义的分类层。compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy']):编译模型,指定优化器、损失函数和评估指标。这里使用sparse_categorical_crossentropy作为损失函数,适用于多分类任务,accuracy作为评估指标。
创建两个不同的模型实例,分别使用不同的优化器
model1 = create_model(optimizer=tf.keras.optimizers.Adam())
model2 = create_model(optimizer=tf.keras.optimizers.SGD())
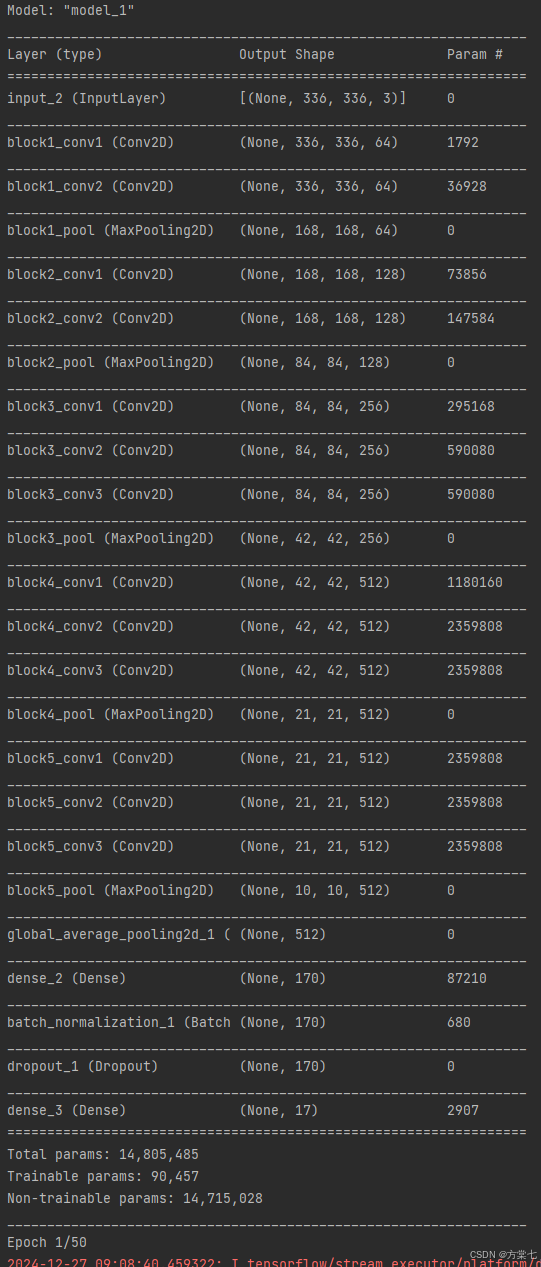
model2.summary()
model1使用 Adam 优化器,model2使用 SGD(随机梯度下降)优化器。model2.summary():打印model2的结构摘要,包括每一层的参数数量和输出形状。
关键点总结
- 迁移学习:通过加载预训练的 VGG16 模型并冻结其基础层,我们可以利用已经学好的特征提取器,只需训练自定义的分类层即可。
- 自定义分类层:我们在 VGG16 的基础上添加了一个全连接层、批量归一化层和 Dropout 层,以适应特定的分类任务。
- 优化器选择:代码中创建了两个模型实例,分别使用 Adam 和 SGD 优化器,以便比较不同优化器的效果。
- 模型编译:使用
sparse_categorical_crossentropy作为损失函数,适用于多分类任务,并使用accuracy作为评估指标。
二、实现
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
from tensorflow import keras
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import warnings,os,PIL,pathlib
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data_dir = "./superstar-data"
data_dir = pathlib.Path(data_dir)
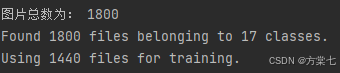
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
batch_size = 16
img_height = 336
img_width = 336
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
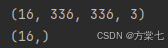
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
## 配置数据集
AUTOTUNE = tf.data.AUTOTUNE
def train_preprocessing(image,label):
return (image/255.0,label)
train_ds = (
train_ds.cache()
.shuffle(1000)
.map(train_preprocessing) # 这里可以设置预处理函数
# .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size
.prefetch(buffer_size=AUTOTUNE)
)
val_ds = (
val_ds.cache()
.shuffle(1000)
.map(train_preprocessing) # 这里可以设置预处理函数
# .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size
.prefetch(buffer_size=AUTOTUNE)
)
plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("data show")
for images, labels in train_ds.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
plt.imshow(images[i])
# 显示标签
plt.xlabel(class_names[labels[i]-1])
plt.show()
from tensorflow.keras.layers import Dropout, Dense, BatchNormalization
from tensorflow.keras.models import Model
def create_model(optimizer='adam'):
# 加载预训练模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='avg')
for layer in vgg16_base_model.layers:
layer.trainable = False #冻结了 VGG16 的所有层,这意味着这些层的权重在训练过程中不会更新
X = vgg16_base_model.output
# 添加自定义的全连接层
X = Dense(170, activation='relu')(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
#添加输出层
output = Dense(len(class_names), activation='softmax')(X)
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return vgg16_model
model1 = create_model(optimizer=tf.keras.optimizers.Adam())
model2 = create_model(optimizer=tf.keras.optimizers.SGD())
model2.summary()
NO_EPOCHS = 50
history_model1 = model1.fit(train_ds, epochs=NO_EPOCHS, verbose=1, validation_data=val_ds)
history_model2 = model2.fit(train_ds, epochs=NO_EPOCHS, verbose=1, validation_data=val_ds)
from matplotlib.ticker import MultipleLocator
plt.rcParams['savefig.dpi'] = 300 # 图片像素
plt.rcParams['figure.dpi'] = 300 # 分辨率
acc1 = history_model1.history['accuracy']
acc2 = history_model2.history['accuracy']
val_acc1 = history_model1.history['val_accuracy']
val_acc2 = history_model2.history['val_accuracy']
loss1 = history_model1.history['loss']
loss2 = history_model2.history['loss']
val_loss1 = history_model1.history['val_loss']
val_loss2 = history_model2.history['val_loss']
epochs_range = range(len(acc1))
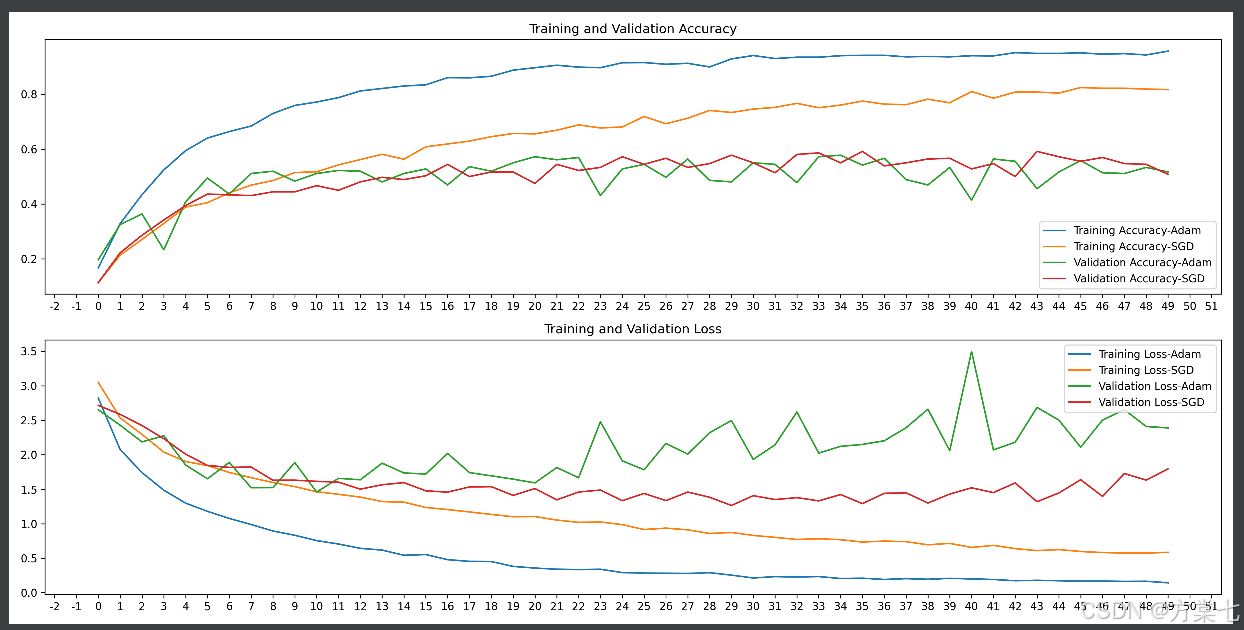
plt.figure(figsize=(16, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc1, label='Training Accuracy-Adam')
plt.plot(epochs_range, acc2, label='Training Accuracy-SGD')
plt.plot(epochs_range, val_acc1, label='Validation Accuracy-Adam')
plt.plot(epochs_range, val_acc2, label='Validation Accuracy-SGD')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
# 设置刻度间隔,x轴每1一个刻度
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss1, label='Training Loss-Adam')
plt.plot(epochs_range, loss2, label='Training Loss-SGD')
plt.plot(epochs_range, val_loss1, label='Validation Loss-Adam')
plt.plot(epochs_range, val_loss2, label='Validation Loss-SGD')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
# 设置刻度间隔,x轴每1一个刻度
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
plt.show()
## 模型评估
def test_accuracy_report(model):
score = model.evaluate(val_ds, verbose=0)
print('Loss function: %s, accuracy:' % score[0], score[1])
test_accuracy_report(model2)
三、结果






















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









