




 LogiRE是一种新型的概率模型,通过学习逻辑规则来提取文档中的关系,解决了神经网络模型的不透明性问题。模型由规则生成器和关系提取器组成,两者通过EM算法协同优化。实验证明,LogiRE在关系性能和逻辑一致性上优于其他基线,提供更好的解释性并能显式捕获远程依赖关系。
LogiRE是一种新型的概率模型,通过学习逻辑规则来提取文档中的关系,解决了神经网络模型的不透明性问题。模型由规则生成器和关系提取器组成,两者通过EM算法协同优化。实验证明,LogiRE在关系性能和逻辑一致性上优于其他基线,提供更好的解释性并能显式捕获远程依赖关系。
摘要
文档级关系提取旨在识别整个文档中实体之间的关系。先前捕获远程依赖关系的努力严重依赖于通过(图)神经网络学习的隐式强大表示,这使得模型不太透明。为了解决这一挑战,本文提出了LogiRE,这是一种通过学习逻辑规则来提取文档级关系的新型概率模型。LogiRE将逻辑规则视为潜在变量,由两个模块组成:规则生成器和关系提取器。规则生成器生成可能有助于最终预测的逻辑规则,关系提取器根据生成的逻辑规则输出最终预测。利用期望最大化(EM)算法可以对这两个模块进行有效的优化。通过将逻辑规则引入神经网络,LogiRE可以显式地捕获远程依赖关系,并获得更好的解释。实证结果表明,LogiRE在关系性能(~ 1.8 F1分数)和逻辑一致性(超过3.3逻辑分数)方面显著优于几个强基线。我们的代码可在https://github上获得。com/rudongyu/LogiRE。
介绍

图1:利用规则进行关系标识的示例。这三个带标签的句子分别描述了royalty_of(Harry,UK)、sibling_of(William,Harry)和spouse (Kate,William)的关系。关系royalty_of(Kate,UK)的识别需要在三句话中综合信息。它可以很容易地从证明的规则和其他三个关系中推导出来。
从文档中提取关系是信息抽取(information extraction, IE)中的一个重要研究方向。最近,人们不再关注句子层面(Socher et al., 2012;dos Santos等人,2015;Han et al., 2018;Zhang et al., 2018;Wang et al., 2021a,b),研究人员已经转向直接在文档层面建模(Wang et al., 2019;Ye et al., 2020;Zhou et al., 2021),它提供了更长的上下文,需要更复杂的推理。早期的工作主要集中在学习一个强大的关系(即实体对)表示,它隐式地捕获远程依赖关系。根据输入结构,我们可以把现有文档级关系提取工作分为两类:基于序列的模型和基于图的模型。
基于序列的模型首先利用不同的序列编码器(例如BERT (Devlin等人,2019),RoBERTa (Liu等人,2019))获得token表示,然后通过各种池化操作计算关系表示,例如平均池化(Yao等人,2019);Xu et al., 2021),细心池化(Zhou et al., 2021)。为了进一步捕获远程依赖关系,提出了基于图的模型。通过构造图,距离较远的词或实体可以成为相邻节点。在序列编码器之上,图形编码器(例如,GNN)可以聚合来自所有邻居的信息,从而捕获更长的依赖关系。提出了各种形式的图,包括依赖树(Peng et al., 2017;Zhang 1240等人,2018),共同参考图(Sahu等人,2019),提及实体图(Christopoulou等人,2019;Zeng et al., 2020),实体-关系二部图(Sun et al., 2019)等。尽管它们取得了巨大的成功,但人们对内部表征仍然没有全面的了解,它们经常被批评为神秘的“黑盒子”。
学习逻辑规则可以发现和表示知识在明确的符号结构,可以被人理解和检查。同时,逻辑规则提供了另一种显式捕获文档中实体和输出关系之间交互的方法。例如,在图1中,royalty_of(Kate,UK)的识别需要所有三个句子中的信息。所证明的逻辑规则可以直接从每个句子中局部提取的三个关系中获得这个关系。对规则的推理绕过了捕获长期依赖关系的困难,并用内在相关性解释结果。如果模型能够自动学习规则并利用它们进行预测,那么我们将获得更好的关系提取性能和更多的解释。
在本文中,我们提出了一种新的概率模型LogiRE,它通过逻辑规则来描述关系之间的内在相互作用。受RNNLogic (Qu et al., 2021)的启发,我们将逻辑规则视为潜在变量。具体地说,LogiRE由一个规则生成器和一个关系提取器组成,它们同时经过训练以相互增强。规则生成器提供逻辑规则供关系提取器用于预测,关系提取器提供一些监督信号来指导规则生成器的优化,从而大大减少了搜索空间。此外,所提出的关系提取器是模型不可知的,因此它可以用作任何现有关系提取器的即插即用技术。EM算法可以有效地优化这两个模块。通过在神经网络中引入逻辑规则,LogiRE可以显式地捕获文档中实体之间的远程依赖关系和输出关系,从而实现更好的交互。我们的主要贡献如下:
- 提出了一种基于逻辑规则学习的关系抽取概率模型。该模型可以显式地捕获实体和输出关系之间的依赖关系,同时获得更好的解释。
- 在EM算法的基础上,提出了一种基于迭代的LogiRE优化方法。
- 实证结果表明,LogiRE在关系性能(~ 1.8 F1分数)和逻辑一致性(超过3.3逻辑分数)方面显著优于几个强基线。
相关工作
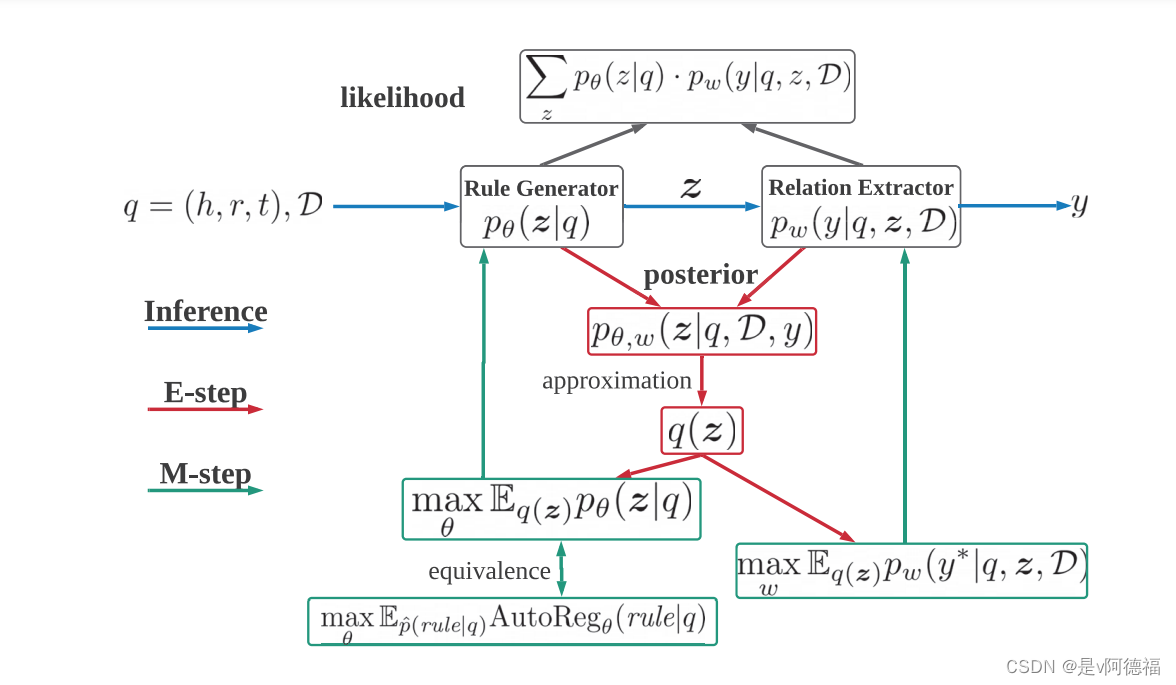
图2:LogiRE的概述。LogiRE由两个模块组成:规则生成器𝑝和关系提取器𝑝𝑤。对于给定的文档D和查询三元组𝑞,我们将所需的逻辑规则视为潜在变量𝒛,旨在识别相应的真值。在推理过程中,我们从规则生成器中抽取潜在规则集的样本,并使用关系提取器对给定规则进行预测。总体目标(最大似然)通过EM算法进行优化。在e步中,我们估计近似后验𝑞(𝒛);在m步中,我们最大化可能性的下界。
对于文档级关系提取,先前捕获远程依赖关系的努力主要集中在两个方向:追求更强的序列表示(Nguyen and Verspoor, 2018;Verga et al., 2018;Zheng等人,2018)或将实体之间交互的先验作为图(Christopoulou等人,2019)。为了获得更强大的表示,他们引入了预训练的语言模型(Wang et al., 2019;Ye et al., 2020),利用注意力进行上下文池化(Zhou et al., 2021),或者将分散的信息按层次进行整合(Tang et al., 2020)。为了模拟实体和关系之间的内在相互作用,他们通过精心设计图来使用隐式推理结构,将提及到实体、同一句子中的提及连接起来(Christopoulou et al., 2019;Sun等人,2019),提到了相同的实体(Wang等人,2020;Zeng et al., 2020)等。Nan et al. (2020);Xu等人(2021)直接将类似的结构依赖关系集成到编码器中的注意机制中。这些方法有助于获得区分各种关系的强大表征,但在隐含推理上缺乏可解释性。另一种可以捕获关系之间依赖关系的方法是全局规范化模型(Andor等人,2016;Sun等人,2018)。在这项工作中,我们关注如何学习和使用逻辑规则来捕获关系之间的长期依赖关系。
另一类相关工作是逻辑推理。许多关于学习或应用逻辑规则进行推理的研究。其中大部分(瞿和唐,2019;Zhang et al., 2020)专注于知
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8629
8629




 到【灌水乐园】发言
到【灌水乐园】发言







