




 本文详细介绍Scrapy爬虫框架的使用方法,包括项目创建、爬虫生成、数据提取与保存,以及日志配置等核心步骤。通过实例演示,帮助读者快速上手Scrapy,掌握高效网页数据抓取技巧。
本文详细介绍Scrapy爬虫框架的使用方法,包括项目创建、爬虫生成、数据提取与保存,以及日志配置等核心步骤。通过实例演示,帮助读者快速上手Scrapy,掌握高效网页数据抓取技巧。
目标
- 掌握如何创建项目
- 掌握如何创建爬虫
- 熟悉创建项目后每个文件的作用
- 掌握pipeline的使用
- 掌握scrapy中logging的使用
1 scrapy项目实现流程
-
创建一个scrapy项目:
scrapy startproject mySpider -
生成一个爬虫:
scrapy genspider itcast "itcast.cn -
提取数据:
完善spider,使用xpath等方法 -
保存数据:
pipeline中保存数据 -
启动项目:
scrapy crawl itcast
2 创建scrapy项目
下面以抓取传智师资库来学习scrapy的入门使用:http://www.itcast.cn/channel/teacher.shtml
命令:scrapy startproject +<项目名字>
示例:scrapy startproject myspider
生成的目录和文件结果如下:

3 创建爬虫
命令:scrapy genspider +<爬虫名字> + <允许爬取的域名>
示例:scrapy genspider itcast itcast.cn
生成的目录和文件结果如下:
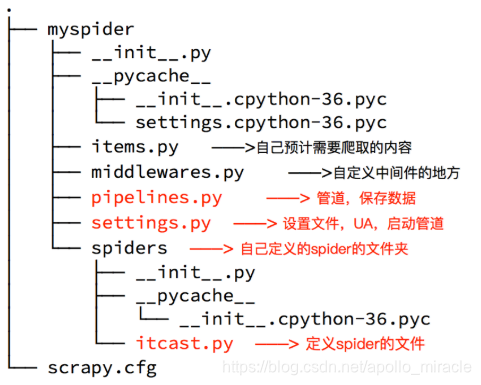
4 完善spider
完善spider即通过方法进行数据的提取等操作

注意:
response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法extract()返回一个包含有字符串的列表extract_first()返回列表中的第一个字符串,列表为空没有返回None- spider中的parse方法必须有
- 需要抓取的url地址必须属于allowed_domains,但是start_urls中的url地址没有这个限制
- 启动爬虫的时候注意启动的位置,是在项目路径下启动
5 数据传递到pipeline

为什么要使用yield?
- 让整个函数变成一个生成器,有什么好处呢?
- 遍历这个函数的返回值的时候,挨个把数据读到内存,不会造成内存的瞬间占用过高
- python3中的range和python2中的xrange同理
注意:
- yield能够传递的对象只能是:
BaseItem,Request,dict,None
6 完善pipeline

完善pipeline代码后,需要在setting中设置重启

pipeline在settings中能够开启多个,为什么需要开启多个?
- 不同的pipeline可以处理不同爬虫的数据
- 不同的pipeline能够进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
pipeline使用注意点
- 使用之前需要在settings中开启
- pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过
- 有多个pipeline的时候,process_item的方法必须
return item,否则后一个pipeline取到的数据为None值 - pipeline中process_item的方法必须有,否则item没有办法接受和处理
- process_item方法接受item和spider,其中spider表示当前传递item过来的spider
7 输出日志LOG的设置
为了让我们自己希望输出到终端的内容能容易看一些,我们可以在setting中设置log级别
在setting中添加一行(全部大写):LOG_LEVEL = "WARNING”
默认终端显示的是debug级别的log信息

















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









