






 本文介绍了一种从LeetCode网站下载教学视频的方法,通过解析m3u8文件获取ts片段,使用Python脚本批量下载并合并ts文件,最终合成完整视频。
本文介绍了一种从LeetCode网站下载教学视频的方法,通过解析m3u8文件获取ts片段,使用Python脚本批量下载并合并ts文件,最终合成完整视频。
有一个朋友,通过一个网站(https://leetcode-cn.com/problems/course-schedule/solution/ke-cheng-biao-by-leetcode-solution/),看到一个视频,感觉不错,就想下载下来,可是下载不了,然后就求助与我,(此处省略一万字废话。。。)下面进入正题。
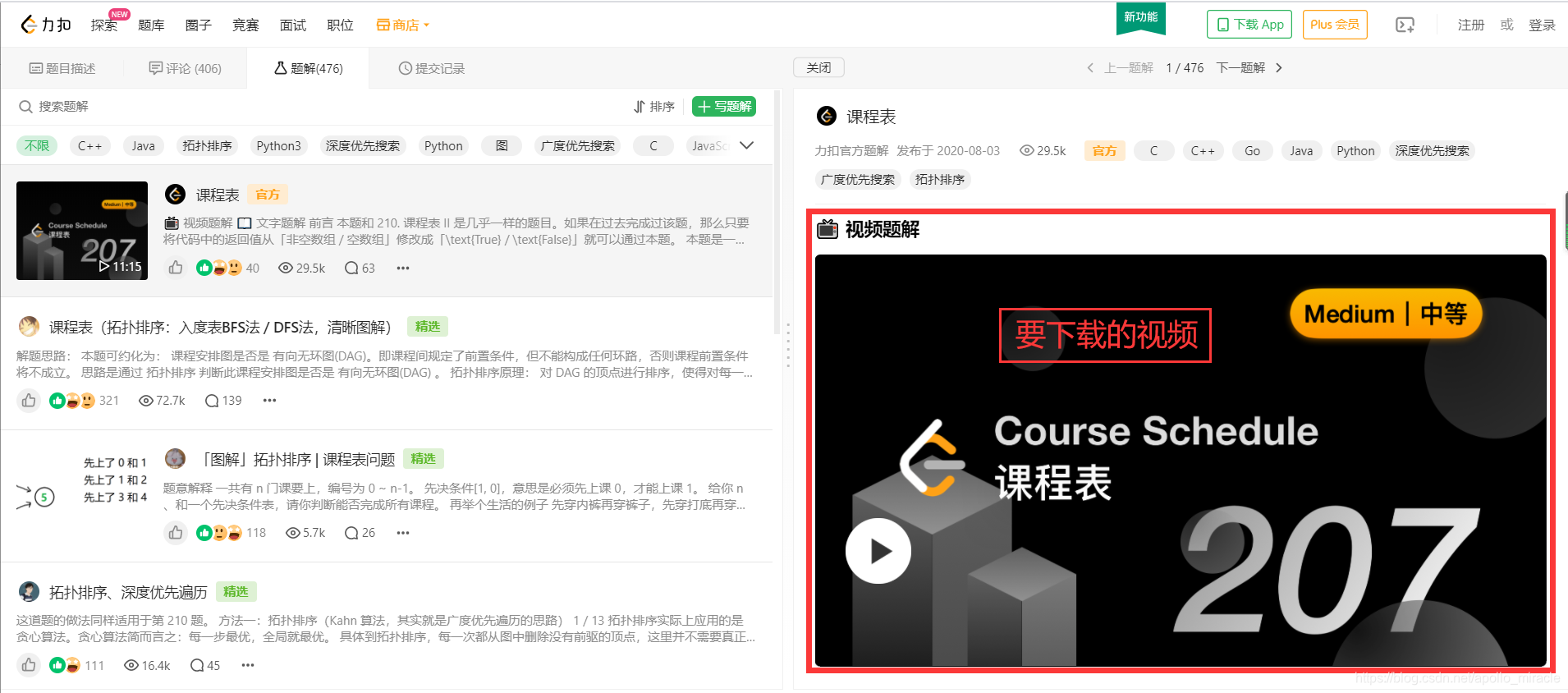
- 网页界面如下图所示,红框中的即为将要下载的视频:
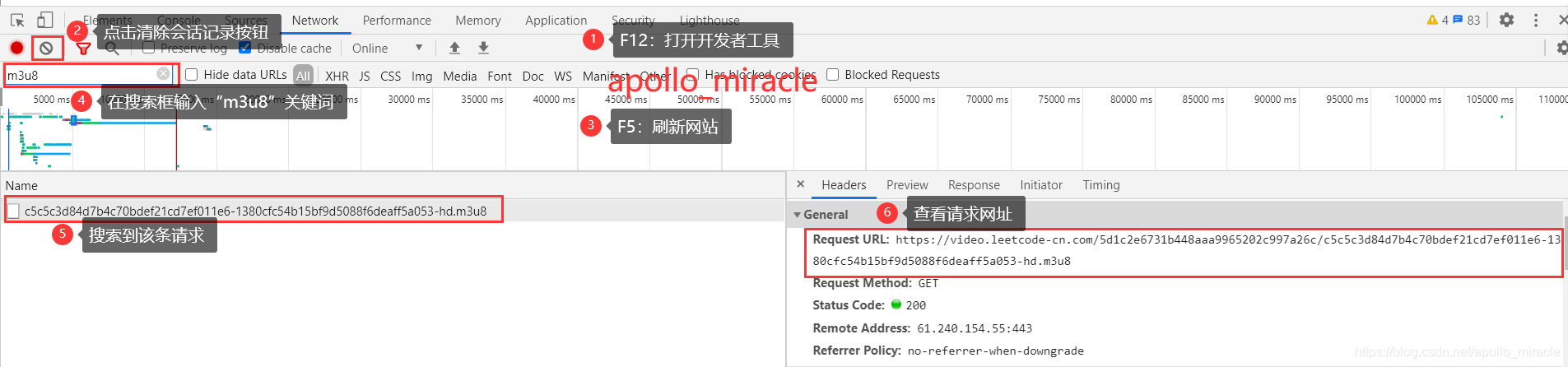
- 按F12,打开开发者工具,清除会话记录,然后刷新网页
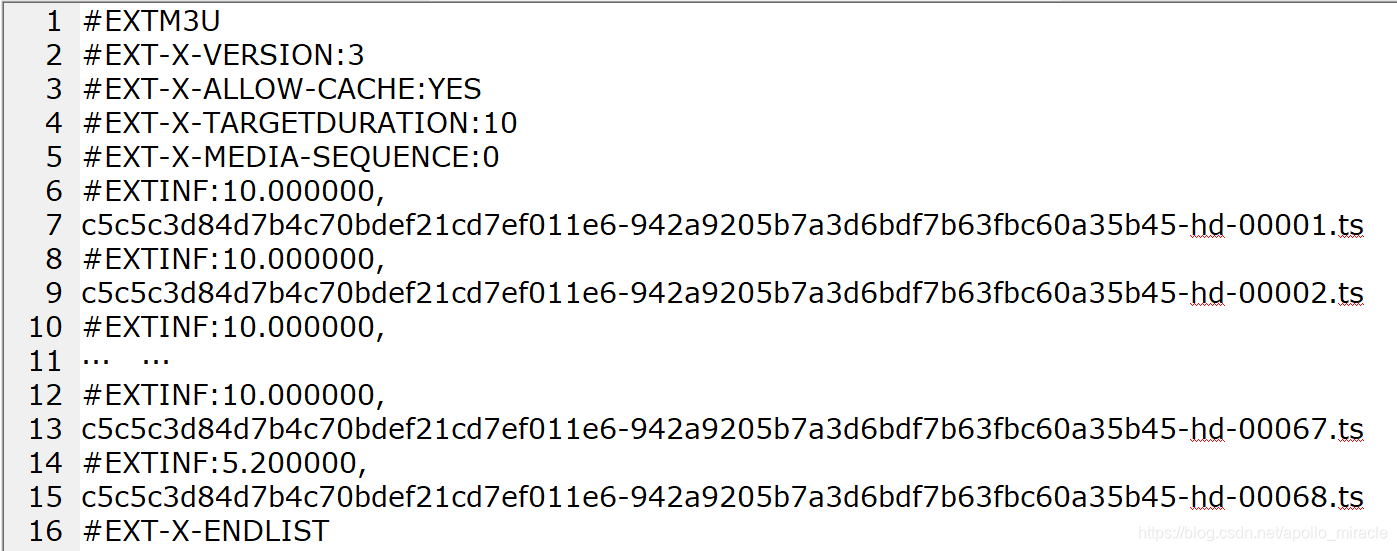
- 下载该文件,文件内容如下:
代码如下:
import os
import requests
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"origin": "https://leetcode-cn.com",
"pragma": "no-cache",
"referer": "https://leetcode-cn.com/problems/course-schedule/solution/ke-cheng-biao-by-leetcode-solution/",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
}
def get_m3u8_file(m3u8_url, file_path):
"""
下载m3u8文件
:param m3u8_url: m3u8文件的URL
:param file_path: 要下载的文件位置
:return:
"""
resp = requests.get(m3u8_url, headers=headers)
if resp.status_code == 200:
content = resp.text
with open(file_path, "w") as f:
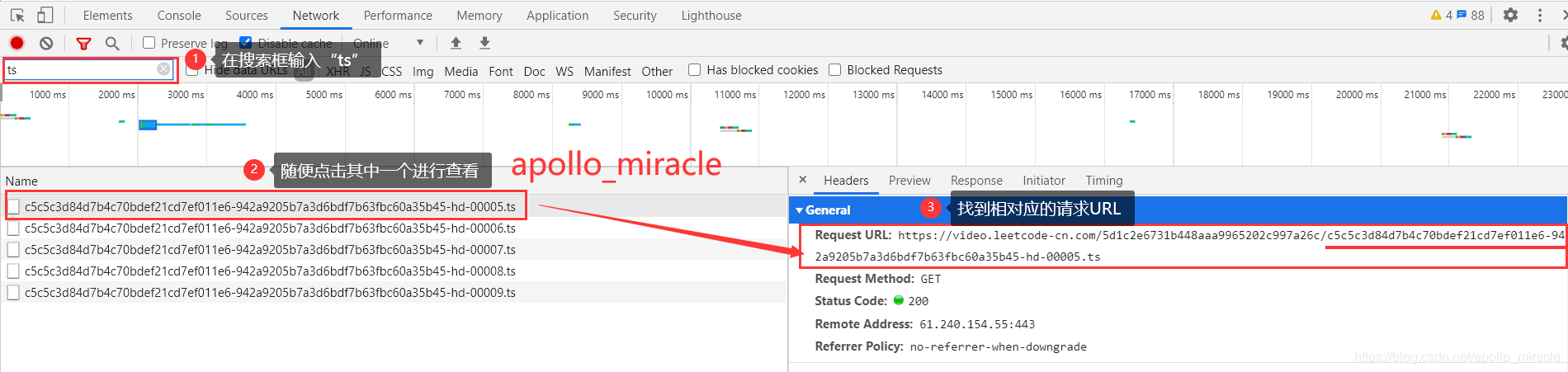
f.write(content)- 然后在输入框搜索“ts”,点击其中一个,发现ts文件请求URL除了最后两位数字不同(依次增加)以外,其他全部一致,而且和m3u8文件中的ts文件名称一致
- 获取ts文件名称(筛选出以“.ts”结尾的行或者筛除以“#”开头的行)
代码如下:
import os
def get_ts_name_list(file_path):
"""
获取ts文件名称列表
:param file_path: m3u8文件路径
:return: ts文件名称列表
"""
ts_name_list = []
with open(file_path, "rb") as f:
cont_list = f.readlines()
for cont in cont_list:
cont = cont.decode().strip()
if cont.endswith(".ts"):
ts_name_list.append(cont.split("/")[-1])
# if not cont.startswith("#"):
# ts_name_list.append(cont.split("/")[-1])
return ts_name_list运行结果:
['c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00001.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00002.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00003.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00004.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00005.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00006.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00007.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00008.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00009.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00010.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00011.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00012.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00013.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00014.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00015.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00016.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00017.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00018.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00019.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00020.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00021.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00022.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00023.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00024.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00025.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00026.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00027.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00028.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00029.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00030.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00031.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00032.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00033.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00034.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00035.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00036.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00037.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00038.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00039.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00040.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00041.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00042.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00043.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00044.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00045.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00046.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00047.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00048.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00049.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00050.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00051.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00052.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00053.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00054.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00055.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00056.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00057.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00058.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00059.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00060.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00061.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00062.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00063.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00064.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00065.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00066.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00067.ts', 'c5c5c3d84d7b4c70bdef21cd7ef011e6-942a9205b7a3d6bdf7b63fbc60a35b45-hd-00068.ts']
- 下载ts文件
代码如下:
def get_ts_files(file_dir, ts_url_template, ts_name_list):
"""
循环下载ts文件
:param file_dir: 文件下载所在文件夹
:param ts_url_template: ts文件请求URL模板
:param ts_name_list: ts文件名称列表
:return:
"""
for ts_name in ts_name_list:
ts_url = ts_url_template + ts_name
resp = requests.get(ts_url, headers=headers)
if resp.status_code == 200:
with open(os.path.join(file_dir, ts_name), "wb") as f:
f.write(resp.content)
print("%s-->下载成功!" % ts_name)
else:
print("%s-->下载失败!" % ts_name)运行结果如下:

- 将所有的ts文件合并成一个整体的ts文件
代码如下:
def merge_ts_files(file_dir, file_name, ts_name_list):
"""
将多个ts文件进行合并
:param file_dir: ts文件所在文件夹
:param file_name: 合并后的文件名称
:param ts_name_list: ts文件名称列表
:return:
"""
file_out = os.path.join(file_dir, file_name)
with open(file_out, 'wb') as f_out:
for ts_name in ts_name_list:
with open(os.path.join(file_dir, ts_name), "rb") as f_in:
f_out.write(f_in.read())
print("合并ts文件成功!")- 大功告成,看效果

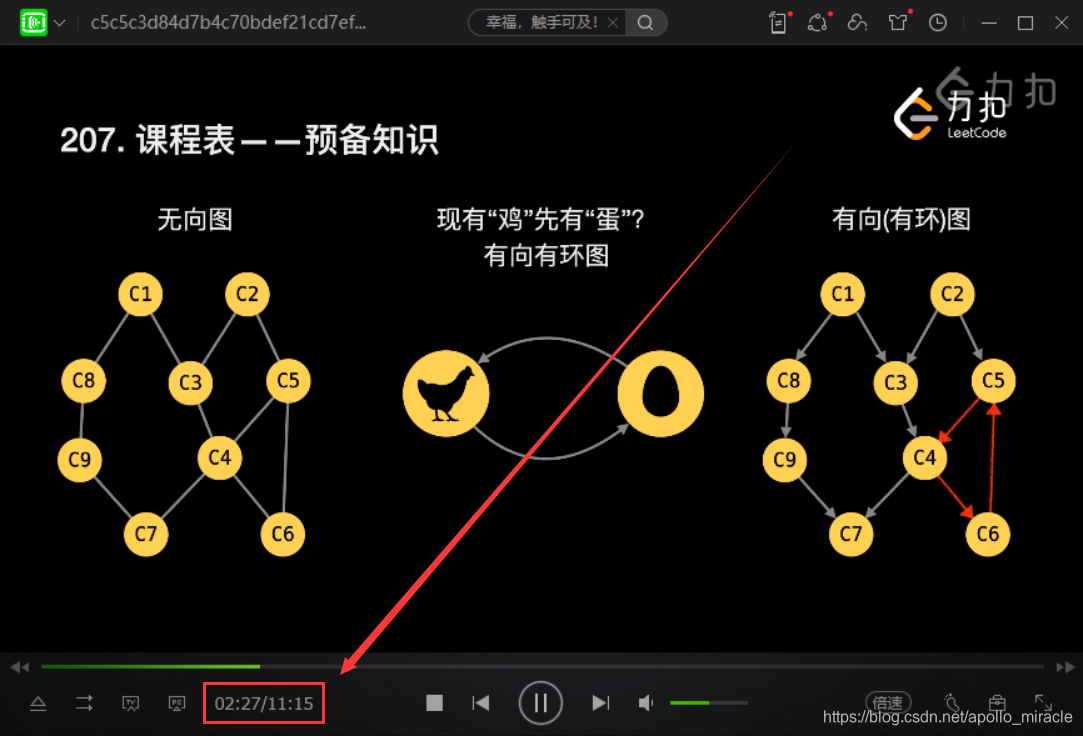
最后附上全部代码(可直接运行):
import os
import requests
headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"origin": "https://leetcode-cn.com",
"pragma": "no-cache",
"referer": "https://leetcode-cn.com/problems/course-schedule/solution/ke-cheng-biao-by-leetcode-solution/",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
}
def get_m3u8_file(m3u8_url, file_path):
"""
下载m3u8文件
:param m3u8_url: m3u8文件的URL
:param file_path: 要下载的文件路径
:return:
"""
resp = requests.get(m3u8_url, headers=headers)
if resp.status_code == 200:
content = resp.text
with open(file_path, "w") as f:
f.write(content)
def get_ts_name_list(file_path):
"""
获取ts文件名称列表
:param file_path: m3u8文件路径
:return: ts文件名称列表
"""
ts_name_list = []
with open(file_path, "rb") as f:
cont_list = f.readlines()
for cont in cont_list:
cont = cont.decode().strip()
if cont.endswith(".ts"):
ts_name_list.append(cont.split("/")[-1])
# if not cont.startswith("#"):
# ts_name_list.append(cont.split("/")[-1])
return ts_name_list
def get_ts_files(file_dir, ts_url_template, ts_name_list):
"""
循环下载ts文件
:param file_dir: 文件下载所在文件夹
:param ts_url_template: ts文件请求URL模板
:param ts_name_list: ts文件名称列表
:return:
"""
for ts_name in ts_name_list:
ts_url = ts_url_template + ts_name
resp = requests.get(ts_url, headers=headers)
if resp.status_code == 200:
with open(os.path.join(file_dir, ts_name), "wb") as f:
f.write(resp.content)
print("%s-->下载成功!" % ts_name)
else:
print("%s-->下载失败!" % ts_name)
def merge_ts_files(file_dir, file_name, ts_name_list):
"""
将多个ts文件进行合并
:param file_dir: ts文件所在文件夹
:param file_name: 合并后的文件名称
:param ts_name_list: ts文件名称列表
:return:
"""
file_out = os.path.join(file_dir, file_name)
with open(file_out, 'wb') as f_out:
for ts_name in ts_name_list:
with open(os.path.join(file_dir, ts_name), "rb") as f_in:
f_out.write(f_in.read())
print("合并ts文件成功!")
if __name__ == '__main__':
# 用来保存ts文件
file_dir = './ts_file'
if not os.path.exists(file_dir):
os.mkdir(file_dir)
# m3u8文件URL
m3u8_url = "https://video.leetcode-cn.com/5d1c2e6731b448aaa9965202c997a26c/c5c5c3d84d7b4c70bdef21cd7ef011e6-1380cfc54b15bf9d5088f6deaff5a053-hd.m3u8"
# 提取文件名
file_name = m3u8_url.split('/')[-1]
file_path = os.path.join(file_dir, file_name)
# 下载m3u8文件
get_m3u8_file(m3u8_url, file_path)
# 获取文件中ts文件名称列表
ts_name_list = get_ts_name_list(file_path)
# ts文件URL模板
ts_url_template = "https://video.leetcode-cn.com/5d1c2e6731b448aaa9965202c997a26c/"
# 下载ts文件
get_ts_files(file_dir, ts_url_template, ts_name_list)
# 合并ts文件
ts_file_name = file_name.split(".")[0] + ".ts"
merge_ts_files(file_dir, ts_file_name, ts_name_list)


















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









