






 ClouderaFastForward的两位研究工程师将用两个月时间构建一个信息检索(IR)为基础的问答(QA)系统。系统包含两部分:文档检索器和文档阅读器。检索器作为搜索引擎,排名并返回相关文档;阅读器运用NLP技术,从候选文档中提取最符合问题的答案。他们计划实验多种Transformer架构(如BERT)来改进文档阅读器,并使用现成的搜索算法优化检索器。
ClouderaFastForward的两位研究工程师将用两个月时间构建一个信息检索(IR)为基础的问答(QA)系统。系统包含两部分:文档检索器和文档阅读器。检索器作为搜索引擎,排名并返回相关文档;阅读器运用NLP技术,从候选文档中提取最符合问题的答案。他们计划实验多种Transformer架构(如BERT)来改进文档阅读器,并使用现成的搜索算法优化检索器。
【转】NLP for Question Answering: IR-QA
Over the course of the next two months, two of Cloudera Fast Forward’s Research Engineers,
Melanie Beck and Ryan Micallef, will build a QA system following the information retrieval-based
method, by creating a document retriever and document reader.
We’ll focus our efforts on exploring and experimenting with various Transformer architectures
(like BERT) for the document reader, as well as off-the-shelf search engine algorithms for the retriever.
IR-QA
-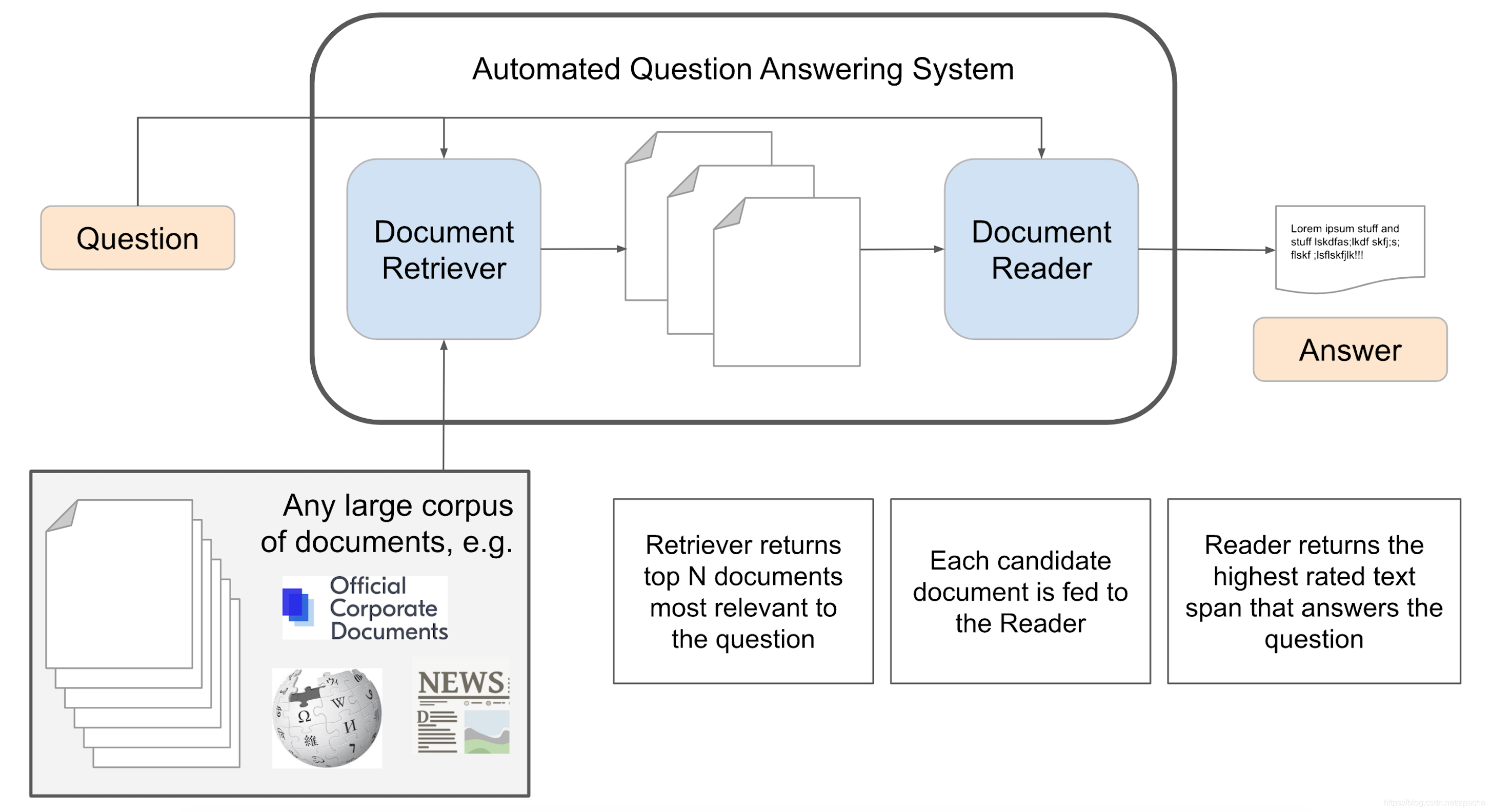
-Below we illustrate the workflow of a generic IR-based QA system. These systems generally
have two main components: the document retriever and the document reader.
The document retriever functions as the search engine, ranking and retrieving relevant
documents to which it has access. It supplies a set of candidate documents that could
answer the question (often with mixed results, per the Google search shown above).
The document reader consists of reading comprehension algorithms built with core
NLP techniques. This component processes the candidate documents and extracts
from one of them an explicit span of text that best satisfies the query. Let’s dive
deeper into each of these components.
======================
Ref:
https://experiments.fastforwardlabs.com/
https://qa.fastforwardlabs.com/
Building a QA System with BERT on Wikipedia
https://qa.fastforwardlabs.com/pytorch/hugging%20face/wikipedia/bert/transformers/2020/05/19/Getting_Started_with_QA.html

















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









