



一、什么是 llms.txt?
llms.txt 是由 Jeremy Howard 于 2024 年 9 月 3 日提出的一项开放性提案,旨在为网站提供一个标准的、机器可读的入口,专门用于帮助大语言模型在推理(inference)阶段更有效地理解网站内容。
简要介绍一下Jeremy Howard,他目前是answer.ai的创始首席执行官,早年间曾参与Perl语言的开发,后来担任Kaggle 的总裁兼首席科学家,同时也是fast.ai的联合创始人,有意思的是,他还运用间隔重复学习法,仅用一年时间就掌握了实用的中文技能。可以看到他是个技术大牛,同是也是一个非常重视理论和实践相结合的人。这是他的Github主页:https://github.com/jph00
llms.txt的核心理念
- 和robots.txt不同:
robots.txt文件是告诉搜索引擎爬虫“哪些页面可以抓取,哪些页面不能爬取”,llms.txt文件则是告诉 LLM “哪些信息对理解这个网站最有价值”。 - 类比sitemap.xml:类似于
sitemap.xml,llms.txt提供的是网站内容和链接的索引,但和sitemap.xml不同的是,它不试图提供整个网站的内容,而是提供一个精心策划的、结构化的信息摘要和关键链接列表,帮助 LLM 快速构建对网站的理解。
注意事项:llms.txt的作用到底是什么?
如果你询问一些大模型llms.txt的作用是什么,它很可能告诉你这是用来告诉大模型是否允许抓取网站数据用于训练的文件,类似于robots.txt控制爬虫权限,甚至在搜索引擎中搜索这方面的内容时,一些博客文章也会这么说。我原本以为存在两个相互不兼容版本的llms.txt,一个版本是用于帮助大模型在推理阶段理解网站内容,一个版本是用于控制大模型抓取训练数据的权限。
经过我进一步的深入搜索,这个第一个版本,即用于帮助大模型在推理过程中理解网站内容,来源是非常清晰的,有对应的官方网站和对应的Python工具包,规范的起草人也很明确是Jeremy Howard。
但是第二个版本,完全找不到其定义的来源,只有零星的一些个人博客文章在介绍,而且我特意搜索了一下如何控制AI抓取网站内容的权限,大量的文章都说直接在robots.txt中添加限制Agent就行,既然robots.txt就可以限制,那llms.txt再限制不就是纯属多此一举?因此我合理怀疑这是大模型幻觉生成的内容,并且被一些人以讹传讹写成了技术博客在互联网上传播,甚至污染了更多的大模型。
这件事也让我更加警醒,对于大模型生成的内容,需要非常谨慎地进行鉴别,尤其是技术性的内容,一旦错误的信息开始传播,很可能导致病毒性的蔓延乃至污染了整个互联网。
二、为什么需要 llms.txt?
1. 现有方案的局限性
站点地图(Sitemap.xml)
站点地图是用于搜索引擎优化(SEO)的技术手段,其列出了网站的所有页面,但它并不适合大模型读取,因为它:
- 通常不包含适合 LLM 阅读的纯文本版本。
- 不包含对理解网站有帮助的外部资源链接。
- 内容总量往往远超 LLM 的上下文窗口限制。
直接抓取 HTML
现代网页的 HTML 结构复杂,包含大量非核心内容,提取有效信息困难且不准确。
2. llms.txt 的优势
- 上下文优化:通过提供精炼的摘要和精选链接,显著减少 LLM 需要处理的无效信息。
- 结构化导航:明确的章节划分(如“文档”、“示例”、“可选”)帮助 LLM 快速定位所需信息。
- 支持动态扩展:
llms.txt本身只是一个“目录”,它可以指向其他.md文件,这些文件是原始网页的 Markdown 版本,内容更纯净、更适合 LLM 解析。
三、llms.txt 文件格式详解
一个符合规范的 llms.txt 文件位于网站的根路径或其他可选的子路径下,例如 https://vuejs.org/llms.txt,https://fastht.ml/docs/llms.txt(这两个链接都可以真实访问),其结构遵循严格的 Markdown 格式:
1. 必需部分
- H1 标题:以
#开头,表示项目或网站的名称。这是唯一必需的字段。# FastHTML - 引用摘要:以
>开头的引用块,提供对项目/网站的简短描述,包含理解后续内容所需的关键信息。> FastHTML is a python library which brings together Starlette, Uvicorn, HTMX, and fastcore's `FT` "FastTags" into a library for creating server-rendered hypermedia applications.
2. 可选但推荐的部分
-
详细信息段落:在 H1 和第一个 H2 之间,可以包含任意数量的普通段落、列表等,用于补充说明。
Important notes: - Although parts of its API are inspired by FastAPI, it is *not* compatible with FastAPI syntax... - FastHTML is compatible with JS-native web components and any vanilla JS library... -
H2 分节列表:以
##开头的二级标题,每个标题代表一个信息类别(如“Docs”、“Examples”)。其后是一个 Markdown 列表,每项包含一个链接和可选的描述。## Docs - [FastHTML quick start](https://fastht.ml/docs/tutorials/quickstart_for_web_devs.html.md): A brief overview of many FastHTML features - [HTMX reference](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Brief description of all HTMX attributes...
3. 特殊的 “Optional” 节
- 如果存在名为
## Optional的章节,其中列出的链接被认为是非核心信息。 - 当 LLM 的上下文窗口紧张时,可以优先跳过这些内容,以保证核心信息的完整加载。
下图是fastHTML项目的llms.txt文件,其遵循了标准的格式规范:

四、技术实现与工具链
llms.txt 不仅仅是一个静态文件,它背后有一整套工具链来支持其落地。
1. Markdown 版本的网页
提案建议,网站上所有对 LLM 有价值的页面,都应提供一个纯净的 Markdown 版本。规则如下:
- 原始 URL 为
https://example.com/docs/tutorial.html,则其 Markdown 版本应为https://example.com/docs/tutorial.html.md。 - 对于没有文件名的 URL(如
https://example.com/docs/),Markdown 版本为https://example.com/docs/index.html.md。
这确保了 LLM 获取的是最干净、最结构化的文本内容。
2. Python 工具:llms-txt 模块
官方提供了 llms-txt Python 包,用于解析 llms.txt 文件并生成适合 LLM 的上下文。
安装
pip install llms-txt
CLI 使用
# 将 llms.txt 转换为 XML 格式的上下文,并输出到标准输出
llms_txt2ctx llms.txt > llms.md
# 包含 "Optional" 部分
llms_txt2ctx llms.txt --optional True > llms-full.md
Python API 示例
from llms_txt import parse_llms_file, create_ctx
from pathlib import Path
# 读取文件
samp = Path('llms.txt').read_text()
# 解析文件,得到结构化数据
parsed = parse_llms_file(samp)
print(parsed.title) # 输出: FastHTML
print(list(parsed.sections)) # 输出: ['Docs', 'Examples', 'Optional']
# 生成 LLM 可用的 XML 上下文
ctx = create_ctx(samp)
print(ctx[:300]) # 查看生成的上下文前300字符
五、在实际项目中的实践
llms.txt已经在一些实际网站项目中得到了应用,此处列举出一些知名网站中的应用。
FastHTML
FastHTML是一个旨在用Python语言开发完整的HTML应用的产品,也正是llms.txt规范的起草人Jeremy Howard创办的answer.ai旗下的产品,因此其很早就采用了 llms.txt。该项目的文档网站不仅提供了 llms.txt 文件,还为每个页面生成了Markdown版本。下图即展示了其文档网站的主页对应的Markdown版本:

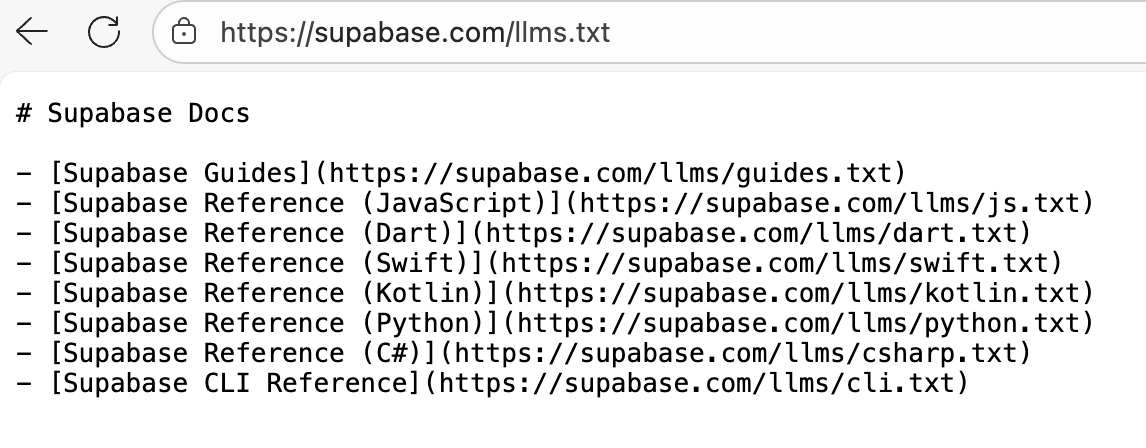
Supabase
Supabase 基于PostgreSQL提供了在线数据库服务,同时也是一个全功能的后端服务平台。通过 Supabase,开发人员不再受限于传统的前后端分离模式,无需编写复杂的后端逻辑,可以直接在前端代码中进行数据库操作。
Vue.js 生态系统
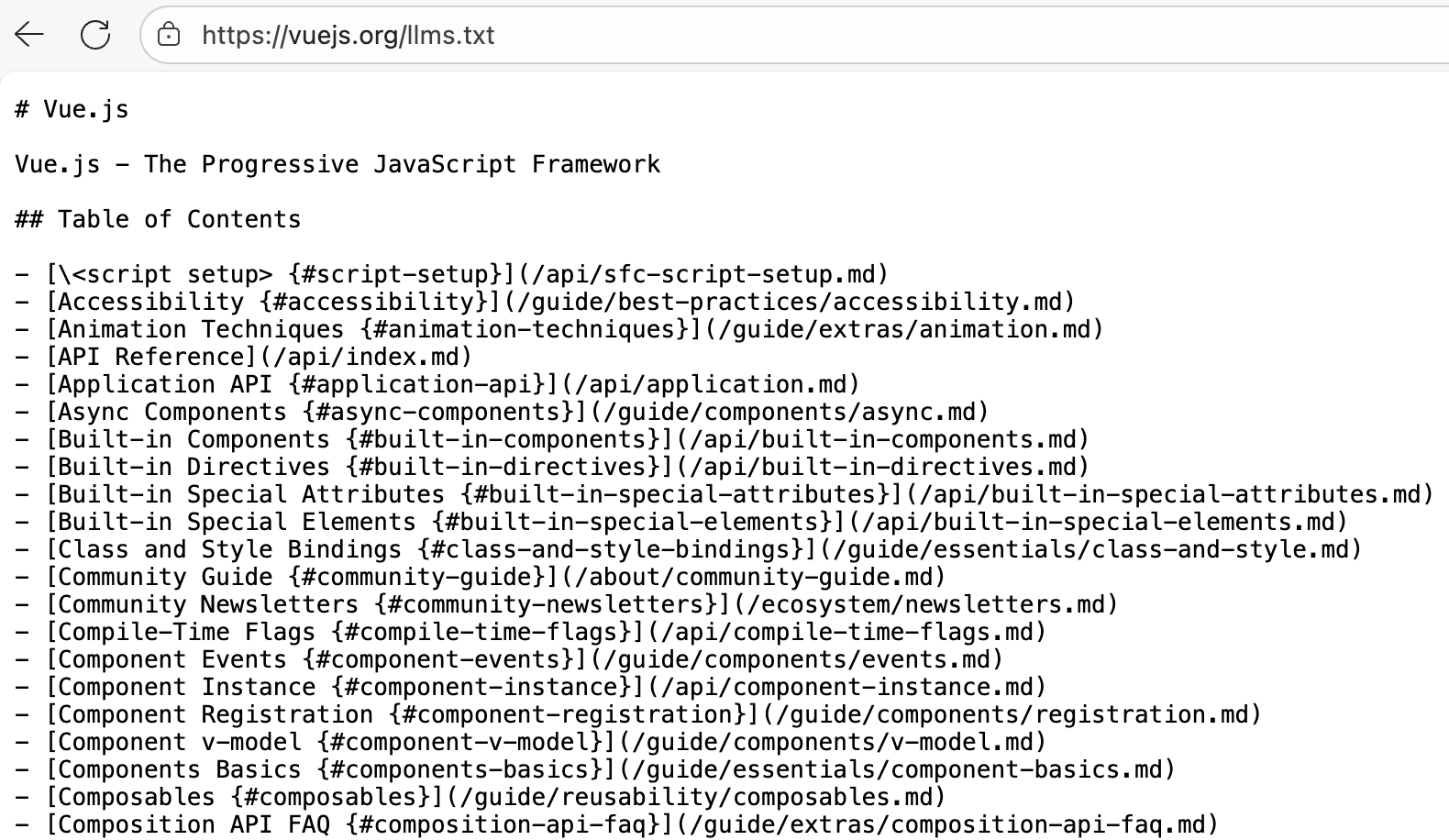
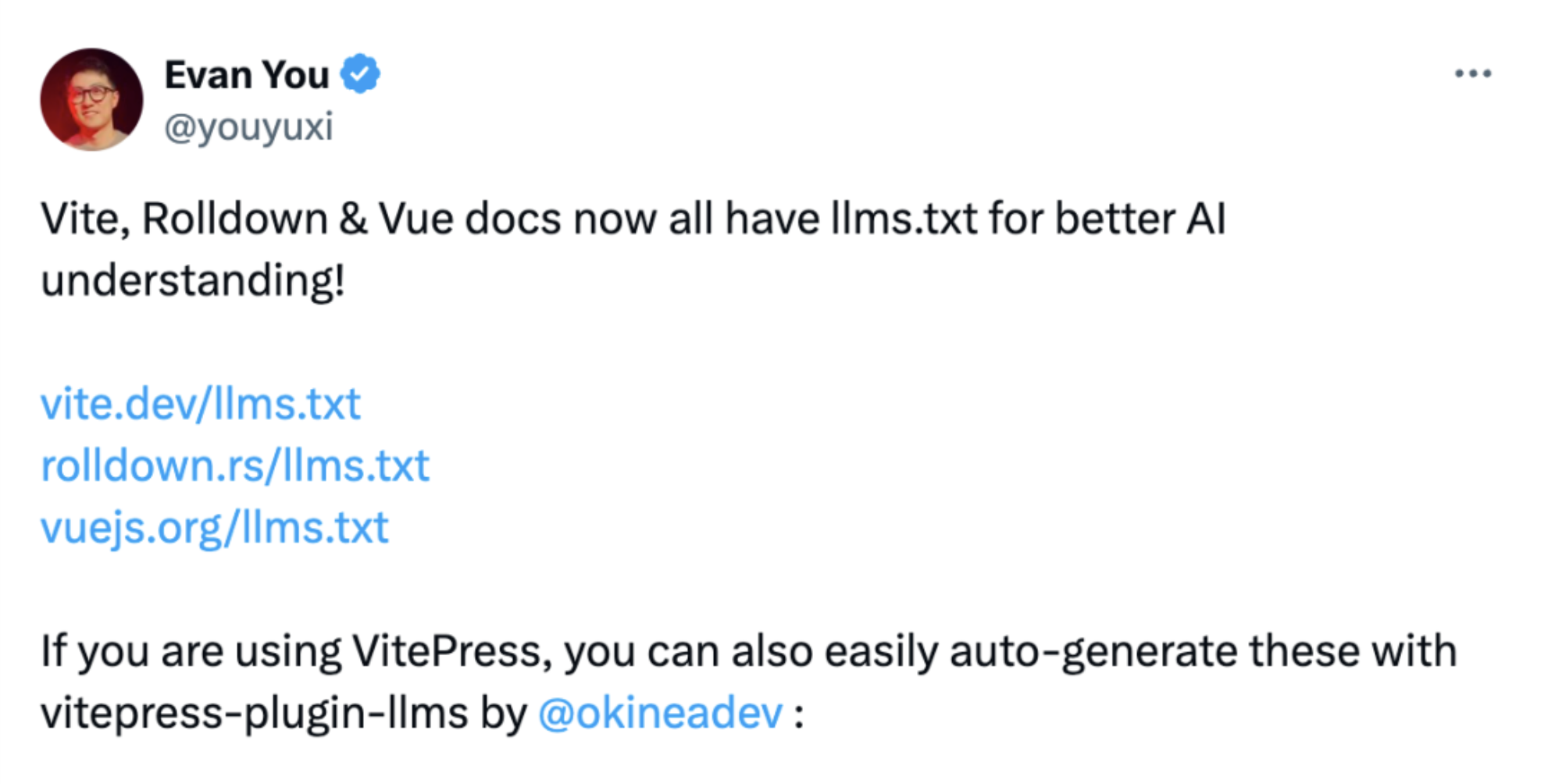
2025年5月,前端框架领域的领军人物尤雨溪(Evan You)宣布,Vue.js、Vite 和 Rolldown 等核心项目均已添加 llms.txt 文件,这对于llms.txt的推广注入了一剂强心针。
六、如何为自己的网站自动生成llm.txt文件?
vitepress-plugin-llms
vitepress-plugin-llms 是一个专为 VitePress 文档网站设计的插件,它可以自动生成 llms.txt 和 llms-full.txt 文件,让你的 VitePress 文档更好地被 AI 工具理解和索引。该插件也被尤雨溪推荐过:
项目地址如下:https://github.com/okineadev/vitepress-plugin-llms
llms-txt.io
https://llms-txt.io/ 这个项目可以帮助你生成自己的网站对应的llms.txt文件,只要输入网址即可自动生成。
七、如何查找更多采用 llms.txt 的网站?
随着 llms.txt 的普及,社区正在建立专门的目录来追踪和展示采用该标准的网站,一些我搜集到的网站如下:
llmstxthub.com:一个综合性的中心,提供指南、工具和网站目录。
directory.llmstxt.cloud:一个实时更新的数据库,收录了全球范围内已知的 llms.txt 实例。
llmstxt.site:另一个社区驱动的目录。

















 1639
1639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









