






 Apache Flink是一个用于流式和批量数据处理的分布式平台,提供多种API如DataStream、DataSet及TableAPI,支持复杂事件处理、机器学习和图计算等功能。与Spark、Storm等大数据处理引擎相比,Flink旨在统一不同数据源的处理流程。
Apache Flink是一个用于流式和批量数据处理的分布式平台,提供多种API如DataStream、DataSet及TableAPI,支持复杂事件处理、机器学习和图计算等功能。与Spark、Storm等大数据处理引擎相比,Flink旨在统一不同数据源的处理流程。
Apache Flink是一个分布式流式和批量数据处理的开源平台。
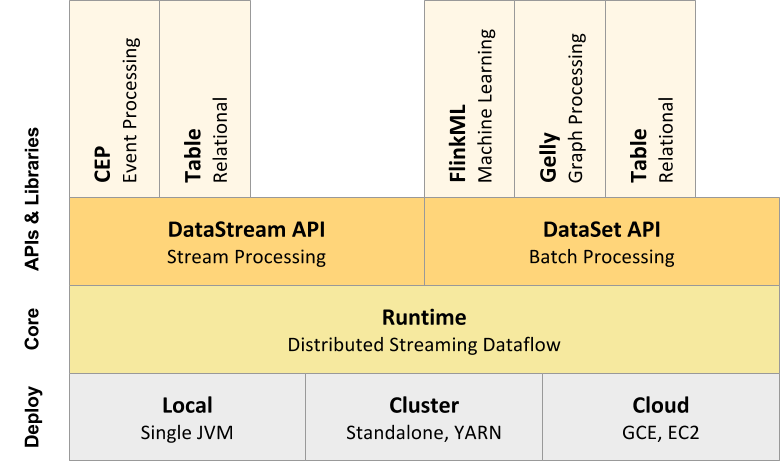
Flink的核心是一个流式数据流动引擎,它为数据流上面的分布式计算提供数据分发、通讯、容错。Flink包括几个使用 Flink引擎创建应用程序的编程接口:
1. DataStream API 集成在Java和Scala中中的流数据格式;
2.DataSet API 集成在JAVA、Scala、Python中的静态数据;
3. Table API 在JAVA、Scala中使用的类SQL的表达式;
Flink 也包含为特定用户场景准备的库函数:
- CEP, 一个复杂的事件处理函数库;
- Machine Learning library
- Gelly, 图计算处理函数库;
flink是一款新的大数据处理引擎,目标是统一不同来源的数据处理。flink从各个方面看想做的事情都和spark很类似,这两套系统都在尝试建立一个统一的平台可以运行批量,流式,交互式,图处理,机器学习等应用。所以,flink和spark的目标差别并不大,他们最主要的区别在于实现的细节。
虽然MR计算模型在批处理领域占据统治地位,然而其对内存使用的粗犷为各种各样的更快速的大数据分析平台留下了发挥空间。除了Flink、storm、spark外,还包括Apache推出Google Dremel的开源版本
Apache Drill(2014年12月份升级成为Apache基金会的顶级项目)、来自NSA(美国国家安全局)
Apache Nifi(2014年12月份贡献给Apache基金会)、来自
Cloudera公司开发的实时分析系统
Impala(受Google Dremel启发)、加州伯克利大学AMPLab开发的大数据分析系统
Shark 、Facebook开源的分布式SQL查询引擎
Presto、
Hortonworks开源的实时且类SQL的即时查询系统
Stinger等等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









