



 本文深入探讨了Java中Lambda表达式与匿名内部类的底层实现原理,揭示了两者在编译后的不同表现形式。通过对编译后的class文件进行反编译,对比了匿名内部类和Lambda表达式的实现方式,解释了Lambda表达式如何通过动态生成类来提高代码简洁性和性能。
本文深入探讨了Java中Lambda表达式与匿名内部类的底层实现原理,揭示了两者在编译后的不同表现形式。通过对编译后的class文件进行反编译,对比了匿名内部类和Lambda表达式的实现方式,解释了Lambda表达式如何通过动态生成类来提高代码简洁性和性能。
先看一下匿名内部类长什么样子:
1 package com.jvm.demo.test2; 2 3 public class InnerClassTest { 4 5 public static void main(String[] args) { 6 new Thread(new Runnable() { 7 @Override 8 public void run() { 9 System.out.print("hello world!"); 10 } 11 }).start(); 12 } 13 14 }
再看一下lambda表达式长什么样子
1 package com.jvm.demo.test2; 2 3 public class LambdaTest { 4 5 public static void main(String[] args) { 6 new Thread(() -> System.out.print("hello world!")).start(); 7 } 8 9 }
是不是长的很像,一眼能看出区别就在于参数的传递上,匿名内部类是传递的对象,而lambda表达式是传递的函数,那么我们是不是可以认为
lambda实际上就是一个语法糖,简化了部分代码?这就需要我们去看一下底层实现了。
先把两个类都编译一遍,然后javap反编译查看class码,先来看看匿名内部类的实现:
javap -v -p -l -s -c InnerClassTest

0-11行,可以看到是分别创建了一个Thread对象和一个InnerClassTest$1对象,InnerClassTest$1对象是什么呢?可以看下面

这下就忽然开朗了,InnerClassTest$1是一个单独的类文件,我们在目录下面也是可以看到的:

由此我们可以得出结论:匿名内部类的实现是通过创建一个类文件来实现的,那么LambdaTest又是如何实现的呢?
javap -v -p -l -s -c LambdaTest.class
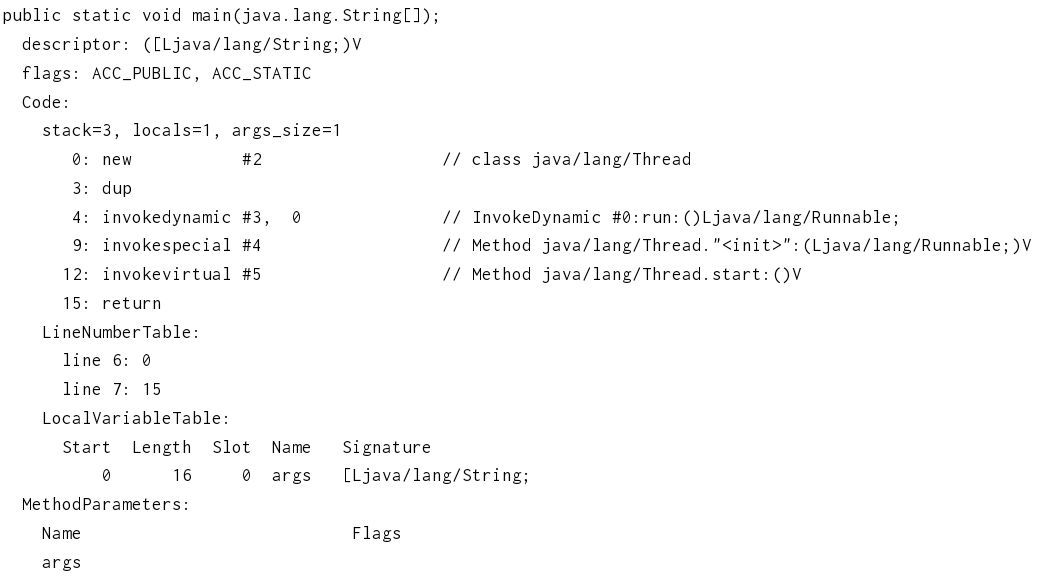
0-4行,调用了invokedynamic指令,invokedynamic指令是一个动态调用指令,该指令调用的代码在编译阶段不确定,在第一次运行的时候才会确定。
4: invokedynamic #3, 0 其中的#3指向常量池中的#3:
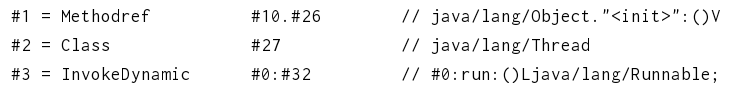
#0指向引导方法的0行:

引导方法是invokedynamic都会调用的一个方法,从上面可以看出引导方法里面会调用类metafactory里面的方法,我们先去看下metafactory这个类,
这个类是一个内部类,在LambdaMetafactory里面:
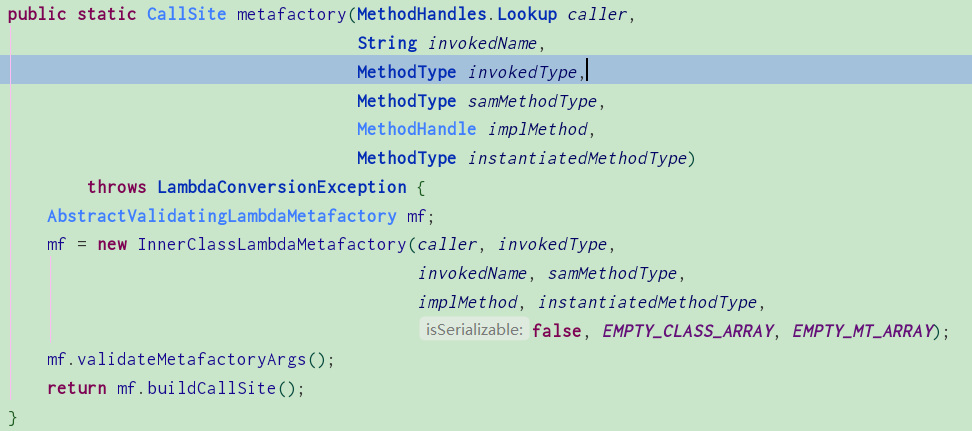
这里主要是调用了InnerClassLambdaMetafactory方法,进去看看:
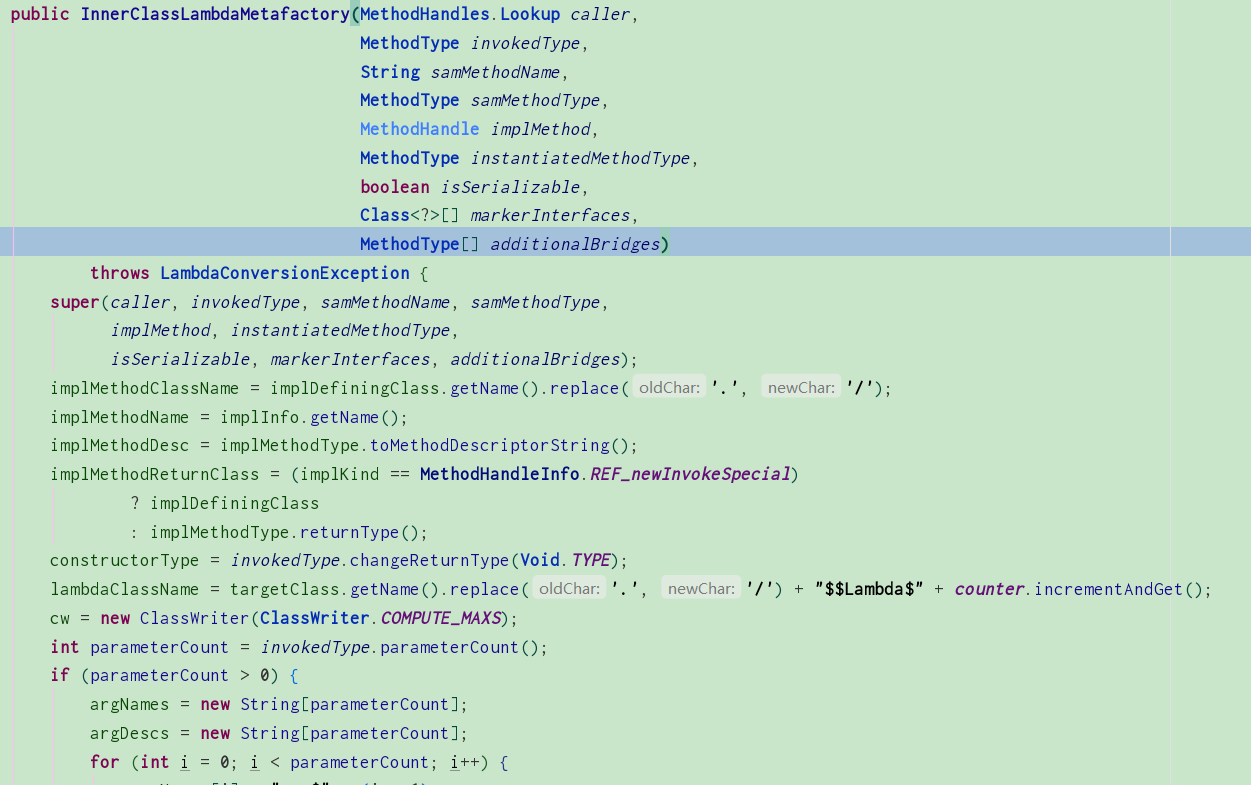
可以看出这里是根据传入的方法特征(返回值和参数)来动态构造一个类,该类的命名规则是
targetClass.getName().replace('.', '/') + "$$Lambda$" + counter.incrementAndGet();
最终这个类会被返回出去:
然后返回CallSite调用点,以便多次调用。
之前就有人说过Lambda表达式过多影响程序性能,但是现在看来不是这样的,Lambda实际只会在第一次调用的时候动态生成类,之后调用就不会重新生成了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









