




1.redis应用场景是什么?
2.Redis除了缓存,还有哪些应用?
3.Redis支持并发操作吗?
4.Redis分布式锁的实现原理?什么场景下用到分布式锁?
5.Redis的大Key问题是什么?
6.大Key问题的缺点?
7.Redis大key如何解决?
8.什么是热key?
9.如何解决热key问题?
10.如何保证 redis 和 mysql 数据缓存一致性问题?
1.redis应用场景是什么?
redis基于内存,读写特别快。
- 缓存:首先就可以作为热点数据的缓存,减轻数据库的压力。
- 实时排行榜:然后读写快+Zset(有序集合),适配实时排行榜的需求。
- 再然后一些后续提出的数据结构,bitmap可以做签到记录。HyperLogLog根据海量数据做基数统计,流量分析。
- 分布式锁:String的SETNX+EXPIRE redis多种分布式锁的实现
- 消息队列:Redis的发布订阅功能做一个轻量级的消息队列。
2.Redis除了缓存,还有哪些应用?
消息队列,分布式锁。
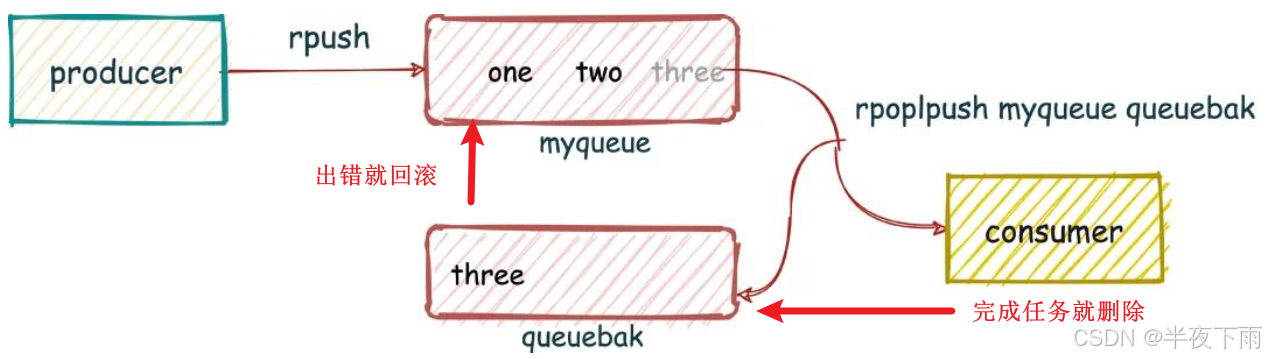
消息队列:常见的实现方案有List(lpush, rpop(要求代码while(true)), 或者blpush这样阻塞式的,或者多个List实现消息可靠,也就是确保消费者正确消费完),Pub/Sub发布订阅功能(任何客户端(Redis实例)都可以订阅一个或多个频道,发布者可以向特定频道发送消息)。但是相比于成熟的消息队列框架,RabbitMQ,kafaka,还是需要花心思处理消息持久化,可靠性,顺序等,有一些不方便。
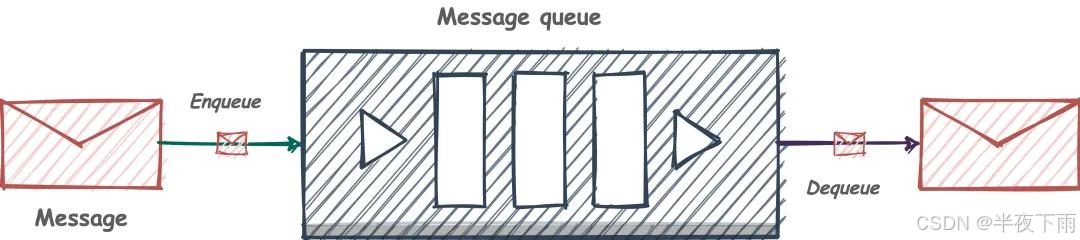
分布式锁
set nx方式:Redis提供了几种方式来实现分布式锁,最常用的是基于SET命令的争抢锁机制。客户端可以使用SET resource_name lock_value NX PX milliseconds命令设置锁,其中NX表示只有当键不存在时才设置,PX指定锁的有效时间(毫秒)。(注意要使用lua脚本保证原子性)
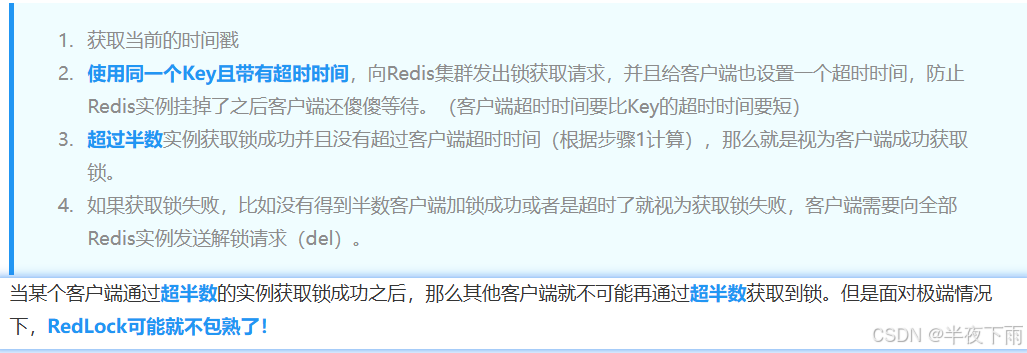
RedLock和redisson:单机锁+分布式锁
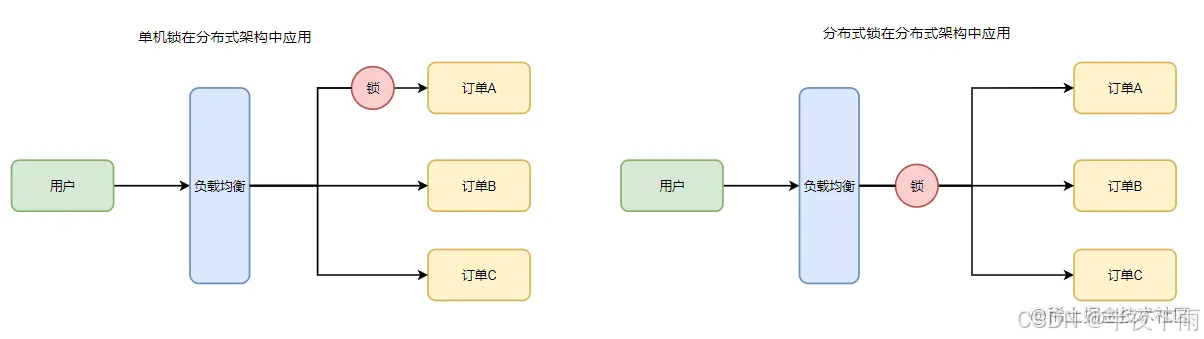
分析问题:之所以简单的设置Key不能满足于Redis集群应用,主要的原因在于锁仅存在于单个实例中。
3.Redis支持并发操作吗?
支持。

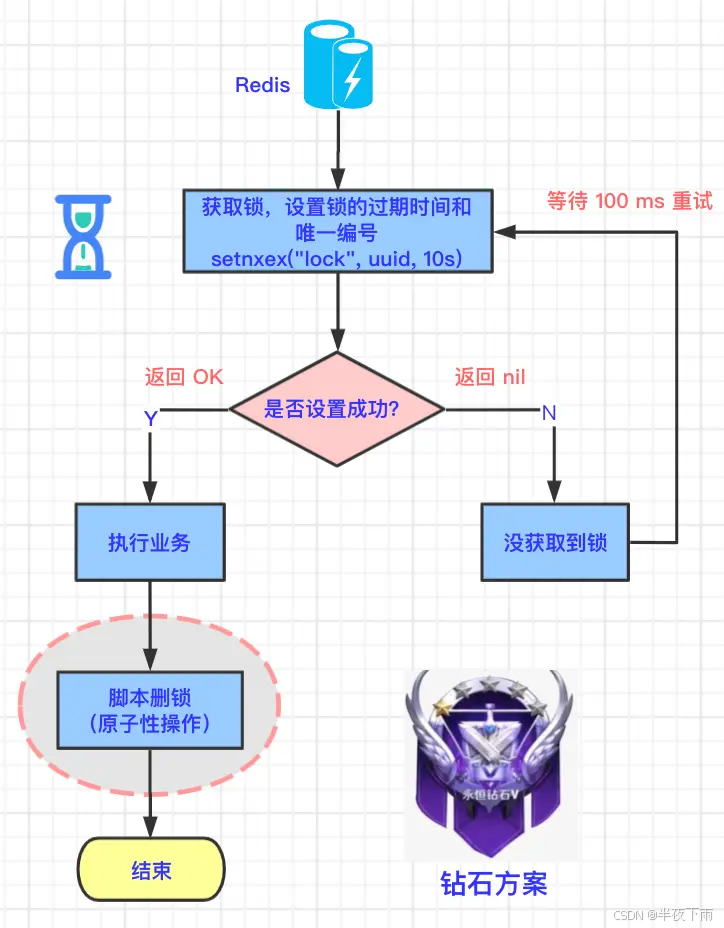
4.Redis分布式锁的实现原理?什么场景下用到分布式锁?
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。
分布式锁的五种进阶方案
按照资源的单机或多机,单机一般就是setnx+过期时间,分布就是redlock。
setnx,要注意的是设置value有请求特有编号,然后解锁的时候检查是否是自己的锁,要用lua脚本。
5.Redis的大Key问题是什么?

6.大Key问题的缺点?
内存占用过高,读写性能下降,从而导致其他操作被阻塞,网络IO拥塞,主从同步延迟。
要解释的:
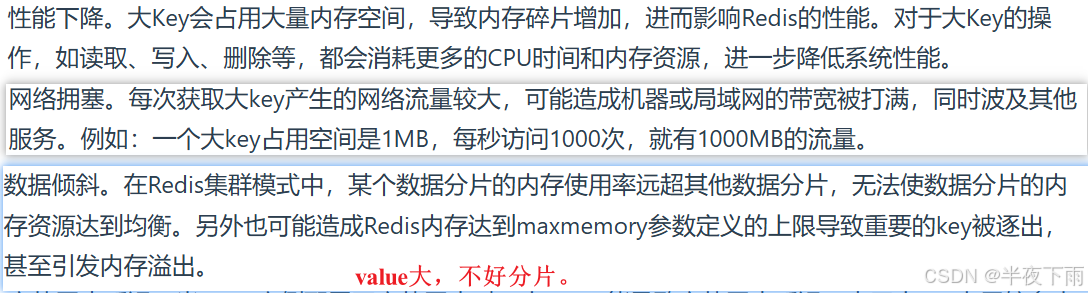
数据倾斜:
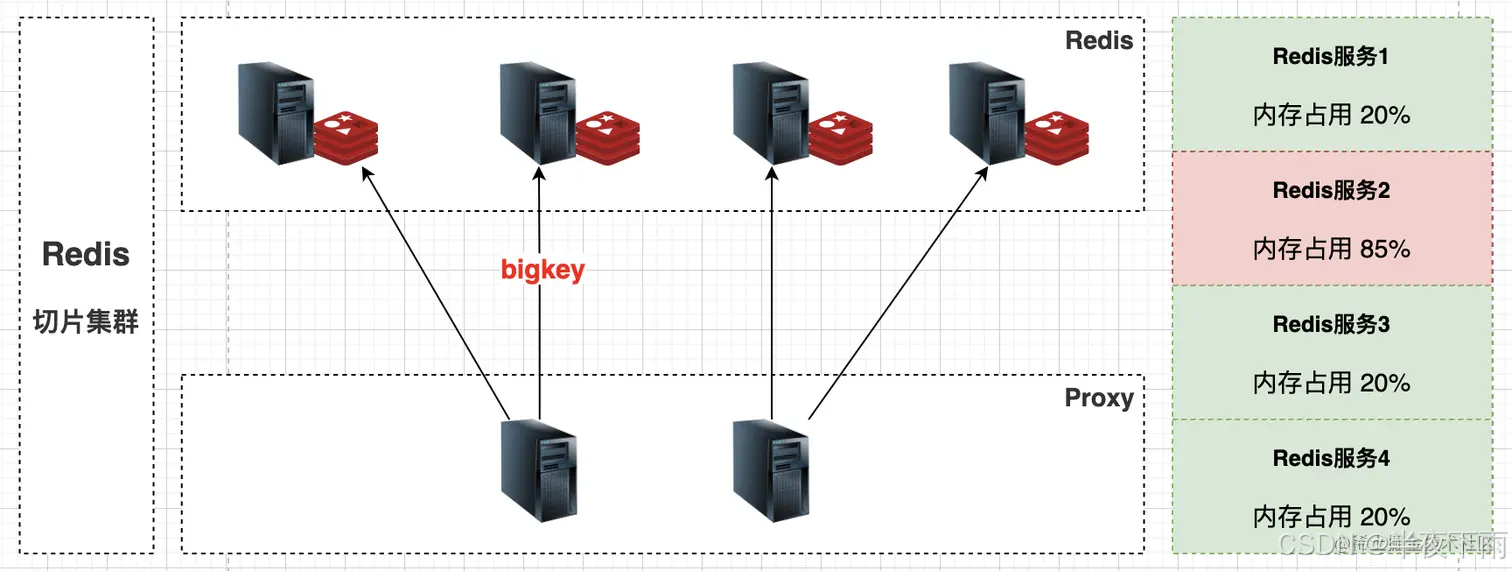
7.Redis大key如何解决?
设计上尽量合理,能拆分的就拆分,不能拆分的就能加上过期时间的就加上过期时间。

监控Redis的内存水位。可以通过监控系统设置合理的Redis内存报警阈值进行提醒,例如Redis内存使用率超过70%、Redis的内存在1小时内增长率超过20%等。
8.什么是热key?
经常被访问的key就是热点key。通常以其接收到的Key被请求频率来判定。
9.如何解决热key问题?

10.如何保证 redis 和 mysql 数据缓存一致性问题?
写:先写数据库,再删redis。
读:先读redis,未命中再读mysql,并写入redis。
缓存是通过牺牲强一致性来提高性能的。这是由CAP理论决定的。缓存系统适用的场景就是非强一致性的场景,它属于CAP中的AP。所以,如果需要数据库和缓存数据保持强一致,就不适合使用缓存。
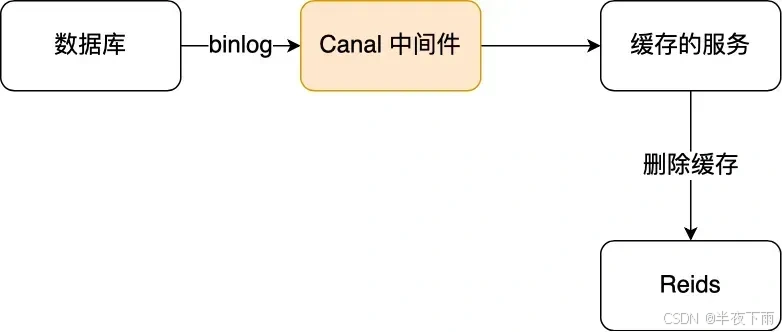
删redis的一些更加完善的工作:缓存延时双删,重试,订阅binlog+canal。
延时双删的步骤:
- 先删除缓存
- 再更新数据库
- 休眠一会(比如1秒),再次删除缓存。

删除缓存重试机制的大致步骤: - 写请求更新数据库
- 缓存因为某些原因,删除失败
- 把删除失败的key放到消息队列
- 消费消息队列的消息,获取要删除的key
- 重试删除缓存操作

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









