




1.mysql的是怎么解决并发问题的?
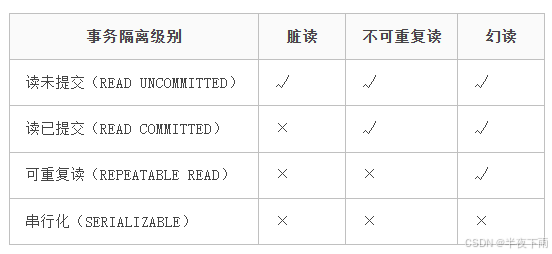
2.事务的隔离级别有哪些?
3.mysql默认级别是什么?
4.可重复读隔离级别下,A事务提交的数据,在B事务能看见吗?
5.举个例子说可重复读下的幻读问题
6.Mysql 设置了可重读隔离级后,怎么保证不发生幻读?
7.串行化隔离级别是通过什么实现的?
8.介绍MVCC实现原理
9.一条update是不是原子性的?为什么?
10.滥用事务,或者一个事务里有特别多sql的弊端?
1.mysql的是怎么解决并发问题的?
锁机制,事务隔离级别,MVCC多版本并发控制。
行级锁,表级锁,页级锁。
读未提交,读已提交,可重复读,串行化。

2.事务的隔离级别有哪些?
读未提交:一个事务还没有提交,但它的变更就会被别的事务看到。
读已提交:一个事务提交了它的变更才能被别的事务看到。
可重复读:一个事物,执行过程中面对的数据是一致的,这也是MySQL InnoDB的默认隔离级别。
串行化:利用锁机制,对于记录的读写操作只有获得锁的事务才能进行,实现串行化。
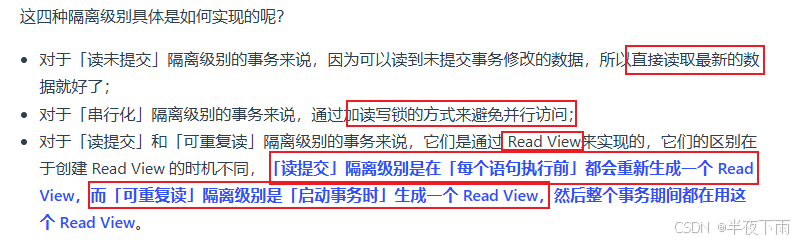
3.mysql默认级别是什么?
可重复读隔离级别。
4.可重复读隔离级别下,A事务提交的数据,在B事务能看见吗?
如果有更改,是看不到的,因为B事务在执行启动时会创建Read View,并在执行过程中始终使用这个Read View因此看不到A事务提交的更改数据。
具体:
可重复读隔离级是由 MVCC(多版本并发控制)实现的,实现的方式是开始事务后(执行 begin 语句后),在执行第一个查询语句后,会创建一个 Read View,后续的查询语句利用这个 Read View,通过这个 Read View 就可以在 undo log 版本链找到事务开始时的数据,所以事务过程中每次查询的数据都是一样的,即使中途有其他事务插入了新纪录,是查询不出来这条数据的。
5.举个例子说可重复读下的幻读问题?
涉及了可重复读的实现原理
在可重复读隔离级别下,Read View是在事务开始(begin)之后且执行第一条sql时创建,创建Read View的同时也就生成了一个新的事务id(直到commit结束),事务会依赖该 Read View保证查询结果保持不变直到该事务结束。
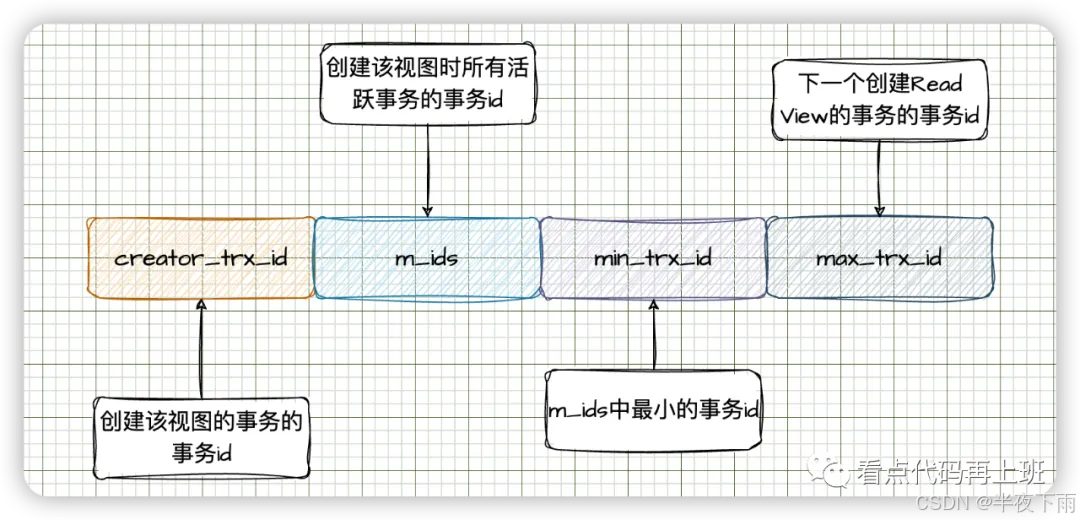
活跃事务则代表是已启动但未提交的事务。

6.Mysql 设置了可重读隔离级后,怎么保证不发生幻读?

7.串行化隔离级别是通过什么实现的?
串行化。
加锁。
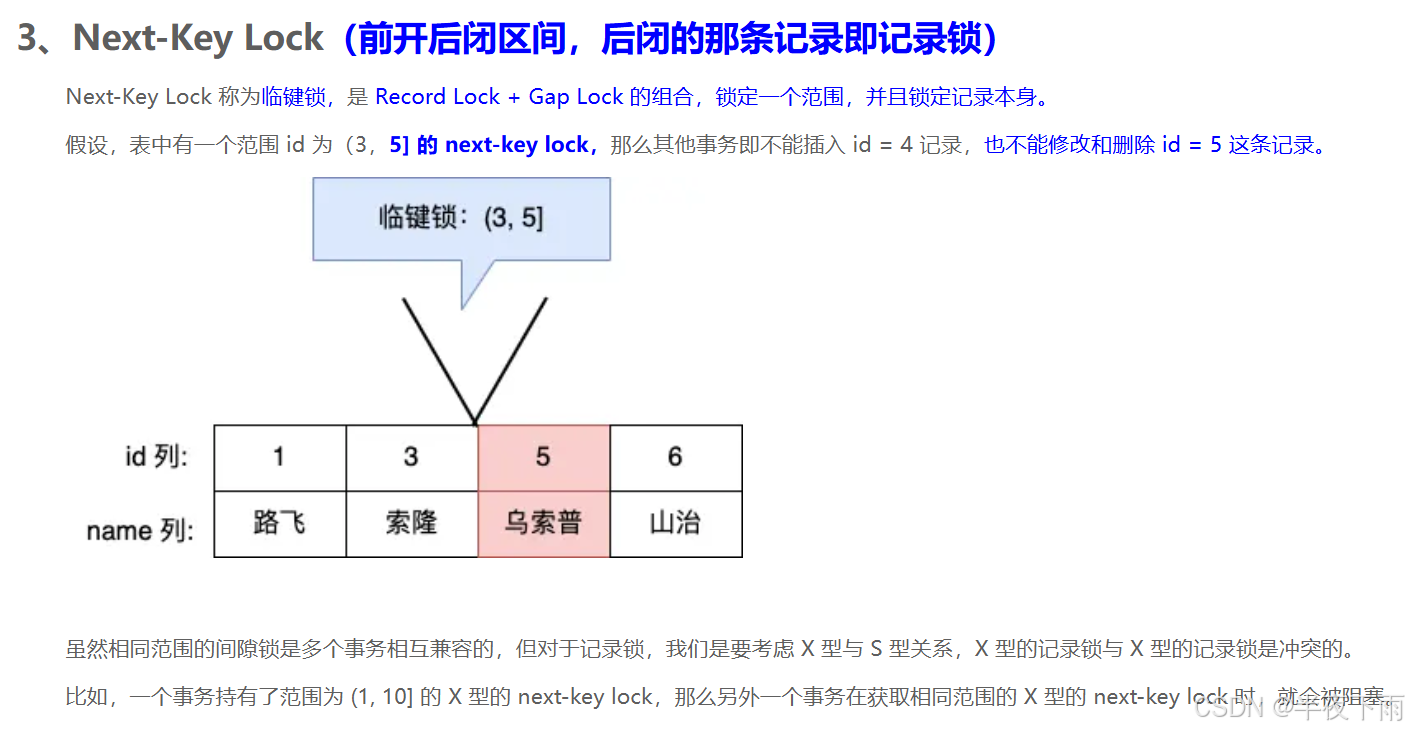
是通过行级锁来实现的,序列化隔离级别下,普通的select查询是会对记录加共享型的 next-key 锁,其他事务就没没办法对这些已经加锁的记录进行增删改操作了,从而避免了脏读、不可重复读和幻读现象。
共享锁(Shared Lock, S):允许多个事务同时读取数据,但不允许修改。
MySQL中的各种锁
8.介绍MVCC实现原理
Undo Log 链:Undo Log 链是指在每个数据对象上维护的 Undo Log 记录链表。每张表都会有与之相对应的 Undo Log 链,用于记录修改前的数据信息(以方便数据进行回滚)。
Read View(读视图或者叫一致性视图):
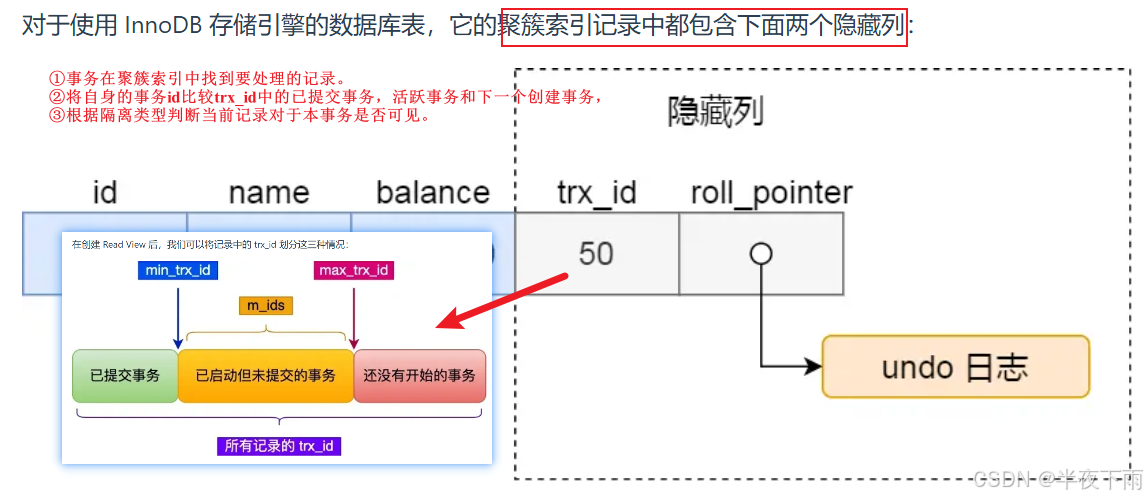
判断方法是根据 Read View 中的 4 个重要字段,先去 Undo Log 中最新的数据行进行比对,如果满足下面 Read View 的判断条件,则返回当前行的数据,如果不满足则继续查找 Undo Log 的下一行数据,直到找到满足的条件的数据为止,如果查询完没有满足条件的数据,则返回 NULL。
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
9.一条update是不是原子性的?为什么?
是原子性,主要通过锁+undo_log 日志保证原子性的。
执行 update 的时候,会加行级别锁,保证了一个事务更新一条记录的时候,不会被其他事务干扰。
事务执行过程中,会生成 undo_log,如果事务执行失败,就可以通过 undo_log 日志进行回滚。
10.滥用事务,或者一个事务里有特别多sql的弊端?
①:资源和锁的大量长时间占用,易导致死锁等。
②:undo_log记录量大。每一个更新sql都会有对应的回滚记录。
③:主从模式下,主从数据库处理时间长。
执行时间长,容易造成主从延迟,主库上必须等事务执行完成才会写入binlog,再传给备库。所以,如果一个主库上的语句执行10分钟,那这个事务很可能就会导致从库延迟10分钟。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









