




1.为什么 MysSQL 不用 跳表?
2.联合索引的实现原理?
3.创建联合索引时需要注意什么?
4.联合索引ABC,现在有个执行语句是A = XXX and C < XXX,索引怎么走?
5.联合索引(a,b,c) ,查询条件 where b > xxx and a = x 会生效吗?
6.联合索引 (a, b,c),where条件是 a=2 and c = 1,能用到联合索引吗?
7.索引失效有哪些?
8.什么情况下会回表查询?
9.什么是覆盖索引?
10.如果一个列即使单列索引,又是联合索引,单独查它的话先走哪个?
1.为什么MysSQL不用跳表?
对于相同的千万级数据,B+树可以利用2-5层完成存储,而跳表会构建过高的数据结果。那么会造成IO次数增加。
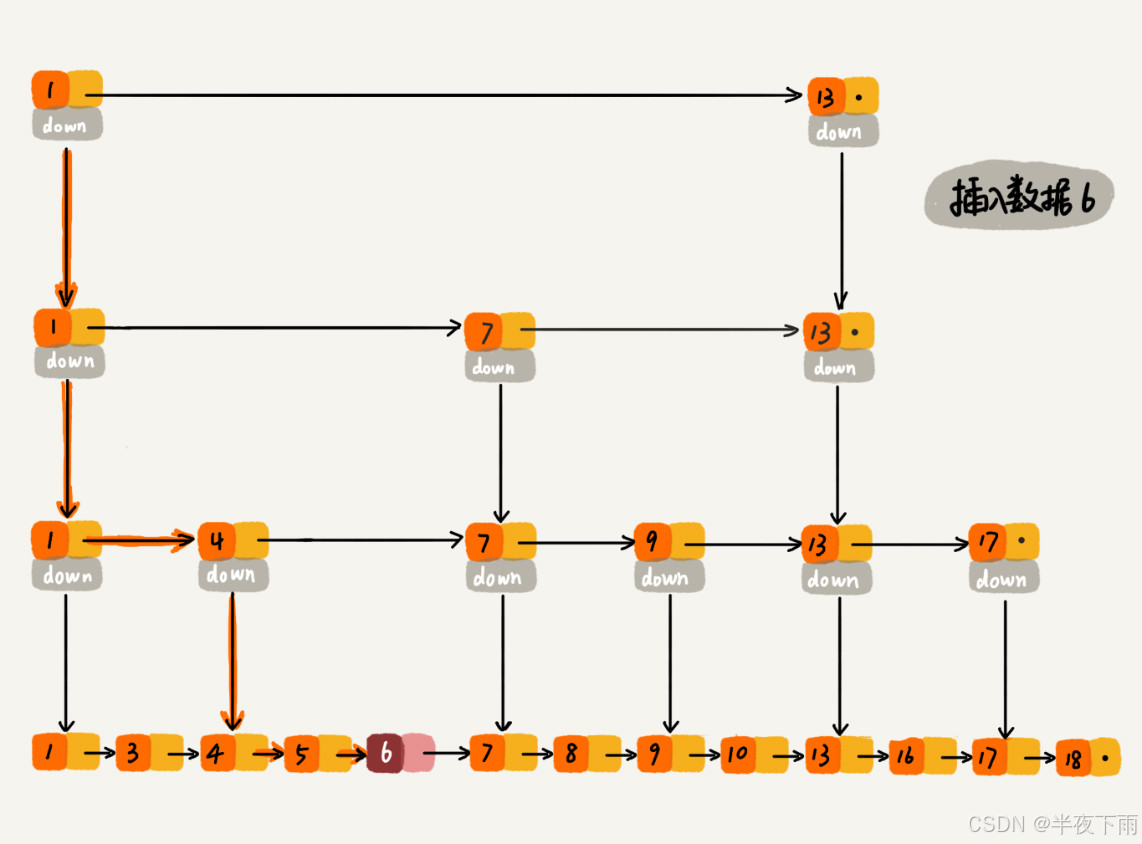
2.联合索引的实现原理?
将多个字段组合成一个索引,该索引就被称为联合索引。
CREATE INDEX index_product_no_name ON product(product_no, name);
(a), (a,b)(a,b,c)。需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。
利用索引的前提是索引里的 key 是有序的。
b 和 c 是全局无序,局部相对有序的。
3.创建联合索引时需要注意什么?
建立联合索引时的字段顺序,对索引效率也有很大影响。越靠前的字段被用于索引过滤的概率越高,实际开发工作中建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。
区分度就是某个字段 column 不同值的个数「除以」表的总行数。
4.联合索引ABC,现在有个执行语句是A = XXX and C < XXX,索引怎么走?
根据最左匹配原则,A可以走联合索引,C不会走联合索引,但是C可以走索引下推。
索引下推(index condition pushdown )简称 ICP,在 Mysql5.6 的版本上推出,用于优化查询。
在不使用 ICP 的情况下,在使用非主键索引(又叫普通索引或者二级索引)进行查询时,存储引擎通过索引检索到数据,然后返回给 MySQL 服务器,服务器然后判断数据是否符合条件 。
在使用 ICP 的情况下,如果存在某些被索引的列的判断条件时,MySQL 服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合 MySQL 服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给 MySQL 服务器 。
索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少 MySQL 服务器从存储引擎接收数据的次数。
5.联合索引(a,b,c) ,查询条件 where b > xxx and a = x 会生效吗?
索引会生效,a 和 b 字段都能利用联合索引,符合联合索引最左匹配原则。(a), (a,b)(a,b,c)。需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。
6.联合索引 (a, b,c),where条件是 a=2 and c = 1,能用到联合索引吗?
会用到联合索引,但是只有 a 才能走索引,c 无法走索引,因为不符合最左匹配原则。虽然 c 无法走索引, 但是 c 字段在 5.6 版本之后,会有索引下推的优化,能减少回表查询的次数。
7.索引失效有哪些?

第四点业务上能够避免。
8.什么情况下会回表查询?
从物理存储的角度来看,索引分为聚簇索引(主键索引)、二级索引(辅助索引)。
索引查询是,索引字段无法覆盖查询所需的所有列,因此会根据查询到的主键,从聚簇(cu,第四声)索引查找完整数据。
比较专业的话术:如果查询的数据不在二级索引里,就会先检索二级索引,找到对应的叶子节点,获取到主键值后,然后再检索主键索引,就能查询到数据了,这个过程就是回表。
9.什么是覆盖索引?
索引即是查询所需。不需要回表查询更多的数据。
比较准确的说法:覆盖索引是指一个索引包含了查询所需的所有列,因此不需要访问表中的数据行就能完成查询。从而减少查询次数,减少IO操作。
10.如果一个列即使单列索引,又是联合索引,单独查它的话先走哪个?
mysql 优化器会分析每个索引的查询成本,然后选择成本最低的方案来执行 sql。
如果单列索引是 a,联合索引是(a ,b),那么针对下面这个查询:
select a, b from table where a = ? and b =?;
那么当然是选择联合索引,因为查询成本低,并且不需要回表(因为索引完全覆盖了查询所需)。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









