



1)NAS PB、SPEC CPU 2006和PolyBench套件
2)对于具有周期性边界条件的格子玻尔兹曼方法(LBM)模拟,它在冥王星上提供了1.33倍的平均加速。
这个冥王星指的就是Pluto
也是一个具体Case
3)具体得看论文中的测试数据集是啥
但是,我觉得效果可能并不好,否则为什么没有在其他地方大规模用?
4)Some efficient solutions to the affine scheduling problem. I. One-dimensional time
递归方程的程序和系统可以表示为在优先级约束下执行的动作集。在某些情况下,动作可以在某些迭代域中用积分向量标记,优先级约束可以用仿射关系描述。这种程序的时间表是为每个动作分配执行数据的函数。了解这样的时间表可以估计程序的内在并行程度,并为多处理器架构或收缩阵列编译并行版本。本文研究了将闭式调度作为迭代向量的仿射或分段仿射函数的问题。提出了一种算法,该算法将调度问题简化为一个小尺寸的参数线性规划,可以通过高效的算法轻松求解。
将依赖问题转化成线性规划问题,这个没有问题,也是正确的。
但是如果设置优化目标呢?
5)A practical automatic polyhedral parallelizer and locality optimizer
我们提出了一种自动多面体源到源转换框架的设计和实现,该框架可以同时优化常规程序(可能不完全嵌套的循环序列)的并行性和局部性。通过这项工作,我们展示了多面体模型中分析模型驱动的自动转换的实用性,远远超出了当前生产编译器的可能范围。与之前的工作不同,我们的方法是一种端到端的全自动方法,由整数线性优化框架驱动,该框架明确认为可以使用仿射变换找到并行性和局部性的良好平铺方法。该框架已被实现为一个工具,用于从C程序段自动生成OpenMP并行代码。该工具的实验结果表明,与研究界最先进的编译器框架以及最好的本地生产编译器相比,在多核上本地和并行执行的速度非常快。该系统还可以轻松使用强大的经验/迭代优化来处理一般的任意嵌套循环序列。
这应该是所有故事的起源。
6)
沿i轴方向上的所有循环迭代之间不存在依赖,也就是处在同一水平面上的循环迭代是可以并行执行的。但是现在没有考虑到如何使用t轴和i轴方向上的数据局部性。当N和T较大时,这种计算方式Cache的命中率就会下降。一个很自然的优化目标是如何让编译器能够自动计算出能够充分利用沿多个轴上的数据局部性,这种任务是通过循环分块来完成的。所以,Pluto算法的一个非常重要的目标是通过变换让上述程序能够实现循环分块。
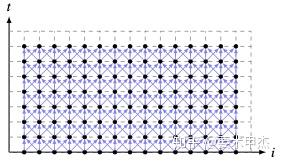
pluto是基于数据的依赖的分析,这个是对的。
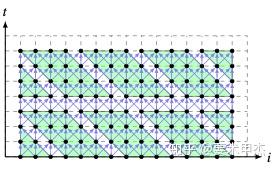
循环分块方法1:
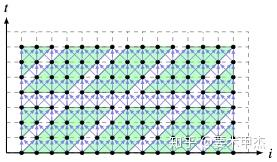
循环分块方法2:
循环分块方法3:
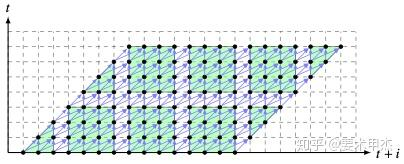
也构建了一个代价模型:
Pluto算法的代价模型
8)问题:
如何把循环及依赖转化成多面体,或者整数规划问题?


















 3307
3307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









