




 本文详述了使用Python的Selenium库在Chrome中编写脚本,搜索知网论文,处理异步加载,抓取PDF链接并下载的过程。
本文详述了使用Python的Selenium库在Chrome中编写脚本,搜索知网论文,处理异步加载,抓取PDF链接并下载的过程。
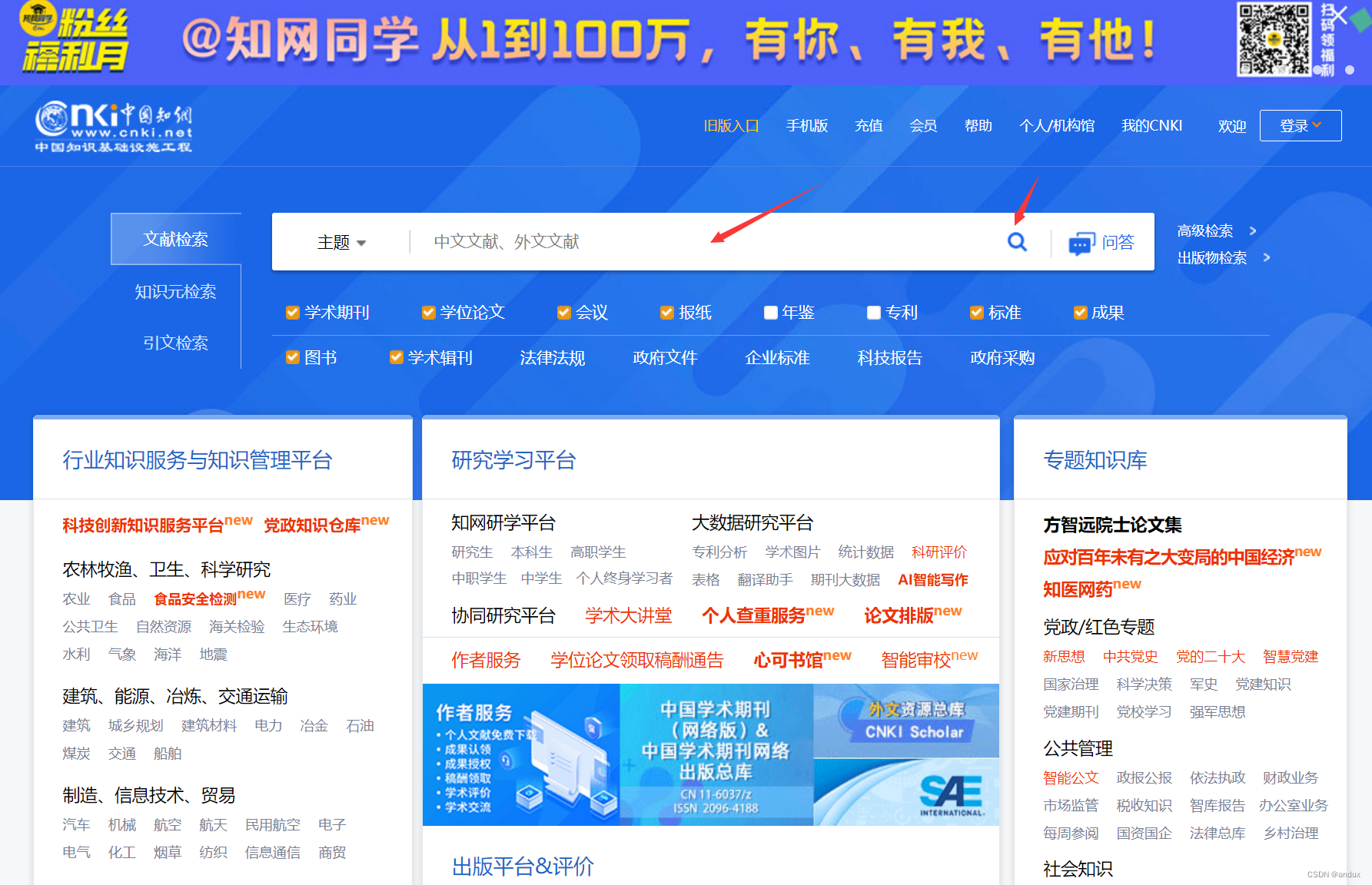
要想自动下载知网期刊论文,先要在chrome浏览器里登录好帐号密码。然后在输入框里输入搜索词语,点击搜索按钮。注意自己的网速,设置好暂停的秒数后,再往下执行。
app.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
from selenium.webdriver import ActionChains
service = Service(executable_path="./driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)
url = "https://www.cnki.net/"
driver.get(url=url)
try:
title_input = driver.find_element(By.XPATH, '//input[@id="txt_SearchText"]')
ActionChains(driver=driver).click(title_input).send_keys("教学设计").perform()
title_enter = driver.find_element(By.XPATH, '//input[@class="search-btn"]')
ActionChains(driver).click(title_enter).perform()
# ActionChains(driver).scroll_by_amount(0, 200).perform()
time.sleep(5)
tag_as  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2841
2841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











