




CrawlSpider可以根据给定的规则自动爬取链接里的子页面的内容。
创建一个新的CrawlSpider项目,跟创建其他scrapy的Spider项目命令一样:
scrapy startproject scrapy_02
进入到spiders目录中:
cd .\scrapy_02\scrapy_02\spiders\
要爬取的页面是http://seller.cheshi.com/wuhan/:
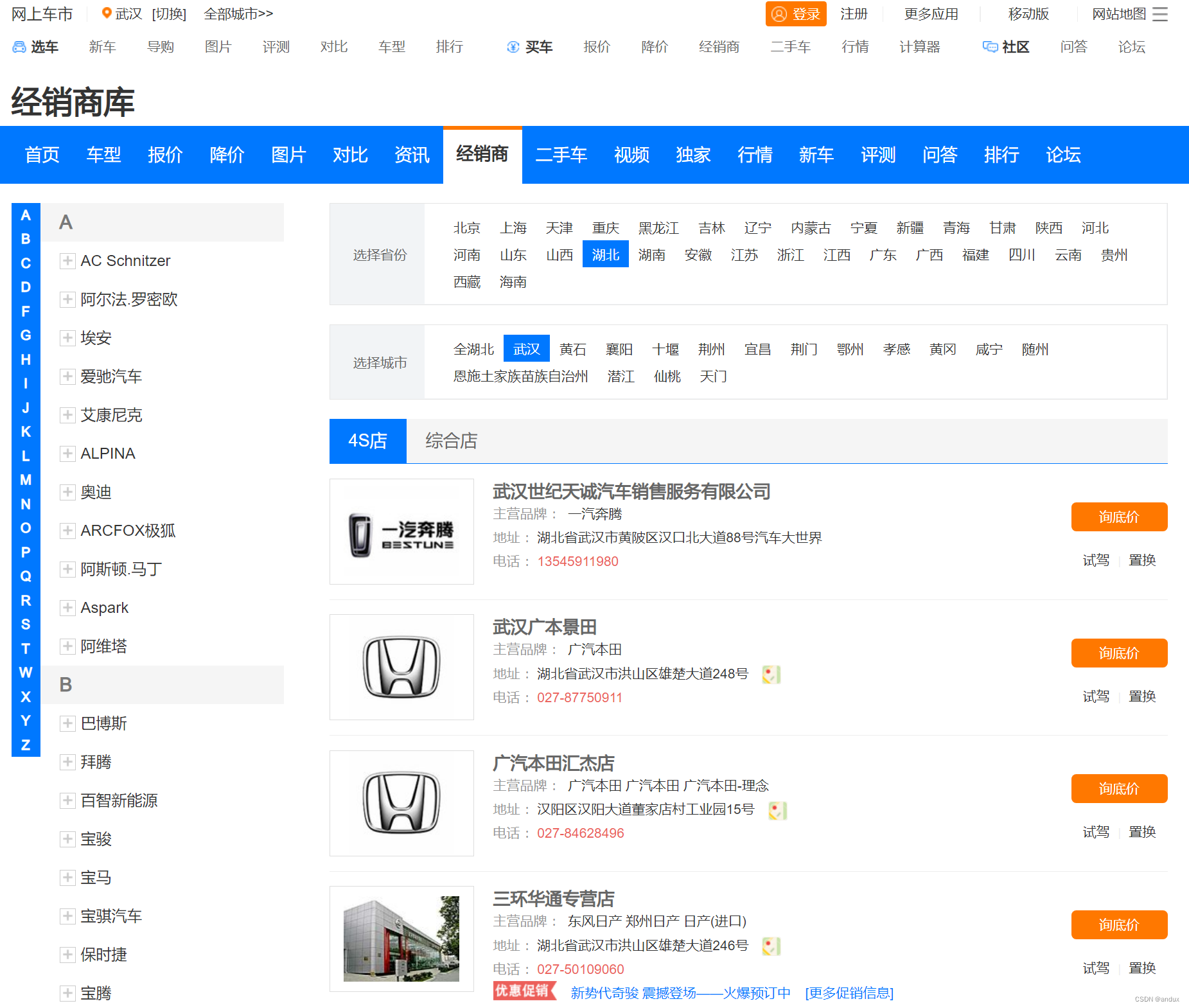
想要获取每个经销商的链接,并通过链接进入到子页面,从子页面里获取经销商的名称,经销商的认证等级。
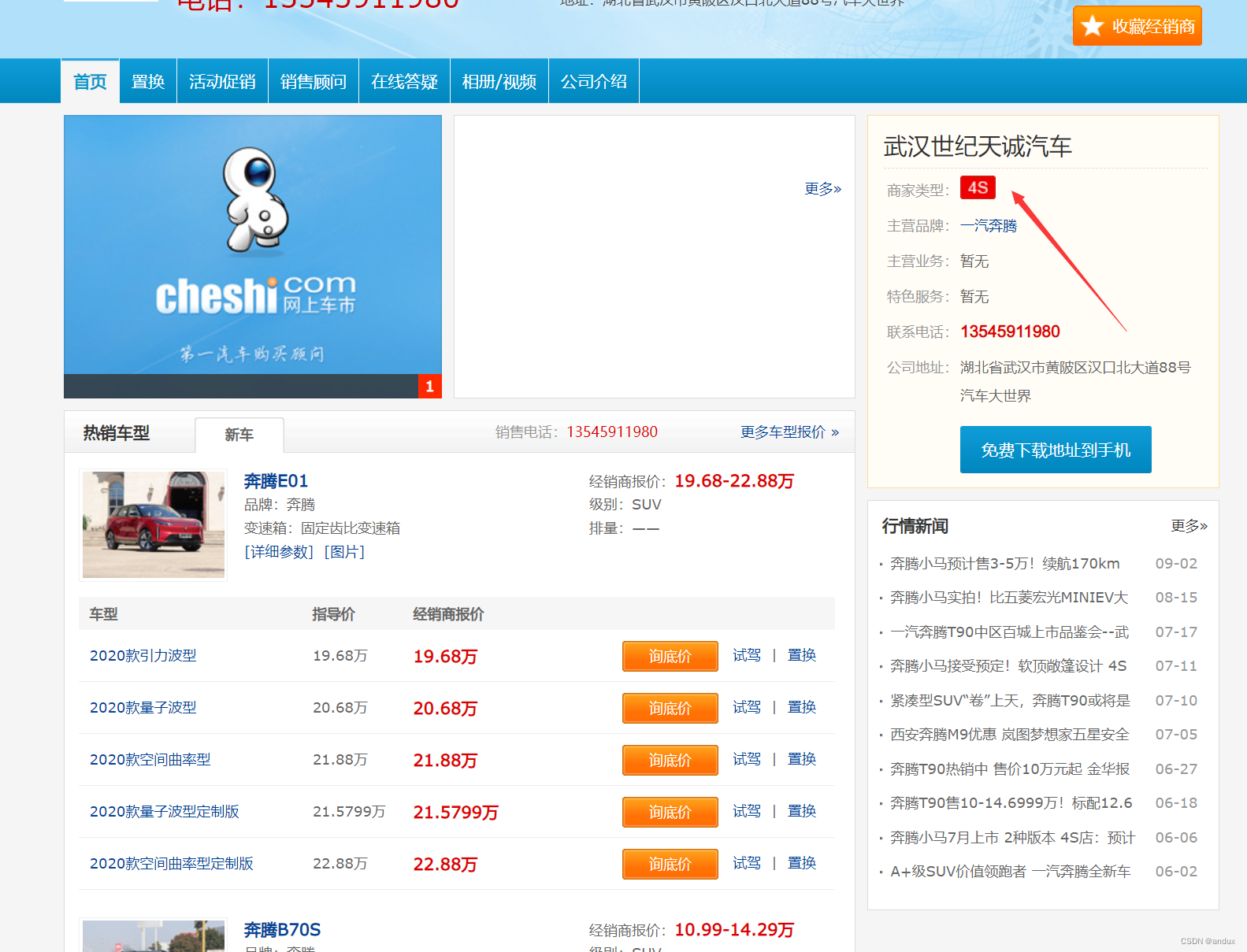
创建app逻辑代码文件:
scrapy genspider -t crawl app http://seller.cheshi.com/wuhan/
具体的app.py页面逻辑代码:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class AppSpider(CrawlSp 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











