




部署拓扑图
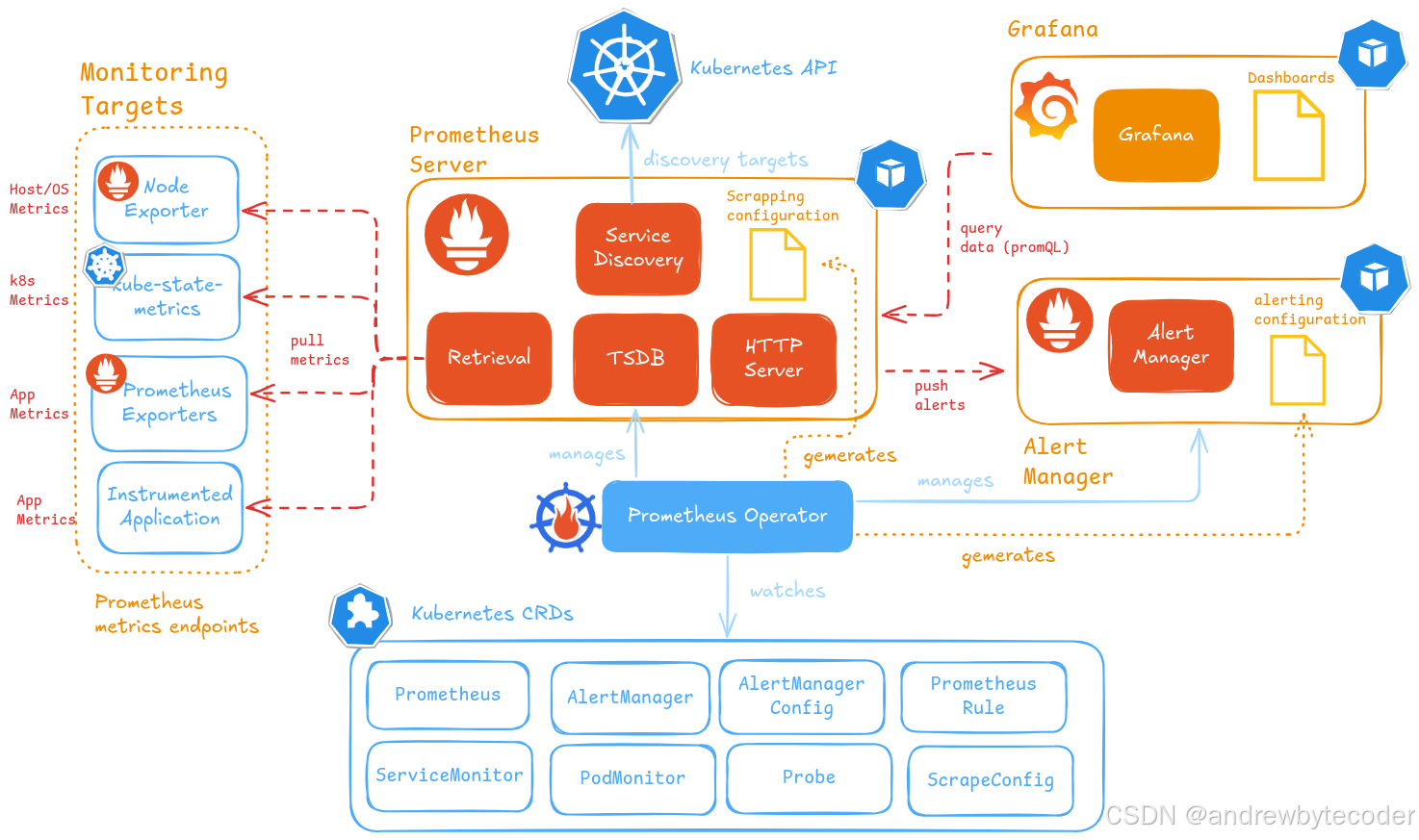
kube-prometheus 是一个用于在 Kubernetes 集群中部署和管理 Prometheus 监控栈的开源项目,由 CoreOS(现 Red Hat) 团队维护,是云原生生态中最流行、最完整的 Kubernetes 监控解决方案之一。
🌟 什么是 kube-prometheus?
kube-prometheus 并不是一个单独的二进制程序,而是一组 Kubernetes 清单(manifests)和工具的集合,用于快速部署一套完整的监控系统,包括:Prometheus、Alertmanager、Grafana、Node Exporter、Kube State Metrics 等,并通过 Prometheus Operator 进行声明式管理。
它基于 Prometheus Operator 构建,使用 Custom Resource Definitions (CRDs) 来简化 Prometheus 和 Alertmanager 的配置与管理。
🧩 核心组件
| 组件 | 作用 |
|---|---|
| Prometheus Operator | 管理 Prometheus、ServiceMonitor、Alertmanager 等 CRD,自动创建和配置 Prometheus 实例 |
| Prometheus | 时序数据库,采集和存储监控指标 |
| Alertmanager | 处理告警,支持去重、分组、静默、路由到 Slack/Email/Webhook 等 |
| Grafana | 可视化仪表盘,展示 Prometheus 数据 |
| node-exporter | 采集节点(Node)的硬件和操作系统指标(CPU、内存、磁盘、网络等) |
| kube-state-metrics | 将 Kubernetes 对象(Pod、Deployment、Node 等)的状态转换为 Prometheus 指标 |
| prometheus-adapter | 将 Prometheus 指标暴露为 Kubernetes Metrics API,支持 HPA 基于自定义指标扩缩容 |
✅ 主要功能与优势
1. 开箱即用的完整监控栈
- 一键部署 Prometheus + Alertmanager + Grafana + Exporters
- 预配置了大量 Kubernetes 相关的监控规则和告警
2. 声明式配置(CRD)
通过 Kubernetes CRD 管理监控组件:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: k8s
spec:
serviceAccountName: prometheus
ruleSelector:
matchLabels:
role: alert-rules
resources:
requests:
memory: 400Mi
3. 自动服务发现
使用 ServiceMonitor 自动发现要监控的服务:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
spec:
selector:
matchLabels:
app: my-app
endpoints:
- port: web
interval: 15s
只要服务带有
app: my-app标签,Prometheus 就会自动开始采集其指标。
4. 预置告警规则
包含大量针对 Kubernetes 的告警规则,例如:
KubeNodeNotReadyKubePodCrashLoopingKubeStatefulSetReplicasMismatchTargetDown
5. 预置 Grafana 仪表盘
提供多个开箱即用的 Grafana 仪表盘:
- Kubernetes / Compute Resources / Cluster
- Kubernetes / Compute Resources / Namespace (Pods)
- Kubernetes / Networking / Namespace (Pods)
- Prometheus / Overview
🚀 快速部署(使用 Jsonnet + kubectl)
方法一:使用 Jsonnet(推荐)
# 1. 克隆仓库
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus
# 2. 生成清单
./build.sh example
# 3. 应用到集群
kubectl create -f manifests/setup
# 等待 CRDs 创建
kubectl create -f manifests/
方法二:使用 Helm(社区维护)
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack
注意:Helm 版本是
kube-prometheus-stack,功能类似但配置方式不同。
🔍 典型监控指标
| 指标类别 | 示例指标 |
|---|---|
| 节点资源 | node_cpu_seconds_total, node_memory_MemAvailable_bytes |
| Pod 资源 | container_cpu_usage_seconds_total, container_memory_usage_bytes |
| K8s 对象状态 | kube_pod_status_phase, kube_deployment_status_replicas_available |
| API Server | apiserver_request_total, etcd_db_total_size_in_bytes |
| 网络 | pod_network_receive_bytes_total, coredns_dns_request_count_total |
📊 访问 Grafana
部署完成后,可通过端口转发访问 Grafana:
kubectl --namespace default port-forward svc/kube-prometheus-stack-grafana 3000
- 浏览器访问:
http://localhost:3000 - 默认用户名:
admin - 默认密码:
prom-operator
⚠️ 注意事项
| 项目 | 说明 |
|---|---|
| 资源消耗 | Prometheus 本身可能消耗较多内存和存储,需根据集群规模调整资源配置 |
| 持久化 | 生产环境建议为 Prometheus 配置 PVC 持久化存储 |
| 高可用 | 默认部署是单实例,生产环境需配置 HA |
| 版本兼容性 | 注意 kube-prometheus 版本与 Kubernetes 版本的兼容性 |
| 升级 | 建议参考官方 release notes 和迁移指南 |
🔄 与其他方案对比
| 方案 | 特点 |
|---|---|
| kube-prometheus | 功能完整,适合自建,基于 CRD 管理,学习曲线略高 |
| Prometheus Operator(裸用) | 更灵活,但需手动配置更多组件 |
| Helm Chart (kube-prometheus-stack) | 部署简单,适合快速上手 |
| 托管服务(如 AWS AMP, GCP Managed Prometheus) | 无需运维,但成本高,灵活性低 |


















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











