




 本文探讨了如何利用先进的信息抽取技术,包括深度学习的自然语言处理、实体识别、关系抽取和事件抽取,提升汽车设计过程中的数据处理效率和决策质量。通过实例展示了这些技术如何帮助提取关键参数、理解组件功能和优化设计过程,最终推动行业进步。
本文探讨了如何利用先进的信息抽取技术,包括深度学习的自然语言处理、实体识别、关系抽取和事件抽取,提升汽车设计过程中的数据处理效率和决策质量。通过实例展示了这些技术如何帮助提取关键参数、理解组件功能和优化设计过程,最终推动行业进步。
一、引言
在汽车行业,设计创新和数据驱动的决策是推动技术进步和市场竞争力的关键。我曾领导一个项目,专注于从海量信息中提取有价值的数据,以支持汽车设计过程。这个项目的核心在于运用先进的信息抽取技术,从各种文档、报告和在线资源中提取关键参数和性能指标,从而为汽车工程师提供精确的数据支持。通过这种方式,我们不仅提高了设计效率,还确保了新车型在性能、安全和环保方面的卓越表现。在这篇文章中,我将分享我们如何利用这些技术,以及它们如何改变了汽车设计的游戏规则。
二、用户案例
在项目初期,我们面临着一个巨大的挑战:如何在众多汽车设计资料中快速准确地找到所需的参数和属性。例如,我们需要确定新车型的空气动力学特性,这涉及到从技术文档中提取精确的阻力系数。传统的手动搜索不仅耗时,而且容易出错。这时,信息抽取技术成为了我们的救星。通过参数与属性抽取功能,我们能够自动从文本中识别出关键数值,如阻力系数、重量分布等,并将这些参数与相应的汽车实体关联起来。这大大加快了我们的数据收集速度,并且提高了数据的准确性。
在项目进行中,我们遇到了另一个问题:如何从复杂的技术报告中识别出汽车的各个组件及其功能。这时,实体抽取技术发挥了关键作用。它帮助我们识别出文本中提到的各种汽车组件,如发动机、刹车系统、悬挂装置等,并理解它们的功能和特性。这不仅让我们能够更好地理解汽车的整体结构,还为后续的设计优化提供了坚实的基础。
随着项目的深入,我们开始关注汽车设计中各个组件之间的相互作用。关系抽取技术在这时显得尤为重要。它帮助我们理解了组件之间的连接关系,例如,发动机如何驱动车轮,以及刹车系统如何与悬挂系统相互作用。这些关系对于确保汽车的整体性能至关重要。通过关系抽取,我们能够构建出一张详细的汽车组件关系图,这对于指导设计决策和预防潜在的工程问题具有极大的价值。
在项目后期,我们面临着如何将这些复杂的设计信息整合到一个动态的知识库中。事件抽取技术在这方面起到了关键作用。它不仅帮助我们追踪了汽车设计过程中的关键事件,如测试阶段的里程碑,还让我们能够理解这些事件背后的因果关系。例如,我们能够分析出某个设计变更是如何影响整体性能的。这些信息的整合,使得我们的知识库不仅包含了静态的数据,还具备了动态的事件序列,为汽车设计的持续改进提供了强大的支持。
通过这些信息抽取技术的应用,我们的项目团队能够更加高效地处理大量数据,确保设计决策基于最准确和最新的信息。这些技术不仅提高了我们的工作效率,还为汽车设计带来了革命性的变革。
三、技术原理
在汽车设计领域,信息抽取技术的应用极大地促进了设计流程的优化和创新。深度学习技术,尤其是自然语言处理(NLP)的进展,为从无结构化文本中提取信息提供了强大的工具。预训练语言模型如BERT、GPT和XLNet,通过在大规模文本数据集上的训练,掌握了语言的深层结构和丰富语义,为信息抽取任务奠定了基础。这些模型通过任务特定的微调,能够适应特定的信息需求,如实体识别、关系抽取或事件抽取。
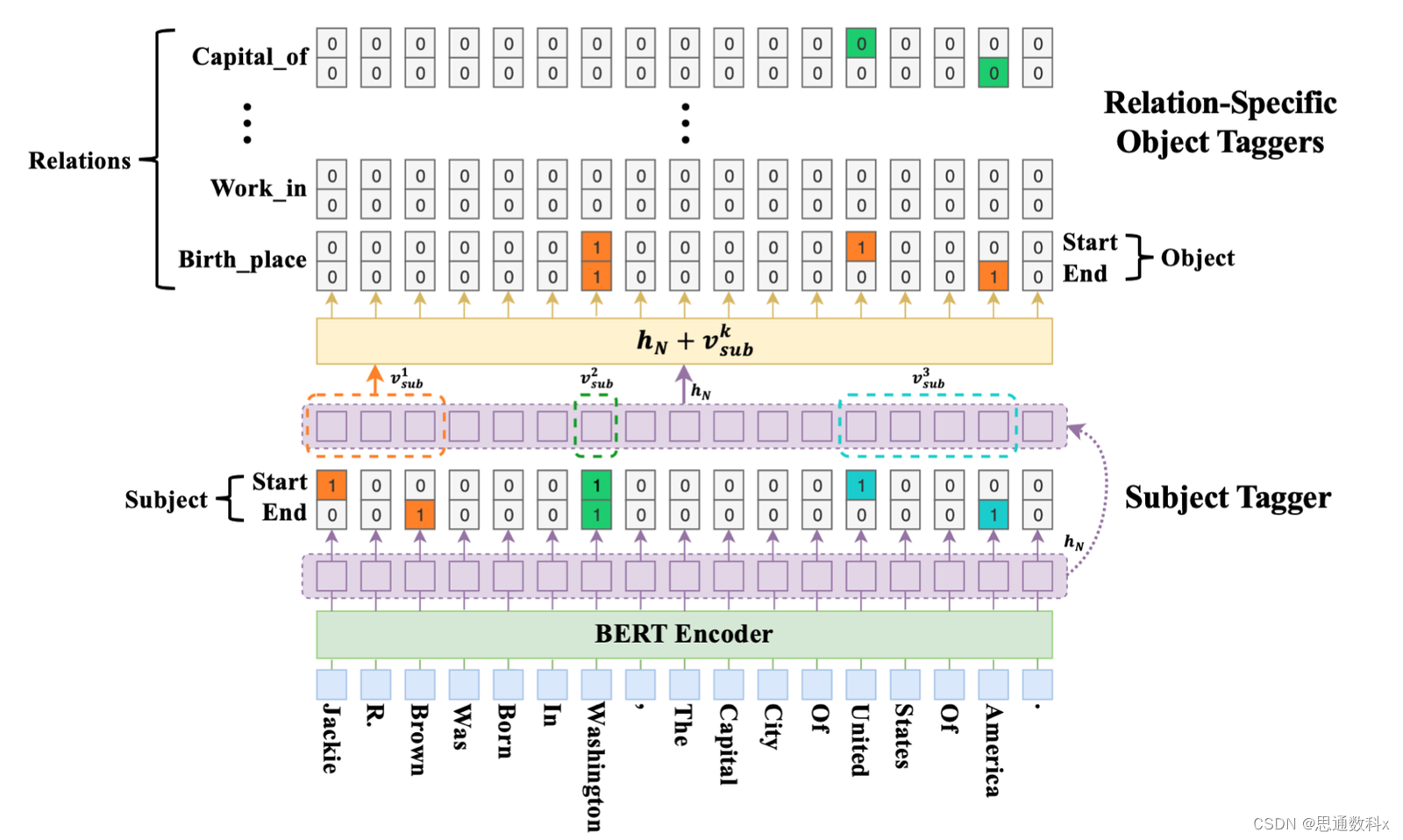
在实体识别任务中,深度学习模型通过序列标注技术,将文本中的词汇标注为特定类别,如人名、地名或汽车组件。这一过程通常依赖于条件随机场(CRF)或双向长短时记忆网络(BiLSTM),它们能够有效捕捉文本中的长距离依赖关系。对于更复杂的任务,如问答系统或摘要生成,序列到序列(Seq2Seq)模型,尤其是基于注意力机制的Transformer模型,被用来将输入序列转换为输出序列,理解上下文信息并生成相关输出。
整个模型的训练过程是端到端的,即从输入到输出的整个过程在一个统一的训练框架下进行优化。这种训练方式有助于提升模型的整体性能。在训练过程中,模型的性能通过准确率、召回率、F1分数等指标进行评估,根据评估结果,可以对模型进行调整,如调整学习率、优化网络结构或增加训练数据,以提高信息抽取的准确性。
在汽车设计项目中,这些技术的应用使得团队能够快速准确地从大量文档中提取关键参数和性能指标。例如,通过参数抽取,团队能够自动识别出技术文档中的阻力系数、重量分布等关键数值,并将这些参数与相应的汽车实体关联。实体抽取技术帮助团队识别出文本中提到的汽车组件,如发动机、刹车系统等,并理解它们的功能和特性。关系抽取技术则揭示了组件之间的连接关系,如发动机与车轮的驱动关系,以及刹车系统与悬挂系统的相互作用。事件抽取技术则追踪了设计过程中的关键事件,如测试阶段的里程碑,并分析了这些事件背后的因果关系。
这些技术的应用不仅提高了设计效率,还确保了新车型在性能、安全和环保方面的卓越表现。通过构建动态的知识库,团队能够整合静态数据和动态事件序列,为汽车设计的持续改进提供了坚实的数据支持。这些技术的应用,无疑为汽车设计带来了革命性的变革,推动了行业的进步。
四、技术实现
在我们的汽车设计项目中,为了处理信息抽取的复杂性,我们采用了一个现成的自然语言处理(NLP)平台。这个平台提供了一整套工具,使我们能够高效地从文本数据中提取所需的信息,而无需深入研究底层的技术细节。
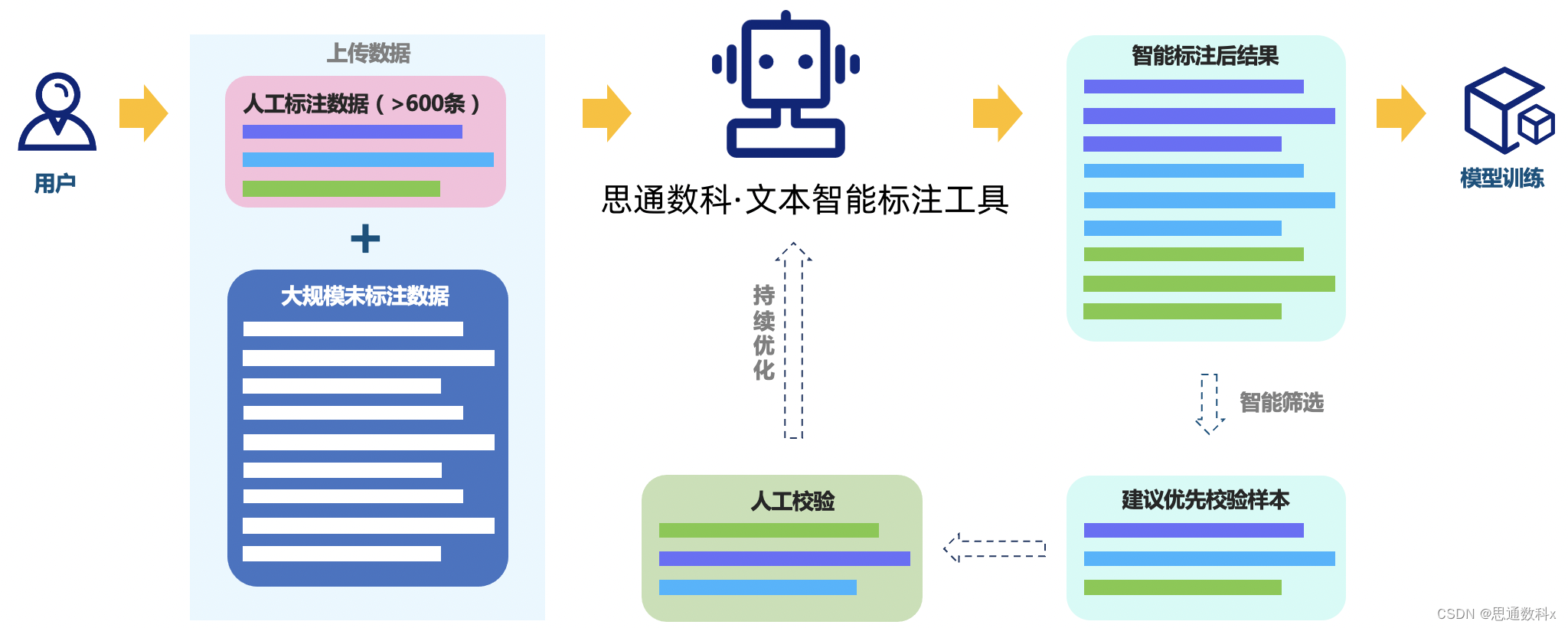
我们首先进行了数据收集,搜集了50至200条与项目紧密相关的数据样本。这些样本覆盖了项目所需的各种情况,为我们的训练和评估提供了丰富的数据基础。随后,我们对这些数据进行了清洗,去除无关信息,纠正拼写错误,并标准化了术语,以确保数据质量。
在数据清洗之后,我们使用平台提供的在线标注工具对样本进行了标注。这个工具极大地简化了标注过程,使我们能够快速准确地标记文本中的实体和关系。为了确保标注的一致性和质量,我们进行了多轮的标注和校对。
标注完成后,我们利用平台提取了文本特征,如词性标注和命名实体识别(NER),并进行了依存句法分析。这些特征对于训练我们的模型至关重要。我们使用这些标注好的数据样本来训练模型,并通过调整模型参数来优化其性能。
在模型训练阶段,我们选择了适当的评估指标,如精确度、召回率和F1分数,来衡量模型的性能。我们采用了交叉验证等方法来确保模型的泛化能力,并根据评估结果进行了多次迭代,以达到最佳性能。
最后,我们将训练好的模型部署到生产环境中,以便对新的文本数据进行信息抽取。模型能够接收新的文本输入,并自动执行信息抽取任务,输出结构化的结果。整个过程通过Web界面完成,无需编写任何代码,极大地提高了我们的工作效率。
通过NLP能力平台,我们的团队能够专注于汽车设计的核心任务,而不是被复杂的技术细节所困扰。这不仅提高了我们的工作效率,也确保了我们能够基于最准确和最新的信息做出设计决策。这种技术的应用,无疑为汽车设计领域带来了新的视角和可能性。
伪代码示例
在汽车设计项目中,我们利用了先进的NLP平台来实现信息抽取功能。以下是我们使用该平台的伪代码示例,以及预期的输出结果。
import requests
# 设置请求头,包含请求密钥
headers = {
'secret-id': '你的secret-id',
'secret-key': '你的secret-key'
}
# 设置请求参数
data = {
'text': '这里是汽车设计相关的文本内容,不超过5000个字符。',
'sch': '汽车,设计,参数,性能,指标', # 抽取范围
'modelID': 1 # 模型ID,根据实际情况选择
}
# 发送POST请求到NLP平台
response = requests.post('https://nlp.stonedt.com/api/extract', headers=headers, json=data)
# 解析返回的数据
if response.status_code == 200:
# 输出抽取结果
result = response.json()
print("抽取结果:")
for entity_type, entities in result['result'][0].items():
for entity in entities:
print(f"{entity_type}: {entity['text']} (准确率: {entity['probability']:.2f}, 起始位置: {entity['start']}, 结束位置: {entity['end']})")
else:
print("请求失败,状态码:", response.status_code)
# 预期的JSON格式输出示例
# {
# "msg": "自定义抽取成功",
# "result": [
# {
# "汽车": [
# {"probability": 0.98, "start": 50, "end": 58, "text": "特斯拉Model S"},
# ...
# ],
# "设计": [
# ...
# ],
# ...
# }
# ],
# "code": "200"
# }
注释:在这段伪代码中,我们首先设置了请求头,包含了必要的认证信息。然后,我们定义了请求参数,包括待抽取的文本内容、抽取范围和模型ID。接着,我们使用`requests`库发送POST请求到NLP平台,并解析返回的数据。如果请求成功,我们将输出每个实体的抽取结果,包括实体文本、准确率以及在原始文本中的起始和结束位置。
通过这种方式,我们能够自动化地从大量文本中提取关键信息,极大地提高了数据处理的效率和准确性。这使得我们的团队能够专注于设计创新,而不是被繁琐的数据整理工作所困扰。
数据库表结构
在文章的下一节中,我将展示如何使用数据定义语言(DDL)语句来设计数据库表结构,以便存储从NLP平台接口返回的数据。以下是基于前文描述的数据库表结构的DDL语句:
CREATE TABLE IF NOT EXISTS extracted_data (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '唯一标识符,自动递增',
text_content TEXT NOT NULL COMMENT '存储原始文本内容',
entity_label VARCHAR(255) NOT NULL COMMENT '实体标签,如症状、药物等',
entity_text VARCHAR(255) NOT NULL COMMENT '实体文本,即实体的具体名称或描述',
start_position INT NOT NULL COMMENT '实体在原始文本中的起始位置',
end_position INT NOT NULL COMMENT '实体在原始文本中的结束位置',
probability FLOAT NOT NULL COMMENT '实体识别的准确率得分',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录最后更新时间,自动更新'
);
在这个DDL语句中,我们创建了一个名为`extracted_data`的表,它包含了以下字段:
- `id`:一个自增的主键,用于唯一标识每条抽取数据。
- `text_content`:一个文本字段,用于存储原始文本内容。
- `entity_label`:一个字符串字段,用于存储实体的标签,如“汽车”、“设计”等。
- `entity_text`:一个字符串字段,用于存储与实体标签对应的文本内容。
- `start_position`和`end_position`:两个整数字段,分别表示实体在原始文本中的起始和结束位置。
- `probability`:一个浮点数字段,表示实体抽取的准确率得分。
- `created_at`和`updated_at`:两个时间戳字段,分别记录数据创建和最后更新的时间。`updated_at`字段在每次数据更新时自动设置为当前时间。
这个表结构的设计旨在确保我们能够有效地存储和查询从NLP平台接口返回的数据,同时保持数据的一致性和完整性。通过这种方式,我们可以轻松地管理和分析抽取的数据,为汽车设计项目提供支持。
五、项目总结
本项目的成功实施,显著提升了我们团队在汽车设计领域的工作效率和决策质量。通过采用先进的信息抽取技术,我们不仅缩短了从数据收集到分析的周期,还显著提高了数据的准确性和可靠性。具体而言,我们的团队能够快速识别并整合关键设计参数,如阻力系数和重量分布,这些参数的精确提取对于新车型的空气动力学特性至关重要。此外,实体抽取技术的应用使我们能够清晰地理解汽车组件的功能和特性,为设计优化提供了坚实的基础。关系抽取技术进一步揭示了组件间的相互作用,这对于确保整体性能和预防潜在工程问题具有重大意义。
在项目后期,事件抽取技术的应用使我们能够追踪设计过程中的关键里程碑,理解设计变更对整体性能的影响,从而为持续改进提供了数据支持。这些技术的综合应用,不仅提高了设计效率,还确保了新车型在性能、安全和环保方面的卓越表现。通过构建动态的知识库,我们为汽车设计的持续创新奠定了坚实的数据基础,推动了整个行业的技术进步。
六、开源项目(本地部署,永久免费)
思通数科的多模态AI能力引擎平台是一个企业级解决方案,它结合了自然语言处理、图像识别和语音识别技术,帮助客户自动化处理和分析文本、音视频和图像数据。该平台支持本地化部署,提供自动结构化数据、文档比对、内容审核等功能,旨在提高效率、降低成本,并支持企业构建详细的内容画像。用户可以通过在线接口体验产品,或通过提供的教程视频和文档进行本地部署。


















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









