



 本文介绍了一个实时推荐系统的构建过程,涵盖用户画像、视频画像、异步化计算等关键技术点,并详细解析了流式技术在推荐系统中的应用。
本文介绍了一个实时推荐系统的构建过程,涵盖用户画像、视频画像、异步化计算等关键技术点,并详细解析了流式技术在推荐系统中的应用。
前言
这个月做的事情还是蛮多的。上线了一个百台规模的ES集群,还设计开发了一套实时推荐系统。 标题有点长,其实是为了突出该推荐系统的三个亮点,一个是实时,一个是基于用户画像去做的,一个是异步化。
*** 实时主要体现在三个层面:***
-
用户画像中的的短期兴趣模型实时构建。
也就是你看完一个视频,这个视频几秒内就影响了你的短期兴趣模型,并且反应到你下次的推荐中。
-
候选集实时变更。
在我设计的推荐系统中,候选集的概念是不同类型的待推荐给用户的视频库,一个用户并不能看到某个候选集的全部,而是能够看到经过匹配算法处理完后的候选集的一部分。 候选集的更新周期直接影响用户能够看到的视频的实时性。候选集可以有很多,通过不同的候选集解决不同的推荐场景问题。比如结合最新候选集和最近N小时最热候选集,我们可以做到类似今日头条的推荐效果。新内容候选集的产生基本就是实时的,而最近N小时热门视频候选集则可能是分钟级别就可以得到更新。还有比如协同就可以做视频的相关推荐,而热门候选集则可以从大家都关心的内容里进一步筛出用户喜欢的内容。
-
推荐效果指标的实时呈现。
上线后你看到的一些比较关键的指标例如点击转化率,都可以在分钟级别得到更新。推荐系统有个比较特殊的地方,就是好不好不是某个人说了算,而是通过一些指标来衡量的。比如点击转化率。
*** 用户画像和视频画像 ***
用户画像则体现在兴趣模型上。通过构建用户的长期兴趣模型和短期兴趣模型可以很好的满足用户兴趣爱好以及在用户会话期间的需求。做推荐的方式可以很多,比如协同,比如各种小trick,而基于用户画像和视频画像,起步难度会较大,但是从长远角度可以促进团队对用户和视频的了解,并且能够支撑推荐以外的业务。
*** 异步化 ***
推荐的计算由用户刷新行为触发,然后将用户信息异步发送到Kafka,接着Spark Streaming程序会消费并且将候选集和用户进行匹配计算,计算结果会发送到Redis 的用户私有队列。接口服务只负责取推荐数据和发送用户刷新动作。新用户或者很久没有过来的用户,它的私有队列可能已经过期,这个时候异步会产生问题。前端接口一旦发现这个问题,有两种解决方案:
- 会发送一个特殊的消息(后端接的是Storm集群), 接着hold住,等待异步计算结果
- 自己获取用户兴趣标签,会按一定的规则分别找协同,然后到ES检索,填充私有队列,并迅速给出结果。(我们采用的方案)
除了新用户,这种情况总体是少数。大部分计算都会被异步计算cover住。
流式技术对推荐系统的影响
我之前写了很多文章鼓吹流式技术,最露骨的比如 数据天生就是流式的。 当然主要和我这一两年部门的工作主体是构建
流式流水线(Pipline),解决实时日志计费等相关问题。流式计算对推荐系统的影响很大,可以完全实现
在推荐系统中,除了接口服务外,其他所有计算相关的,包括但不限于:
- 新内容预处理,如标签化,存储到多个存储器
- 用户画像构建 如短期兴趣模型
- 新热数据候选集
- 短期协同
- 推荐效果评估指标如点击转化率
这些流程都是采用Spark Streaming来完成。对于长期协同(一天以上的数据),用户长期兴趣模型等,则是采用Spark 批处理。因为采用了StreamingPro这个项目,可以做到所有计算流程配置化,你看到的就是一堆的描述文件,这些描述文件构成了整个推荐系统的核心计算流程。
这里还值得提的三点是:
推荐效果评估,我们采用Spark Streaming + ElasticSearch的方案。也就是Spark Streaming 对上报的曝光点击数据进行预处理后存储到ES,然后ES提供查询接口供BI报表使用。这样避免预先计算指标导致很多指标实现没有考虑到而不断变更流式计算程序。
复用现有的大数据基础设施。整个推荐系统只有对外提供API的服务是需要单独部署的,其他所有计算都使用Spark跑在Hadoop集群上。
所有计算周期和计算资源都是可以方便调整的,甚至可以动态调整(Spark Dynamic Resource Allocatioin)。这点非常重要,我完全可以放弃一定的实时性来节省资源或者在闲暇时让出更多资源给离线任务。当然这些都益于Spark 的支持。
推荐系统的体系结构
整个推荐系统的结构如图:

看起来还是挺简单的。分布式流计算主要负责了五块:
- 点击曝光等上报数据处理
- 新视频标签化
- 短期兴趣模型计算
- 用户推荐
- 候选集计算,如最新,最热(任意时间段)
存储采用的有:
- Codis (用户推荐列表)
- HBase (用户画像和视频画像)
- Parquet(HDFS) (归档数据)
- ElasticSearch (HBase的副本)
下面这张图则是对流式计算那块的一个细化:

用户上报采用的技术方案:
- Nginx
- Flume (收集Nginx日志)
- Kafka (接收Flume的上报)
对于第三方内容(全网),我们自己开发了一个采集系统。
个性化推荐示
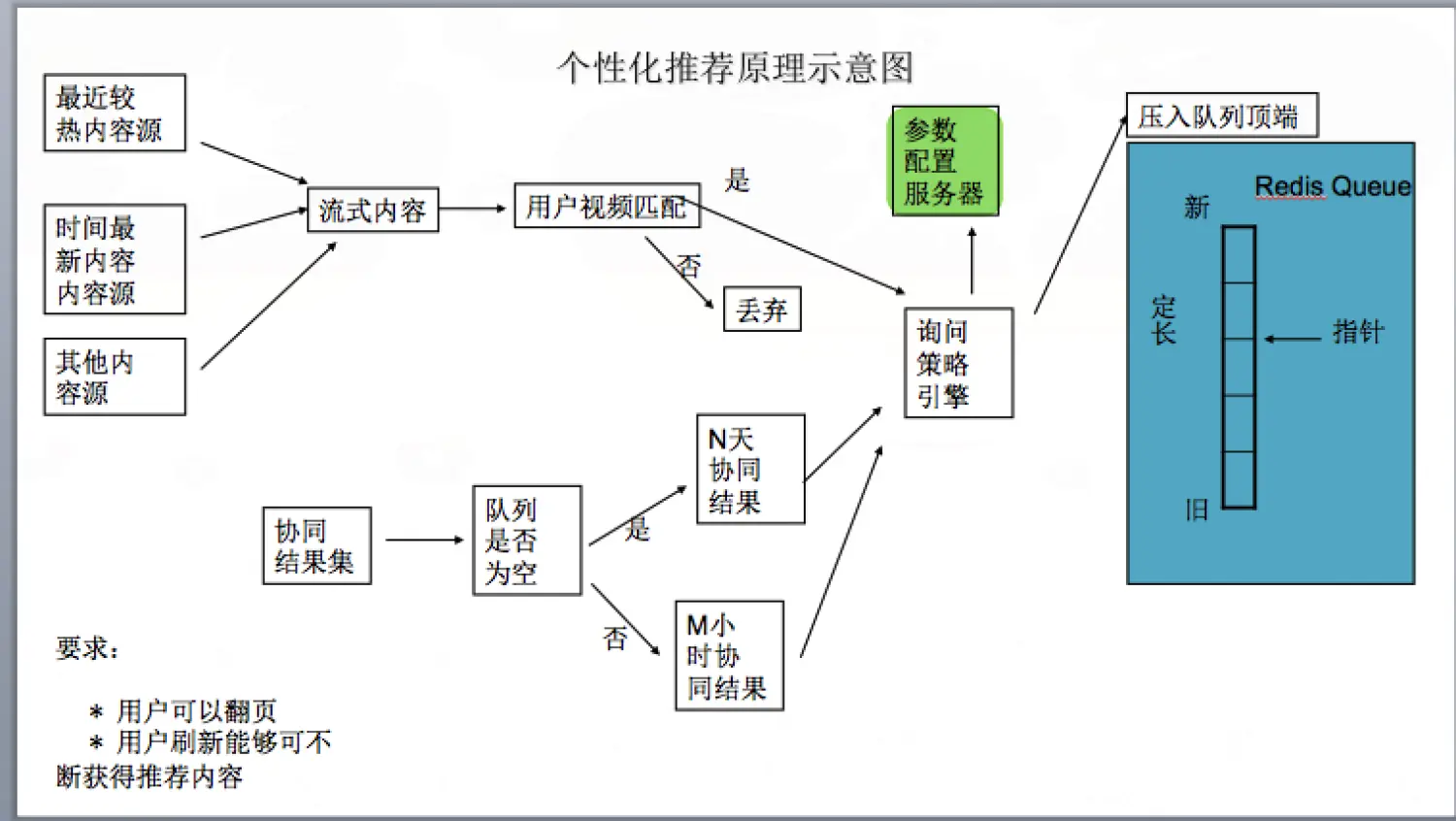
所有候选集都是实时更新的。
这里我们说下参数配置服务器的概念。
假设我有三个算法A,B,C ,他们分别由三个流式程序完成,各个程序是互相独立的,最后都会算出各自的结果集。因为不同候选集和算法算出的内容数据量和频度都会有差异,假设A算出的结果集过大,B算出的结果集很小,但是质量很好,这个时候他们在发送到用户推荐队列的时候,需要将自己的情况提交给参数配置服务器,并且由参数服务器决定最后能够发送到队列的量。参数服务器也可以控制对应频度。比如A算法距离上次推荐结果才10s就有新的要推荐了,参数服务器可以拒绝他的内容写入到用户推荐队列。
上面是一种多算法流程的控制。其实还有一种,就是我希望A,B的结果让一个新的算法K来决定混合的规则,因为所有算法都是StreamingPro中的一个可配置模块,这个时候A,B,K 会被放到一个Spark Streaming应用中。K可以周期性调用A,B进行计算,并且混合结果,最后通过参数服配置服务器的授权写入到用户推荐队列。
一些感悟
我14,15年做的一次推荐系统,那个时候还没有流式计算的理念,而且也不能复用一些已有的技术体系,导致系统过于复杂,产品化也会比较困难。而且推荐的效果也只能隔日看到,导致效果改良的周期非常长。当时整个开发周期超过了一个多月。然而现在基于StreamingPro,两三人没人么天只能投入两三小时,仅仅用了两个礼拜就开发出来了。后续就是对用户画像和视频画像的进一步深入探索,核心是构建出标签体系,然后将这些标签打到用户和视频身上。我们组合了LDA,贝叶斯等多种算法,获得不少有益的经验。

















 1284
1284


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








