



 本文介绍了Python线程的基础知识,包括如何创建线程、避免竞态条件、使用线程池等高级主题。通过丰富的示例代码,帮助读者掌握线程编程技巧。
本文介绍了Python线程的基础知识,包括如何创建线程、避免竞态条件、使用线程池等高级主题。通过丰富的示例代码,帮助读者掌握线程编程技巧。
Python 线程允许您同时运行程序的不同部分,并可以简化您的设计。如果您在 Python 方面有一定的经验并想使用线程来加速您的程序,那么本教程适合您!
在本文中,您将了解:
- 什么是线程
- 如何创建线程并等待它们完成
- 如何使用
ThreadPoolExecutor - 如何避免竞争条件
- 如何使用Python
threading提供的常用工具
本文假设您已经掌握了 Python 基础知识,并且您至少使用 3.6 版来运行示例。如果您需要复习,您可以从Python 学习路径开始并快速上手。
如果您不确定是否要使用 Python threading、asyncio、 或multiprocessing,那么您可以查看使用并发加速您的 Python 程序。
您可以在Real Python GitHub repo中获得本教程中使用的所有源代码。
什么是线程?
线程是一个单独的执行流。这意味着您的程序将同时发生两件事。但是对于大多数 Python 3 实现,不同的线程实际上不会同时执行:它们只是看起来。
人们很容易将线程视为在您的程序上运行两个(或多个)不同的处理器,每个处理器同时执行一项独立的任务。这几乎是正确的。线程可能运行在不同的处理器上,但它们一次只能运行一个。
让多个任务同时运行需要非标准的 Python 实现,用不同的语言编写一些代码,或者使用multiprocessing它会带来一些额外的开销。
由于 Python 的 CPython 实现的工作方式,线程可能不会加速所有任务。这是由于与GIL 的交互本质上限制了一次运行一个 Python 线程。
花费大量时间等待外部事件的任务通常是线程的良好候选者。需要大量 CPU 计算并且花费很少时间等待外部事件的问题可能根本无法运行得更快。
这适用于用 Python 编写并在标准 CPython 实现上运行的代码。如果您的线程是用 C 编写的,则它们能够释放 GIL 并同时运行。如果您在不同的 Python 实现上运行,请查看文档,了解它如何处理线程。
如果你正在运行一个标准的 Python 实现,只用 Python 编写,并且有一个 CPU 密集型的问题,你应该检查这个multiprocessing模块。
构建您的程序以使用线程还可以提高设计清晰度。您将在本教程中学习的大多数示例不一定会运行得更快,因为它们使用线程。在其中使用线程有助于使设计更简洁、更易于推理。
所以,让我们停止谈论线程并开始使用它!
开始一个线程
现在您已经了解了线程是什么,让我们学习如何制作线程。Python 标准库提供了threading,其中包含您将在本文中看到的大部分原语。Thread,在这个模块中,很好地封装了线程,提供了一个干净的接口来处理它们。
要启动一个单独的线程,您需要创建一个Thread实例,然后告诉它.start():
import logging
import threading
import time
def thread_function(name):
logging.info("Thread %s: starting", name)
time.sleep(2)
logging.info("Thread %s: finishing", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
logging.info("Main : before creating thread")
x = threading.Thread(target=thread_function, args=(1,))
logging.info("Main : before running thread")
x.start()
logging.info("Main : wait for the thread to finish")
# x.join()
logging.info("Main : all done")
如果您查看日志记录语句,您可以看到该main部分正在创建和启动线程:
x = threading.Thread(target=thread_function, args=(1,))
x.start()
创建 时Thread,您将一个函数和一个包含该函数参数的列表传递给它。在这种情况下,您告诉Thread运行thread_function()并将其1作为参数传递。
对于本文,您将使用顺序整数作为线程的名称。有threading.get_ident(),它为每个线程返回一个唯一的名称,但这些通常既不简短也不易于阅读。
thread_function()本身并没有多大作用。它只是记录一些消息,time.sleep()中间有一个。
当您按原样运行此程序时(注释掉第 20 行),输出将如下所示:
$ ./single_thread.py
Main : before creating thread
Main : before running thread
Thread 1: starting
Main : wait for the thread to finish
Main : all done
Thread 1: finishing
您会注意到Thread在Main您的代码部分完成之后完成了。您将回到为什么会这样,并在下一节中讨论神秘的第 20 行。
守护线程
在计算机科学中,adaemon是一个在后台运行的进程。
Pythonthreading对daemon. 一个daemon线程将关闭程序退出时立即。考虑这些定义的一种方法是将daemon线程视为在后台运行而不必担心将其关闭的线程。
如果正在运行的程序Threads不是daemons,则该程序将在终止之前等待这些线程完成。Threads这是守护进程,然而,刚刚杀了,无论他们是在程序退出时。
让我们更仔细地看一下上面程序的输出。最后两行是有趣的部分。当您运行该程序时,您会注意到在__main__打印其all done消息之后和线程完成之前有一个暂停(大约 2 秒)。
这个暂停是 Python 等待非守护线程完成。当您的 Python 程序结束时,关闭过程的一部分是清理线程例程。
如果您查看Pythonthreading的源代码,您会看到它threading._shutdown()遍历所有正在运行的线程并调用.join()每个没有daemon设置标志的线程。
所以你的程序等待退出,因为线程本身正在等待睡眠。一旦完成并打印消息,.join()将返回并且程序可以退出。
通常,这种行为正是您想要的,但我们还有其他选择。我们先用一个daemon线程重复这个程序。您可以通过更改构造方式来实现Thread,添加daemon=True标志:
x = threading.Thread(target=thread_function, args=(1,), daemon=True)
现在运行程序时,应该会看到以下输出:
$ ./daemon_thread.py
Main : before creating thread
Main : before running thread
Thread 1: starting
Main : wait for the thread to finish
Main : all done
这里的区别在于缺少输出的最后一行。thread_function()没有机会完成。它是一个daemon线程,因此当__main__到达其代码的末尾并且程序想要完成时,守护进程被杀死。
join() 一个线程
守护线程很方便,但是当您想等待线程停止时怎么办?当你想这样做而不退出你的程序时呢?现在让我们回到你原来的程序,看看注释掉的第 20 行:
# x.join()
要告诉一个线程等待另一个线程完成,请调用.join(). 如果取消注释该行,主线程将暂停并等待线程x完成运行。
您是否使用守护线程或常规线程在代码上对此进行了测试?事实证明这并不重要。如果您.join()是一个线程,则该语句将等待任何一种线程完成。
使用多个线程
到目前为止,示例代码只使用了两个线程:主线程和您从threading.Thread对象开始的线程。
通常,您需要启动多个线程并让它们完成有趣的工作。让我们从更难的方法开始,然后您将转向更简单的方法。
启动多个线程的更难的方法是您已经知道的方法:
import logging
import threading
import time
def thread_function(name):
logging.info("Thread %s: starting", name)
time.sleep(2)
logging.info("Thread %s: finishing", name)
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
threads = list()
for index in range(3):
logging.info("Main : create and start thread %d.", index)
x = threading.Thread(target=thread_function, args=(index,))
threads.append(x)
x.start()
for index, thread in enumerate(threads):
logging.info("Main : before joining thread %d.", index)
thread.join()
logging.info("Main : thread %d done", index)
此代码使用您在上面看到的相同机制来启动线程、创建Thread对象,然后调用.start(). 该程序保留一个Thread对象列表,以便以后可以使用.join().
多次运行此代码可能会产生一些有趣的结果。这是我机器的输出示例:
$ ./multiple_threads.py
Main : create and start thread 0.
Thread 0: starting
Main : create and start thread 1.
Thread 1: starting
Main : create and start thread 2.
Thread 2: starting
Main : before joining thread 0.
Thread 2: finishing
Thread 1: finishing
Thread 0: finishing
Main : thread 0 done
Main : before joining thread 1.
Main : thread 1 done
Main : before joining thread 2.
Main : thread 2 done
如果您仔细查看输出,您会看到所有三个线程都按照您预期的顺序启动,但在这种情况下,它们以相反的顺序完成!多次运行将产生不同的排序。寻找Thread x: finishing告诉您每个线程何时完成的消息。
线程运行的顺序由操作系统决定,并且很难预测。它可能(并且可能会)因运行而异,因此在设计使用线程的算法时需要注意这一点。
幸运的是,Python 为您提供了几个原语,稍后您将查看它们以帮助协调线程并使它们一起运行。在此之前,让我们看看如何更轻松地管理一组线程。
用一个 ThreadPoolExecutor
有一种比上面看到的更简单的方法来启动一组线程。它被称为 a ThreadPoolExecutor,它是concurrent.futures(从 Python 3.2 开始)标准库的一部分。
创建它的最简单方法是作为上下文管理器,使用with语句来管理池的创建和销毁。
这是__main__上一个示例中重写为使用 a 的示例ThreadPoolExecutor:
import concurrent.futures
# [rest of code]
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
executor.map(thread_function, range(3))
代码创建一个ThreadPoolExecutor作为上下文管理器,告诉它在池中需要多少工作线程。然后它.map()用于单步执行可迭代的事物,在您的情况下range(3),将每个事物传递给池中的一个线程。
with块的结尾导致对池中的每个线程ThreadPoolExecutor执行 a .join()。这是强烈建议您使用ThreadPoolExecutor的上下文管理器时,你可以让你永远不会忘记.join()的线程。
注意:使用 aThreadPoolExecutor可能会导致一些令人困惑的错误。
例如,如果您调用一个不带参数的函数,但您将参数传递给它.map(),线程将抛出异常。
不幸的是,ThreadPoolExecutor将隐藏该异常,并且(在上述情况下)程序终止而没有输出。一开始调试可能会非常混乱。
运行您更正的示例代码将产生如下所示的输出:
$ ./executor.py
Thread 0: starting
Thread 1: starting
Thread 2: starting
Thread 1: finishing
Thread 0: finishing
Thread 2: finishing
再次注意Thread 1之前的完成情况Thread 0。线程的调度是由操作系统完成的,并不遵循易于理解的计划。
竞争条件
在继续讨论 Python 中隐藏的其他一些特性之前threading,让我们先谈谈在编写线程程序时会遇到的一个更困难的问题:竞争条件。
一旦您了解了竞态条件是什么并看到了一种情况的发生,您将继续了解标准库提供的一些原语以防止竞态条件的发生。
当两个或多个线程访问共享的数据或资源时,可能会发生竞争条件。在此示例中,您将创建一个每次都会发生的大型竞争条件,但请注意,大多数竞争条件并非如此明显。通常,它们很少发生,并且会产生令人困惑的结果。可以想象,这使得它们很难调试。
幸运的是,这种竞争条件每次都会发生,您将详细浏览它以解释正在发生的事情。
对于此示例,您将编写一个更新数据库的类。好的,您不会真正拥有数据库:您只是伪造它,因为这不是本文的重点。
你的FakeDatabase意志.__init__()和.update()方法:
class FakeDatabase:
def __init__(self):
self.value = 0
def update(self, name):
logging.info("Thread %s: starting update", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.info("Thread %s: finishing update", name)
FakeDatabase正在跟踪一个数字:.value。这将是您将看到竞争条件的共享数据。
.__init__()简单地初始化.value为零。到现在为止还挺好。
.update()看起来有点奇怪。它模拟从数据库中读取一个值,对其进行一些计算,然后将一个新值写回数据库。
在这种情况下,从数据库读取仅意味着复制.value到局部变量。计算只是将值加一,然后加.sleep()一点。最后,它通过将本地值复制回 来写回值.value。
以下是您将如何使用它FakeDatabase:
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
database = FakeDatabase()
logging.info("Testing update. Starting value is %d.", database.value)
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.update, index)
logging.info("Testing update. Ending value is %d.", database.value)
该程序创建了一个ThreadPoolExecutor有两个线程的线程,然后调用.submit()它们中的每一个,告诉它们运行database.update().
.submit() 有一个签名,允许将位置和命名参数传递给在线程中运行的函数:
.submit(function, *args, **kwargs)
在上面的用法中,index作为第一个也是唯一一个位置参数传递给database.update(). 您将在本文后面看到,您可以以类似的方式传递多个参数。
因为每个线程运行.update(),并.update()增加了一个.value,你可能期望database.value是2当它打印出来在最后。但如果是这样,你就不会看这个例子。如果运行上面的代码,输出如下所示:
$ ./racecond.py
Testing unlocked update. Starting value is 0.
Thread 0: starting update
Thread 1: starting update
Thread 0: finishing update
Thread 1: finishing update
Testing unlocked update. Ending value is 1.
您可能已经预料到会发生这种情况,但让我们看看这里真正发生的事情的详细信息,因为这将使该问题的解决方案更容易理解。
一根线
在使用两个线程深入研究这个问题之前,让我们退后一步,谈谈线程如何工作的一些细节。
您不会在这里深入研究所有细节,因为这在这个级别并不重要。我们还将以技术上不准确但会让您正确了解正在发生的事情的方式简化一些事情。
当你告诉你的ThreadPoolExecutor运行每个线程,你告诉它要运行的功能,哪些参数传递给它:executor.submit(database.update, index)。
这样做的结果是池中的每个线程都会调用database.update(index). 请注意,这database是对中FakeDatabase创建的一个对象的引用__main__。调用.update()该对象会调用该对象上的实例方法。
每个线程都将引用同一个FakeDatabase对象database. 每个线程也将有一个唯一值 ,index以使日志语句更易于阅读:
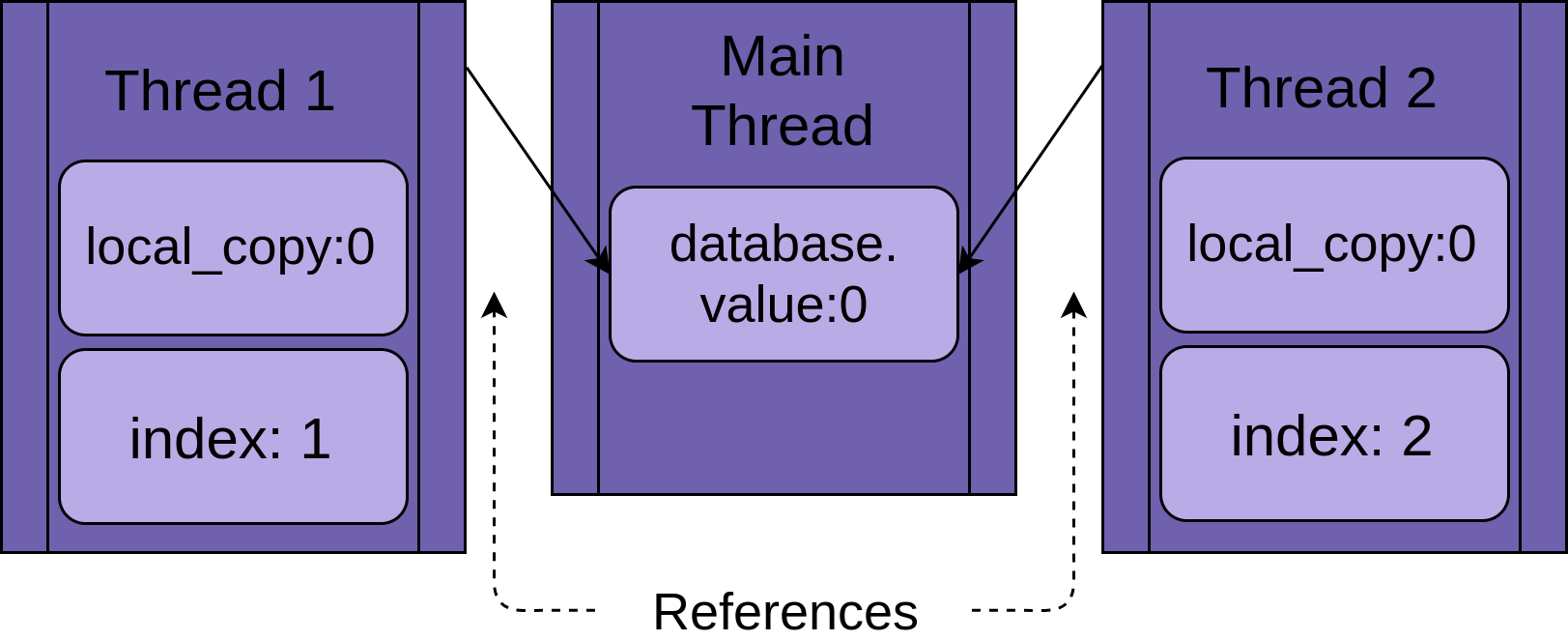
当线程开始运行时.update(),它拥有函数本地所有数据的自己版本。在 的情况下.update(),这是local_copy。这绝对是一件好事。否则,运行相同功能的两个线程总是会相互混淆。这意味着作用域(或局部)到函数的所有变量都是线程安全的。
现在,您可以开始了解如果使用单个线程和单个调用运行上面的程序会发生什么.update()。
下图逐步执行.update()如果只运行一个线程。该语句显示在左侧,后面是一个图表,显示了线程local_copy和共享中的值database.value:
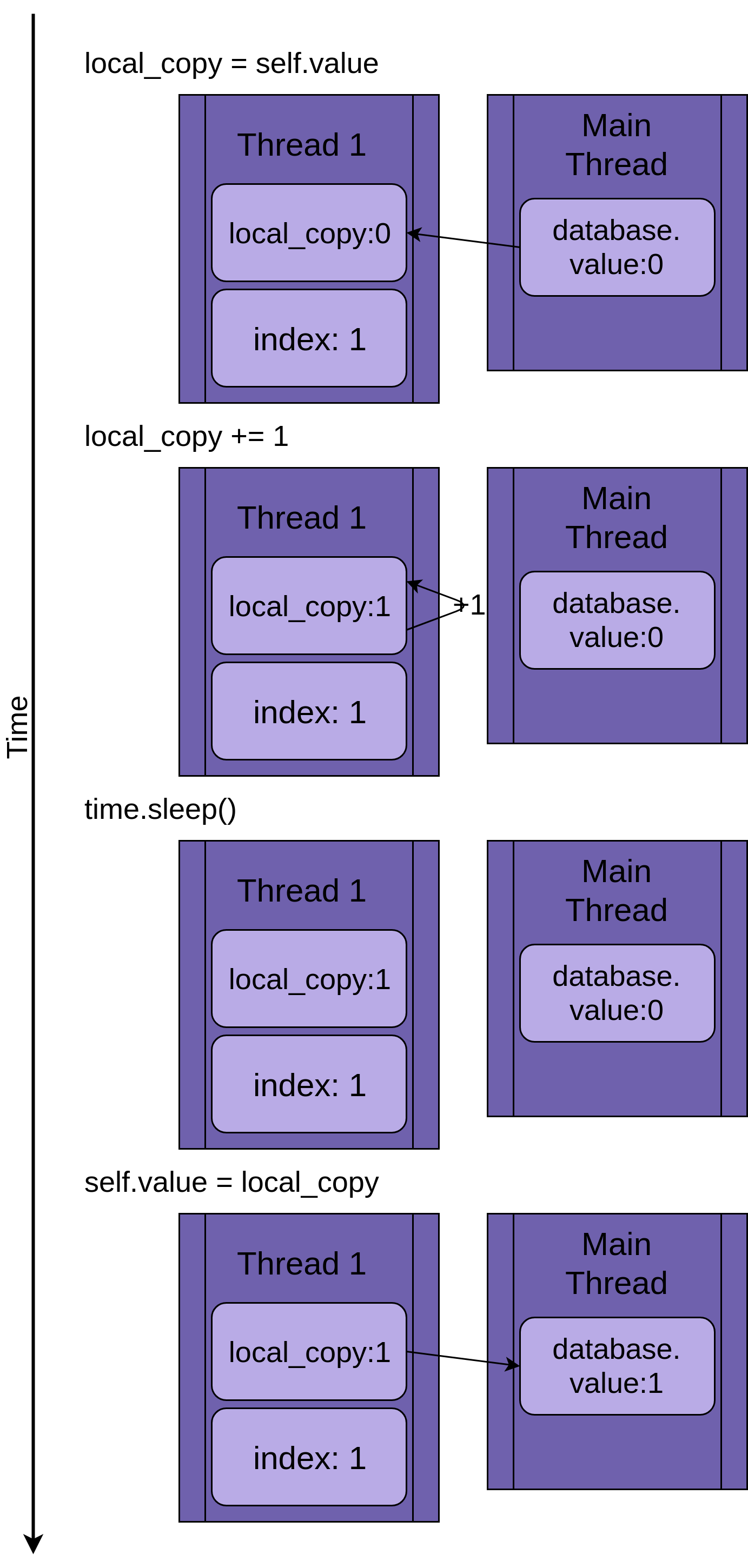
图表的布局使得时间随着您从上到下移动而增加。它在Thread 1创建时开始,在终止时结束。
当Thread 1启动时,FakeDatabase.value是零。方法中的第一行代码local_copy = self.value将值零复制到局部变量。接下来它增加了local_copywithlocal_copy += 1语句的值。你可以看到.value在Thread 1越来越被设置为1。
Nexttime.sleep()被调用,它使当前线程暂停并允许其他线程运行。由于本示例中只有一个线程,因此这不起作用。
当Thread 1唤醒并继续时,它从local_copyto复制新值FakeDatabase.value,然后线程完成。你可以看到database.value设置为1。
到现在为止还挺好。你跑了.update()一次,FakeDatabase.value然后增加到一。
两个线程
回到竞争条件,两个线程将同时运行,但不会同时运行。他们每个人都有自己的版本,local_copy并且每个人都指向相同的database. 正是这个共享database对象将导致问题。
该程序从Thread 1运行开始.update():
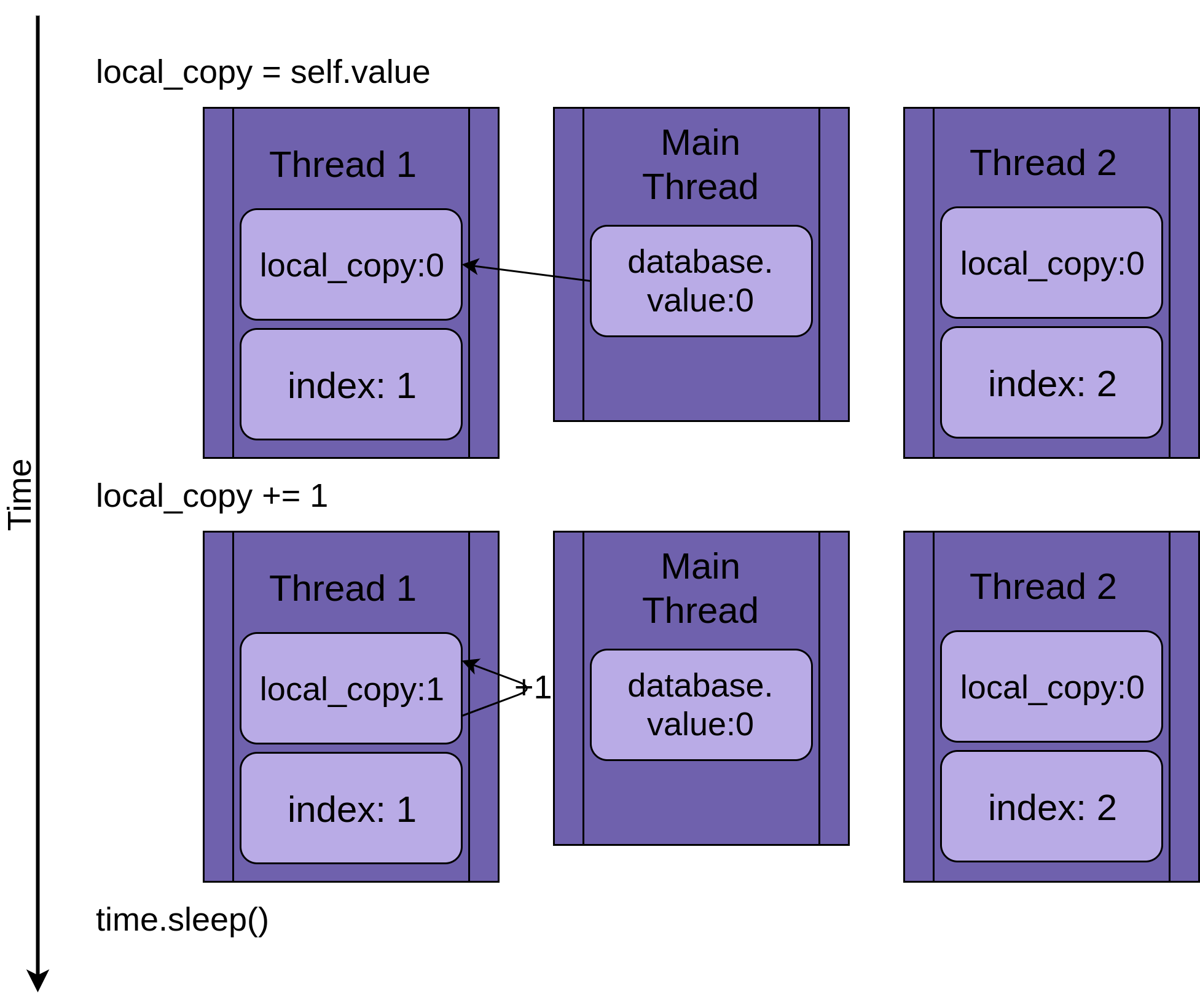
当Thread 1调用 时time.sleep(),它允许另一个线程开始运行。这就是事情变得有趣的地方。
Thread 2启动并执行相同的操作。它也在复制database.value到它的 private 中local_copy,这个共享database.value还没有更新:
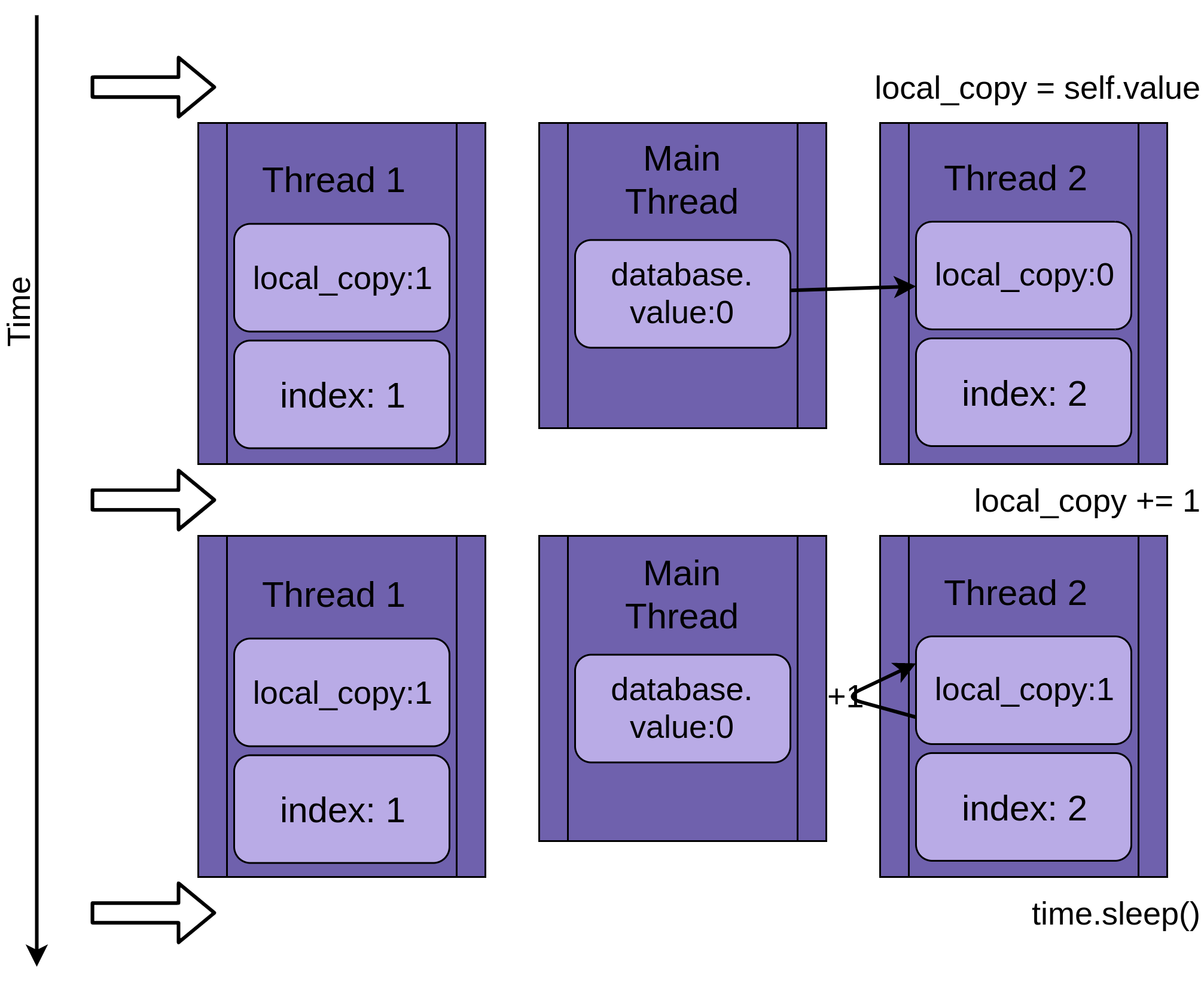
当Thread 2最终进入睡眠状态时,shareddatabase.value仍然未修改为零,并且两个私有版本local_copy的值都为 1。
Thread 1现在唤醒并保存其版本,local_copy然后终止,提供Thread 2最后的运行机会。Thread 2不知道它在睡觉时Thread 1运行和更新database.value。它将其版本存储为local_copyinto database.value,并将其设置为 1:
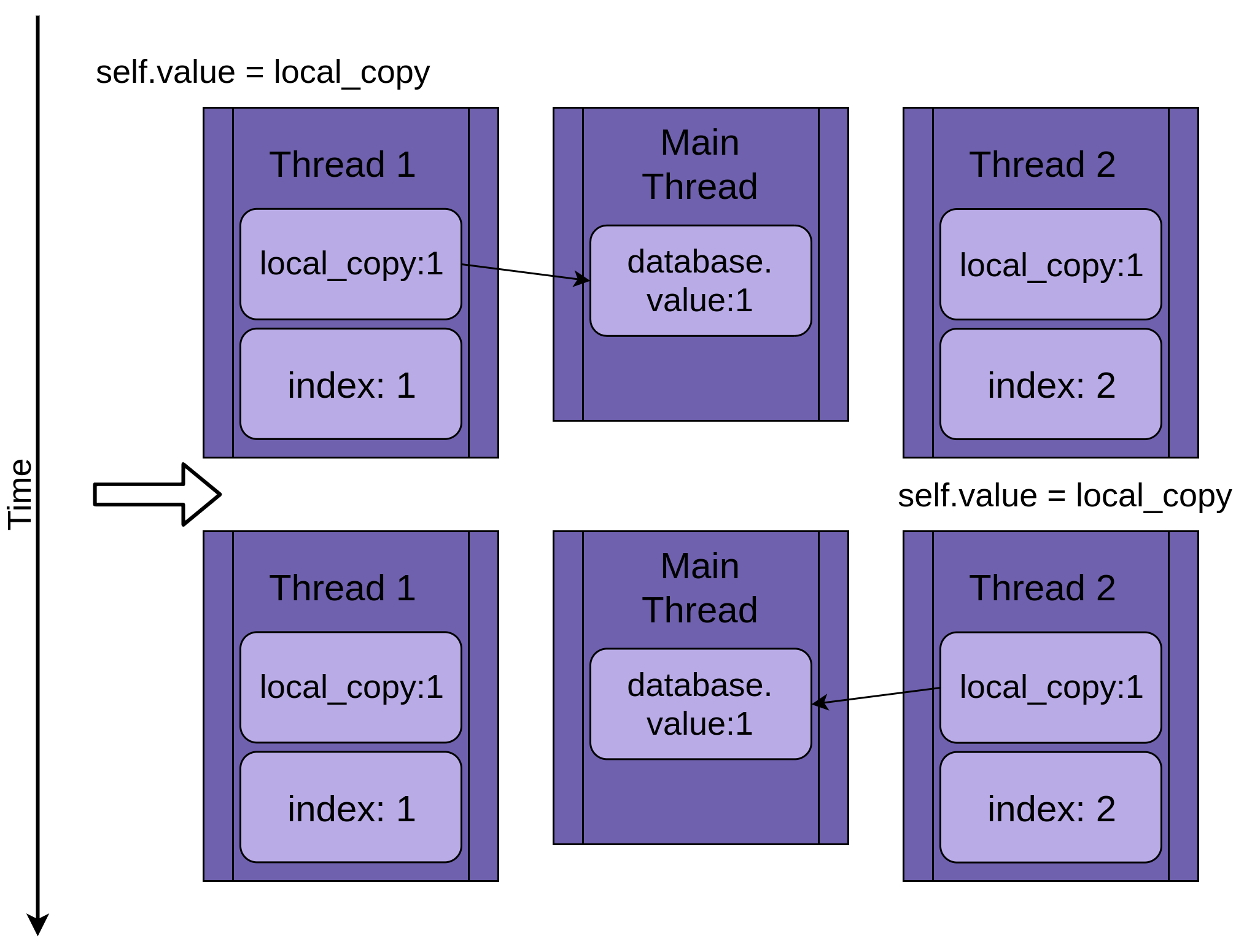
两个线程交错访问单个共享对象,覆盖彼此的结果。当一个线程在另一个线程完成访问之前释放内存或关闭文件句柄时,可能会出现类似的竞争条件。
为什么这不是一个愚蠢的例子
上面的示例旨在确保每次运行程序时都会发生竞争条件。因为操作系统可以随时换出一个线程,所以有可能x = x + 1在它读取了 的值之后x但在写回增加的值之前中断语句。
这是如何发生的细节非常有趣,但本文的其余部分不需要,所以请随意跳过这个隐藏的部分。
这是如何真正起作用的显示隐藏
既然您已经看到了实际的竞争条件,让我们找出如何解决它们!
基本同步使用 Lock
有多种方法可以避免或解决竞争条件。您不会在这里查看所有这些,但有一些经常使用。让我们从Lock.
要解决上述竞争条件,您需要找到一种方法,一次只允许一个线程进入代码的读取-修改-写入部分。最常见的方法是Lock在 Python 中调用。在其他一些语言中,同样的想法被称为 a mutex。Mutex 来自 MUTual EXclusion,这正是 a 的Lock作用。
ALock是一个对象,其作用类似于大厅通行证。一次只有一个线程可以拥有Lock. 任何其他想要 的线程Lock必须等到 所有者Lock放弃它。
执行此操作的基本功能是.acquire()和.release()。一个线程将调用my_lock.acquire()以获取锁。如果锁已经被持有,调用线程将等待直到它被释放。这里有一个重要的点。如果一个线程获得了锁但从未返回,您的程序将被卡住。稍后您将阅读更多相关信息。
幸运的是,PythonLock也将作为上下文管理器运行,因此您可以在with语句中使用它,并且当with块因任何原因退出时它会自动释放。
让我们看看添加FakeDatabase了一个Lock。调用函数保持不变:
class FakeDatabase:
def __init__(self):
self.value = 0
self._lock = threading.Lock()
def locked_update(self, name):
logging.info("Thread %s: starting update", name)
logging.debug("Thread %s about to lock", name)
with self._lock:
logging.debug("Thread %s has lock", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.debug("Thread %s about to release lock", name)
logging.debug("Thread %s after release", name)
logging.info("Thread %s: finishing update", name)
除了添加一堆调试日志以便您可以更清楚地看到锁定之外,这里的重大变化是添加了一个名为 的成员._lock,它是一个threading.Lock()对象。这._lock在未锁定状态下初始化并由with语句锁定和释放。
这里值得注意的是,运行此函数的线程将保持该Lock状态,直到它完全完成更新数据库。在这种情况下,这意味着它将保留Lock它复制、更新、休眠的时间,然后将值写回数据库。
如果您在日志记录设置为警告级别的情况下运行此版本,您将看到:
$ ./fixrace.py
Testing locked update. Starting value is 0.
Thread 0: starting update
Thread 1: starting update
Thread 0: finishing update
Thread 1: finishing update
Testing locked update. Ending value is 2.
看那个。你的程序终于可以运行了!
您可以DEBUG通过在配置日志输出后添加此语句将级别设置为来打开完整日志记录__main__:
logging.getLogger().setLevel(logging.DEBUG)
在DEBUG打开日志记录的情况下运行这个程序看起来像这样:
$ ./fixrace.py
Testing locked update. Starting value is 0.
Thread 0: starting update
Thread 0 about to lock
Thread 0 has lock
Thread 1: starting update
Thread 1 about to lock
Thread 0 about to release lock
Thread 0 after release
Thread 0: finishing update
Thread 1 has lock
Thread 1 about to release lock
Thread 1 after release
Thread 1: finishing update
Testing locked update. Ending value is 2.
在此输出中,您可以看到Thread 0获取锁并且在它进入睡眠状态时仍然持有它。Thread 1然后开始并尝试获取相同的锁。因为Thread 0还在捧着,还得Thread 1等。这就是aLock提供的互斥。
许多在本文的其余部分的例子将WARNING和DEBUG级记录。我们通常只显示WARNING级别输出,因为DEBUG日志可能很长。尝试打开日志记录的程序,看看它们做了什么。
僵局
在继续之前,您应该查看使用Locks. 如您所见,如果Lock已经被获取,则第二次调用.acquire()将等到持有Lock调用的线程.release()。当您运行此代码时,您认为会发生什么:
import threading
l = threading.Lock()
print("before first acquire")
l.acquire()
print("before second acquire")
l.acquire()
print("acquired lock twice")
当程序l.acquire()第二次调用时,它挂起等待Lock释放。在此示例中,您可以通过删除第二个调用来修复死锁,但死锁通常由以下两个微妙的事情之一发生:
- a
Lock未正确释放的实现错误 - 一个设计问题,其中一个实用函数需要被可能已经或可能没有的函数调用
Lock
第一种情况有时会发生,但使用 aLock作为上下文管理器会大大减少发生的频率。建议尽可能编写代码以使用上下文管理器,因为它们有助于避免异常跳过.release()调用的情况。
在某些语言中,设计问题可能有点棘手。幸运的是,Python 线程有第二个对象,称为RLock,专为这种情况而设计。它允许一个线程.acquire()的RLock多次调用之前.release()。该线程仍然需要调用.release()它调用的相同次数.acquire(),但无论如何它都应该这样做。
Lock和RLock是线程编程中用来防止竞争条件的两个基本工具。还有其他一些以不同的方式工作。在查看它们之前,让我们转向一个稍微不同的问题域。
生产者-消费者线程
在生产者-消费者问题是用来看看线程或进程同步的问题一个标准的计算机科学问题。您将查看它的一个变体,以了解 Pythonthreading模块提供的原语。
对于本示例,您将设想一个程序需要从网络读取消息并将它们写入磁盘。该程序不会在需要时请求消息。它必须在消息传入时倾听并接受它们。消息不会以固定的速度传入,而是会以突发的方式传入。程序的这部分称为生产者。
另一方面,一旦有了消息,就需要将其写入数据库。数据库访问速度较慢,但速度足以跟上消息的平均速度。这是不是速度不够快,跟不上消息时一阵进来,这部分消费者。
在生产者和消费者之间,您将创建一个Pipeline随着您了解不同的同步对象而改变的部分。
这就是基本的布局。让我们看一下使用Lock. 它不能完美地工作,但它使用您已经知道的工具,所以这是一个很好的起点。
生产者-消费者使用 Lock
由于这是一篇关于 Python 的文章threading,而且由于您刚刚阅读了Lock原语,让我们尝试使用一两个线程来解决这个问题Lock。
一般的设计是有一个producer线程从假网络中读取并将消息放入一个Pipeline:
import random
SENTINEL = object()
def producer(pipeline):
"""Pretend we're getting a message from the network."""
for index in range(10):
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
pipeline.set_message(message, "Producer")
# Send a sentinel message to tell consumer we're done
pipeline.set_message(SENTINEL, "Producer")
要生成假消息,需要producer获取一个介于 1 和 100 之间的随机数。它要求.set_message()将pipeline其发送到consumer。
该producer还采用了SENTINEL价值给消费者信号,停止它已派出10个值之前。这有点尴尬,但别担心,SENTINEL在您完成此示例后,您将看到摆脱此值的方法。
另一边pipeline是消费者:
def consumer(pipeline):
"""Pretend we're saving a number in the database."""
message = 0
while message is not SENTINEL:
message = pipeline.get_message("Consumer")
if message is not SENTINEL:
logging.info("Consumer storing message: %s", message)
从consumer读取消息pipeline并将其写入假数据库,在这种情况下只是将其打印到显示器。如果它得到SENTINEL值,它从函数返回,这将终止线程。
在你看真正有趣的部分之前Pipeline,这里是__main__产生这些线程的部分:
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
# logging.getLogger().setLevel(logging.DEBUG)
pipeline = Pipeline()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline)
executor.submit(consumer, pipeline)
这应该看起来很熟悉,因为它__main__与前面示例中的代码很接近。
请记住,您可以DEBUG通过取消注释此行来打开日志记录以查看所有日志记录消息:
# logging.getLogger().setLevel(logging.DEBUG)
遍历DEBUG日志消息以准确查看每个线程获取和释放锁的位置是值得的。
现在让我们看看Pipeline将消息从 传递producer到 的consumer:
class Pipeline:
"""
Class to allow a single element pipeline between producer and consumer.
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
logging.debug("%s:about to acquire getlock", name)
self.consumer_lock.acquire()
logging.debug("%s:have getlock", name)
message = self.message
logging.debug("%s:about to release setlock", name)
self.producer_lock.release()
logging.debug("%s:setlock released", name)
return message
def set_message(self, message, name):
logging.debug("%s:about to acquire setlock", name)
self.producer_lock.acquire()
logging.debug("%s:have setlock", name)
self.message = message
logging.debug("%s:about to release getlock", name)
self.consumer_lock.release()
logging.debug("%s:getlock released", name)
哇!这是很多代码。其中很大一部分只是记录语句,以便在运行时更容易查看发生了什么。这是删除了所有日志语句的相同代码:
class Pipeline:
"""
Class to allow a single element pipeline between producer and consumer.
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
self.consumer_lock.acquire()
message = self.message
self.producer_lock.release()
return message
def set_message(self, message, name):
self.producer_lock.acquire()
self.message = message
self.consumer_lock.release()
这似乎更易于管理。在Pipeline这个版本的代码有三个成员:
.message存储要传递的消息。.producer_lock是threading.Lock限制producer线程访问消息的对象。.consumer_lock也是threading.Lock限制consumer线程访问消息的一个。
__init__()初始化这三个成员,然后调用.acquire()上.consumer_lock。这是您想要开始的状态。producer允许添加新消息,但consumer需要等到消息出现。
.get_message()并且.set_messages()几乎是相反的。.get_message()调用.acquire()的consumer_lock。这是将consumer等待消息准备好的调用。
一旦consumer收购了.consumer_lock,它复制出来的值.message,然后调用.release()上.producer_lock。释放此锁允许producer将下一条消息插入到pipeline.
在你继续之前.set_message(),有一些.get_message()很容易错过的微妙之处。摆脱message并让函数以return self.message. 在继续之前,看看你是否能弄清楚为什么你不想这样做。
这是答案。只要consumer调用.producer_lock.release(),它就可以换出,并且producer可以开始运行。这可能会在.release()返回之前发生!这意味着当函数返回时self.message,这可能是生成的下一条消息的可能性很小,因此您将丢失第一条消息。这是竞争条件的另一个例子。
转到.set_message(),您可以看到交易的另一面。在producer将一个消息调用它。它将获取.producer_lock、设置.message和调用.release()then consumer_lock,这将允许consumer读取该值。
让我们运行将日志设置为的代码,WARNING看看它是什么样的:
$ ./prodcom_lock.py
Producer got data 43
Producer got data 45
Consumer storing data: 43
Producer got data 86
Consumer storing data: 45
Producer got data 40
Consumer storing data: 86
Producer got data 62
Consumer storing data: 40
Producer got data 15
Consumer storing data: 62
Producer got data 16
Consumer storing data: 15
Producer got data 61
Consumer storing data: 16
Producer got data 73
Consumer storing data: 61
Producer got data 22
Consumer storing data: 73
Consumer storing data: 22
起初,您可能会觉得奇怪的是,生产者甚至在消费者运行之前就收到了两条消息。如果你回头看看producerand .set_message(),你会注意到它等待 a 的唯一地方Lock是它试图将消息放入管道时。这是在producer获取消息并记录它有消息后完成的。
当producer尝试发送第二条消息时,它将.set_message()第二次调用并阻塞。
操作系统可以随时交换线程,但它通常让每个线程在交换之前有合理的运行时间。这就是为什么producer通常运行直到它在第二次调用.set_message().
然而,一旦线程被阻塞,操作系统将始终将其换出并找到一个不同的线程来运行。在这种情况下,唯一可以做任何事情的其他线程是consumer.
该consumer电话.get_message(),其内容的消息,并呼吁.release()对.producer_lock,从而使producer再下一次线程运行的交换。
请注意,第一条消息是43,这正是consumer读取的内容,即使producer已经生成了45消息。
虽然它适用于这个有限的测试,但它通常不是生产者-消费者问题的一个很好的解决方案,因为它一次只允许管道中的一个值。当producer收到大量消息时,它将无处可放。
让我们继续使用一个更好的方法来解决这个问题,使用Queue.
生产者-消费者使用 Queue
如果您希望能够一次处理管道中的多个值,您将需要一种管道数据结构,该结构允许随着数据从producer.
Python 的标准库有一个queue模块,而该模块又具有一个Queue类。让我们将 更改Pipeline为使用 aQueue而不仅仅是受 a 保护的变量Lock。您还将通过使用与 Python 不同的原语threading,即Event.
让我们从Event. 该threading.Event对象允许一个线程发出信号,event而许多其他线程可以等待它event发生。这段代码中的关键用法是等待事件的线程不一定需要停止他们正在做的事情,他们可以Event每隔一段时间检查一次事件的状态。
事件的触发可以是很多事情。在这个例子中,主线程将简单地休眠一段时间然后.set()它:
1if __name__ == "__main__":
2 format = "%(asctime)s: %(message)s"
3 logging.basicConfig(format=format, level=logging.INFO,
4 datefmt="%H:%M:%S")
5 # logging.getLogger().setLevel(logging.DEBUG)
6
7 pipeline = Pipeline()
8 event = threading.Event()
9 with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
10 executor.submit(producer, pipeline, event)
11 executor.submit(consumer, pipeline, event)
12
13 time.sleep(0.1)
14 logging.info("Main: about to set event")
15 event.set()
唯一的改变这里的创建event第6行对象,传递event作为线8,9的参数,并且在线路11至13的最后一节,其睡眠用于第二,日志消息,然后调用.set()对事件。
在producer还没有改变太多:
1def producer(pipeline, event):
2 """Pretend we're getting a number from the network."""
3 while not event.is_set():
4 message = random.randint(1, 101)
5 logging.info("Producer got message: %s", message)
6 pipeline.set_message(message, "Producer")
7
8 logging.info("Producer received EXIT event. Exiting")
它现在将循环直到它看到在第 3 行设置了事件。它也不再将SENTINEL值放入pipeline.
consumer 不得不改变一点:
1def consumer(pipeline, event):
2 """Pretend we're saving a number in the database."""
3 while not event.is_set() or not pipeline.empty():
4 message = pipeline.get_message("Consumer")
5 logging.info(
6 "Consumer storing message: %s (queue size=%s)",
7 message,
8 pipeline.qsize(),
9 )
10
11 logging.info("Consumer received EXIT event. Exiting")
虽然您必须取出与SENTINEL值相关的代码,但您确实需要做一个稍微复杂一些的while条件。它不仅循环直到event设置,而且还需要继续循环直到pipeline清空。
在消费者完成之前确保队列为空可以防止另一个有趣的问题。如果consumer确实退出而其中pipeline有消息,则可能会发生两件坏事。第一个是您丢失了那些最终消息,但更严重的是,producer尝试将消息添加到完整队列时可能会被抓住并且永远不会返回。
如果在检查条件之后但在调用之前event被触发,就会发生这种情况。producer.is_set()pipeline.set_message()
如果发生这种情况,生产者可能会在队列仍然完全满的情况下醒来并退出。然后producer将调用.set_message()它将等待,直到队列中有新消息的空间。在consumer已经退出,所以这不会发生和producer将不会退出。
其余的consumer应该看起来很熟悉。
该Pipeline然而,发生了巨大变化,:
1class Pipeline(queue.Queue):
2 def __init__(self):
3 super().__init__(maxsize=10)
4
5 def get_message(self, name):
6 logging.debug("%s:about to get from queue", name)
7 value = self.get()
8 logging.debug("%s:got %d from queue", name, value)
9 return value
10
11 def set_message(self, value, name):
12 logging.debug("%s:about to add %d to queue", name, value)
13 self.put(value)
14 logging.debug("%s:added %d to queue", name, value)
你可以看到它Pipeline是queue.Queue. Queue初始化时有一个可选参数来指定队列的最大大小。
如果你给 一个正数maxsize,它会将队列限制为该数量的元素,导致.put()阻塞,直到少于maxsize元素。如果不指定maxsize,则队列将增长到计算机内存的限制。
.get_message()并且.set_message()变得更小了。它们基本上环绕.get()并.put()在Queue. 您可能想知道防止线程导致竞争条件的所有锁定代码都去哪儿了。
编写标准库的核心开发人员知道 aQueue在多线程环境中经常使用,并将所有锁定代码合并到其Queue自身中。Queue是线程安全的。
运行该程序如下所示:
$ ./prodcom_queue.py
Producer got message: 32
Producer got message: 51
Producer got message: 25
Producer got message: 94
Producer got message: 29
Consumer storing message: 32 (queue size=3)
Producer got message: 96
Consumer storing message: 51 (queue size=3)
Producer got message: 6
Consumer storing message: 25 (queue size=3)
Producer got message: 31
[many lines deleted]
Producer got message: 80
Consumer storing message: 94 (queue size=6)
Producer got message: 33
Consumer storing message: 20 (queue size=6)
Producer got message: 48
Consumer storing message: 31 (queue size=6)
Producer got message: 52
Consumer storing message: 98 (queue size=6)
Main: about to set event
Producer got message: 13
Consumer storing message: 59 (queue size=6)
Producer received EXIT event. Exiting
Consumer storing message: 75 (queue size=6)
Consumer storing message: 97 (queue size=5)
Consumer storing message: 80 (queue size=4)
Consumer storing message: 33 (queue size=3)
Consumer storing message: 48 (queue size=2)
Consumer storing message: 52 (queue size=1)
Consumer storing message: 13 (queue size=0)
Consumer received EXIT event. Exiting
如果您通读我示例中的输出,您会看到一些有趣的事情正在发生。在顶部,您可以看到producer必须创建 5 条消息并将其中 4 条放入队列。它在可以放置第五个之前被操作系统换掉了。
在consumer随后RAN和拉断的第一条消息。它打印出该消息以及当时队列的深度:
Consumer storing message: 32 (queue size=3)
这就是您如何知道第五条消息pipeline尚未进入的方式。删除单个消息后,队列大小缩小为 3。您还知道queue可以容纳 10 条消息,因此producer线程不会被queue. 它被操作系统换掉了。
注意:您的输出会有所不同。您的输出将随着运行而变化。这就是使用线程的有趣部分!
当程序开始结束时,您能看到主线程生成event导致producer立即退出的 。在consumer仍然有一堆工作做,所以它一直运行,直到它已清理出来的pipeline。
尝试用不同的队列大小和电话打time.sleep()的producer或consumer分别模拟更长的网络或磁盘访问时间。即使对程序的这些元素进行微小的更改,也会对您的结果产生很大的影响。
这是生产者-消费者问题的一个更好的解决方案,但您可以进一步简化它。该Pipeline真的不需要这个问题。一旦你取消了日志记录,它就会变成一个queue.Queue.
以下是queue.Queue直接使用的最终代码:
import concurrent.futures
import logging
import queue
import random
import threading
import time
def producer(queue, event):
"""Pretend we're getting a number from the network."""
while not event.is_set():
message = random.randint(1, 101)
logging.info("Producer got message: %s", message)
queue.put(message)
logging.info("Producer received event. Exiting")
def consumer(queue, event):
"""Pretend we're saving a number in the database."""
while not event.is_set() or not queue.empty():
message = queue.get()
logging.info(
"Consumer storing message: %s (size=%d)", message, queue.qsize()
)
logging.info("Consumer received event. Exiting")
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
pipeline = queue.Queue(maxsize=10)
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline, event)
time.sleep(0.1)
logging.info("Main: about to set event")
event.set()
这更易于阅读,并展示了使用 Python 的内置原语如何简化复杂的问题。
Lock和Queue是解决并发问题的方便类,但标准库提供了其他类。在结束本教程之前,让我们对其中的一些进行快速调查。
线程对象
Pythonthreading模块提供了更多原语。虽然您在上面的示例中不需要这些,但它们可以在不同的用例中派上用场,因此熟悉它们是很好的。
信号
threading要查看的第一个 Python对象是threading.Semaphore. ASemaphore是具有一些特殊属性的计数器。第一个是计数是原子的。这意味着可以保证操作系统不会在递增或递减计数器的过程中换出线程。
内部计数器在调用.release()时递增,在调用时递减.acquire()。
下一个特殊属性是,如果一个线程.acquire()在计数器为零时调用,则该线程将阻塞,直到另一个线程调用.release()并将计数器增加到 1。
信号量经常用于保护容量有限的资源。例如,如果您有一个连接池并希望将该池的大小限制为特定数量。
计时器
Athreading.Timer是一种安排函数在经过一定时间后调用的方法。您Timer通过传入等待的秒数和要调用的函数来创建一个:
t = threading.Timer(30.0, my_function)
您Timer通过调用开始.start()。该函数将在指定时间后的某个时间点在新线程上调用,但请注意,没有保证它会在您想要的时间准确调用。
如果你想停止一个Timer已经开始的,你可以通过调用取消它.cancel()。.cancel()在Timer触发之后调用什么都不做,也不会产生异常。
ATimer可用于在特定时间后提示用户采取行动。如果用户在Timer过期前做了动作,.cancel()可以调用。
障碍
Athreading.Barrier可用于保持固定数量的线程同步。创建 时Barrier,调用者必须指定将在其上同步的线程数。每个线程调用.wait()的Barrier。它们都将保持阻塞状态,直到指定数量的线程在等待,然后同时全部释放。
请记住,线程是由操作系统调度的,因此,即使所有线程同时释放,它们也会被调度为一次运行一个。
a 的一个用途Barrier是允许线程池初始化它们自己。让线程在Barrier初始化后等待将确保在所有线程完成初始化之前没有任何线程开始运行。
结论:Python 中的线程
您现在已经了解了 Pythonthreading所提供的大部分内容以及如何构建线程程序及其解决的问题的一些示例。您还看到了编写和调试线程程序时出现的一些问题实例。
如果您想探索 Python 中的其他并发选项,请查看使用并发加速 Python 程序。
如果您有兴趣深入了解该asyncio模块,请阅读Python 中的异步 IO:完整演练。
无论您做什么,您现在都拥有使用 Python 线程编写程序所需的信息和信心!
特别感谢读者 JL Diaz 帮助整理介绍。


















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









