



背景
想象一下,你站在一个巨大的图书馆里,这里有成千上万本书,但每本书的目录都散落在不同的房间里,而且每间房间的索引方式都不一样。当你想要找一本关于“服务调用”的书时,你需要在 APM 房间、K8s 房间、云资源房间之间来回奔波,还要记住每个房间不同的查找规则…
这就是很多企业在可观测性领域面临的真实困境。而 UModel 就像是为这个混乱的图书馆建立了一套统一的“智能管理系统”,让你能够轻松探索和理解整个知识图谱的结构。
1.1 UModel 是什么
UModel 是一种基于图模型的可观测数据建模方法,旨在解决企业级环境中可观测数据采集、组织和利用的核心挑战。UModel 采用 Node(节点)和 Link(边)组成的图结构来描述 IT 世界,通过标准化的数据建模方式,实现可观测数据的统一表示、存储解耦和智能分析。
作为阿里云可观测体系的数据建模基础,UModel 为企业提供了一套通用的可观测“交互语言”,让人、程序和 AI 都能够理解和分析可观测数据,从而构建真正的全栈可观测能力。
核心概念
UModel 采用图论的基本概念,使用 Node(节点)和 Link(边)组成有向图来描述 IT 系统:
- Node(节点):核心部分为 Set(数据集),表示同类型实体或数据的集合,如 EntitySet(实体集)、MetricSet(指标集)、LogSet(日志集)等;此外还包含数据集的存储类型(Storage),如 SLS、Prometheus、MySQL 等
- Link(关联):表示 Node 之间的关系,如 EntitySetLink(实体关联)、DataLink(数据关联)、StorageLink(存储关联)等
- Field(字段):用于约束和描述 Set 和 Link 的属性,包含名称、类型、约束规则、分析特性等 20 多种配置项
1.2 UModel 查询是什么
UModel 查询是 EntityStore 中用于查询知识图谱元数据的专用查询接口,通过 .umodel 查询语法,可以探索 EntitySet 定义、EntitySetLink 关系以及完整的知识图谱结构,为数据建模分析和 Schema 管理提供强大支持。
查询目标区分
UModel 查询与其他查询类型的区别:
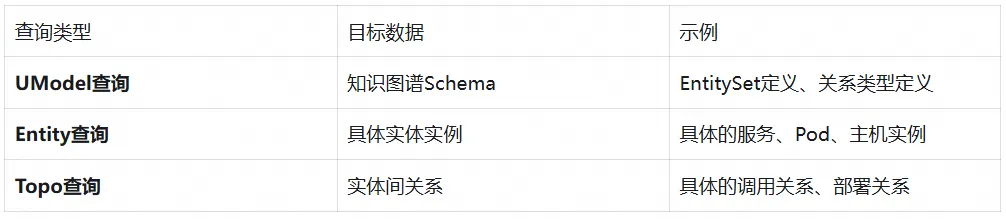
UModel 查询专注于元数据层面的探索,帮助用户理解数据模型的结构和定义,而非具体的运行时数据。
UModel 查询
2.1 数据模型
数据结构
UModel 查询返回的数据具有固定的五字段结构:
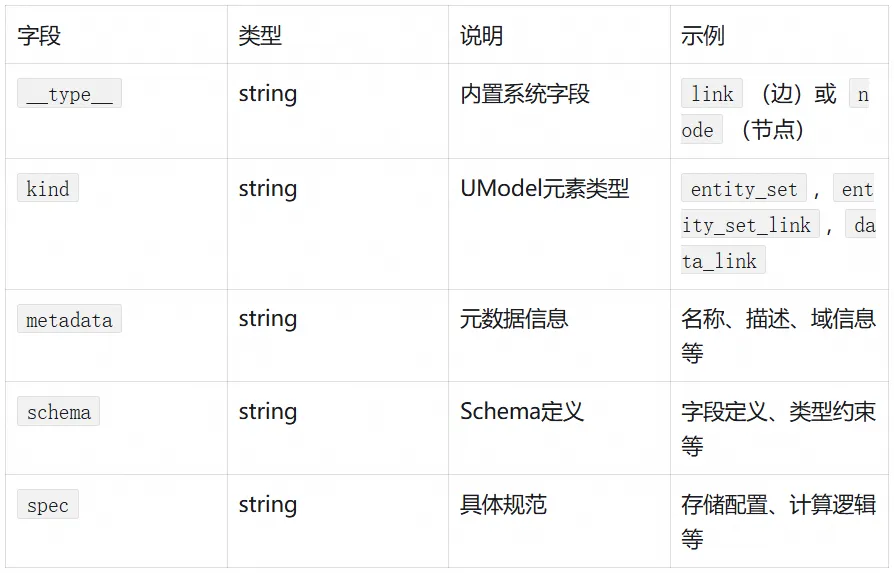
注意:metadata、schema、spec 是 JSON 格式的 string,需要使用 json_extract_scalar 函数进行提取。
数据示例

2.2 查询语法
基础查询语法
-- 基础查询格式
.umodel | [SPL操作...]
-- 带限制条件的查询
.umodel | where <condition> | limit <count>
核心查询模式
1. List 场景 - 列表查询
查询所有 UModel 数据:
-- 列出所有umodel数据(不建议使用)
.umodel
-- 带分页的查询
.umodel | limit 0, 10
按类型过滤:
-- 查询所有EntitySet定义
.umodel | where kind = 'entity_set' | limit 0, 10
-- 查询所有EntitySetLink定义
.umodel | where kind = 'entity_set_link' | limit 0, 10
-- 查询所有边类型(关系定义)
.umodel | where __type__ = 'link' | limit 0, 10
-- 查询所有节点类型(实体定义)
.umodel | where __type__ = 'node' | limit 0, 10
按属性过滤:
-- 查询特定名称的实体定义
.umodel | where json_extract_scalar(metadata, '$.name') = 'acs.ecs.instance' | limit 0, 10
-- 查询特定域的所有定义
.umodel | where json_extract_scalar(metadata, '$.domain') = 'apm' | limit 0, 10
-- 查询多个域的定义
.umodel | where json_extract_scalar(metadata, '$.domain') in ('acs', 'apm', 'k8s') | limit 0, 10
2. 图计算场景 - 关系分析
UModel 支持基于元数据的图计算,用于分析 EntitySet 之间的关系:
基础图查询语法:
.umodel | graph-match <path> project <output>
基础概念:
在图查询中,有两个关键性的图概念:
节点类型,即 label 信息,在 UModel 的元数据图查询中,为 <domain>@<kind>,例如 apm@entity_set
节点 ID,即 __entity_id__ 信息,在 UModel 的元数据图查询中,为 kind::domain::name,例如 entity_set::apm::apm.service
图查询路径(PATH)使用 ASCII 字符描述关系方向:
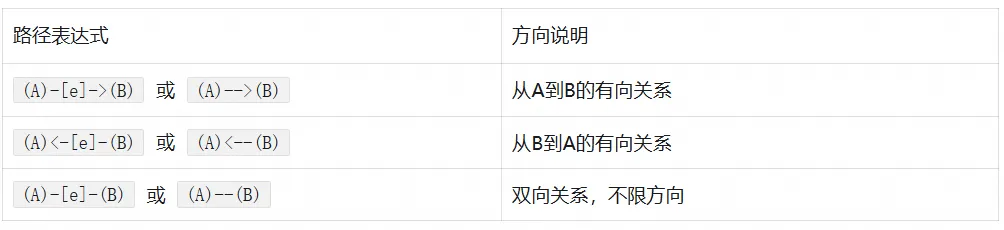
查询 EntitySet 的邻居关系:
-- 查询特定EntitySet的所有关联关系
.umodel
| graph-match (s:"acs@entity_set" {__entity_id__: 'entity_set::acs::acs.ecs.instance'})
-[e]-(d)
project s, e, d | limit 0, 10
方向性关系查询:
-- 查询指向某个EntitySet的关系
.umodel
| graph-match (s:"acs@entity_set" {__entity_id__: 'entity_set::acs::acs.ecs.instance'})
<--(d)
project s, d | limit 0, 10
-- 查询从某个EntitySet出发的关系
.umodel
| graph-match (s:"acs@entity_set" {__entity_id__: 'entity_set::acs::acs.ack.cluster'})
-->(d)
project s, d | limit 0, 10
2.3 高级查询功能
JSON 路径提取
由于 UModel 数据采用 JSON 结构存储,需要使用 JSON 函数进行字段提取:
-- 提取基础信息
.umodel
| extend
entity_name = json_extract_scalar(metadata, '$.name'),
entity_domain = json_extract_scalar(metadata, '$.domain'),
entity_description = json_extract_scalar(metadata, '$.description.zh_cn')
| project entity_name, entity_domain, entity_description | limit 0, 100
复杂条件筛选
-- 多条件组合查询
.umodel
| where kind = 'entity_set'
and json_extract_scalar(metadata, '$.domain') in ('apm', 'k8s')
and json_array_length(json_extract(spec, '$.fields')) > 5
| extend
entity_name = json_extract_scalar(metadata, '$.name'),
field_count = json_array_length(json_extract(spec, '$.fields'))
| sort field_count desc
| limit 20
聚合分析
-- 按域统计EntitySet数量
.umodel
| where kind = 'entity_set'
| extend domain = json_extract_scalar(metadata, '$.domain')
| stats entity_count = count() by domain
| sort entity_count desc
2.4 性能优化建议
使用精确过滤
-- 优化前:范围过大
.umodel | where json_extract_scalar(metadata, '$.name') like '%service%'
-- 优化后:精确匹配
.umodel | where kind = 'entity_set'
and json_extract_scalar(metadata, '$.domain') = 'apm'
and json_extract_scalar(metadata, '$.name') = 'apm.service'
过滤前置
-- 优化前:后期过滤
.umodel
| extend name = json_extract_scalar(metadata, '$.name')
| where name = 'apm.service'
-- 优化后:过滤前置
.umodel
| where json_extract_scalar(metadata, '$.name') = 'apm.service'
| extend name = json_extract_scalar(metadata, '$.name')
图查询优化
-- 优化前:全图搜索
.umodel | graph-match (s)-[e]-(d) project s, e, d
-- 优化后:指定起始点
.umodel
| graph-match (s:"apm@entity_set" {__entity_id__: 'entity_set::apm::apm.service'})
-[e]-(d)
project s, e, d
UModel 查询具体应用场景
UModel 查询在实际应用中能够解决多种场景下的问题,为数据建模、Schema 管理和知识图谱分析提供强大支持。
3.1 Schema 探索与发现
场景描述
在大型可观测性系统中,可能存在数百个 EntitySet 定义,分布在不同的域(domain)中。用户需要快速了解系统中定义了哪些实体类型,以及它们的基本信息。
应用示例
探索所有实体类型:
-- 列出所有EntitySet及其基本信息
.umodel
| where kind = 'entity_set'
| extend
entity_name = json_extract_scalar(metadata, '$.name'),
entity_domain = json_extract_scalar(metadata, '$.domain'),
description = json_extract_scalar(metadata, '$.description.zh_cn')
| project entity_name, entity_domain, description
| sort entity_domain, entity_name
| limit 0, 100
按域分类查看:
-- 查看特定域(如APM)下的所有实体定义
.umodel
| where kind = 'entity_set'
and json_extract_scalar(metadata, '$.domain') = 'apm'
| extend
entity_name = json_extract_scalar(metadata, '$.name'),
description = json_extract_scalar(metadata, '$.short_description.zh_cn')
| project entity_name, description
| limit 0, 50
3.2 数据建模分析
场景描述
在进行数据建模优化时,需要分析现有 EntitySet 的字段复杂度、主键设计、索引配置等信息,以便识别需要优化的模型。
应用示例
分析字段复杂度:
-- 分析各域下EntitySet的字段数量分布
.umodel
| where kind = 'entity_set'
| extend
domain = json_extract_scalar(metadata, '$.domain'),
entity_name = json_extract_scalar(metadata, '$.name'),
field_count = json_array_length(json_extract(spec, '$.fields'))
| stats
avg_fields = avg(field_count),
max_fields = max(field_count),
min_fields = min(field_count),
entity_count = count()
by domain
| sort entity_count desc
查找复杂实体:
-- 找出字段数量最多的EntitySet(可能需要优化)
.umodel
| where kind = 'entity_set'
| extend
entity_name = json_extract_scalar(metadata, '$.name'),
domain = json_extract_scalar(metadata, '$.domain'),
field_count = json_array_length(json_extract(spec, '$.fields'))
| sort field_count desc
| limit 20
3.3 关系图谱分析
场景描述
理解 EntitySet 之间的关系对于构建完整的知识图谱至关重要。通过图查询可以分析实体间的关联关系,发现数据模型中的依赖和连接。
应用示例
查询实体的所有关联关系:
-- 查询某个EntitySet(如apm.service)的所有关联关系
.umodel
| graph-match (s:"apm@entity_set" {__entity_id__: 'entity_set::apm::apm.service'})
-[e]-(d)
project s, e, d
| limit 0, 50
分析关系类型分布:
-- 统计不同关系类型的数量
.umodel
| where kind = 'entity_set_link'
| extend
link_name = json_extract_scalar(metadata, '$.name'),
link_type = json_extract_scalar(metadata, '$.link_type')
| stats limk_count = count() by link_type
| sort limk_count desc
查找特定关系:
-- 查找所有"runs_on"类型的关系定义
.umodel
| where kind = 'entity_set_link'
and json_extract_scalar(metadata, '$.link_type') = 'runs_on'
| extend
link_name = json_extract_scalar(metadata, '$.name'),
source = json_extract_scalar(metadata, '$.source'),
target = json_extract_scalar(metadata, '$.target')
| project link_name, source, target
3.4 元数据质量检查
场景描述
确保 UModel 元数据的完整性和一致性,检查缺失的描述、未定义的字段等问题。
应用示例
检查缺失描述的 EntitySet:
-- 找出没有中文描述的EntitySet
.umodel
| where kind = 'entity_set'
and (json_extract_scalar(metadata, '$.description.zh_cn') = ''
or json_extract_scalar(metadata, '$.description.zh_cn') is null)
| extend
entity_name = json_extract_scalar(metadata, '$.name'),
domain = json_extract_scalar(metadata, '$.domain')
| project entity_name, domain
验证字段定义完整性:
-- 检查没有定义字段的EntitySet
.umodel
| where kind = 'entity_set'
and (json_extract(spec, '$.fields') is null
or json_array_length(json_extract(spec, '$.fields')) = 0)
| extend
entity_name = json_extract_scalar(metadata, '$.name'),
domain = json_extract_scalar(metadata, '$.domain')
| project entity_name, domain
3.5 跨域关联分析
场景描述
在复杂的可观测性系统中,不同域(如 APM、K8s、云资源)的实体可能存在关联关系。通过 UModel 查询可以分析这些跨域的关联模式。
应用示例
查找跨域关系:
-- 查找连接不同域的EntitySetLink
.umodel
| where kind = 'entity_set_link'
| extend
link_name = json_extract_scalar(metadata, '$.name'),
source_domain = json_extract_scalar(spec, '$.src.domain'),
target_domain = json_extract_scalar(spec, '$.dest.domain')
| where source_domain != target_domain
| project link_name, source_domain, target_domain
| limit 0, 50
分析域间连接度:
-- 统计各域之间的连接关系数量
.umodel
| where kind = 'entity_set_link'
| extend
source_domain = json_extract_scalar(spec, '$.src.domain'),
target_domain = json_extract_scalar(spec, '$.dest.domain')
| stats count = count() by source_domain, target_domain
| sort count desc
3.6 版本与演进分析
场景描述
UModel Schema 会随着业务发展而演进,需要跟踪 Schema 的版本变化和演进历史。
应用示例
查看 Schema 版本信息:
-- 查看所有EntitySet的Schema版本
.umodel
| where kind = 'entity_set'
| extend
entity_name = json_extract_scalar(metadata, '$.name'),
schema_version = json_extract_scalar(schema, '$.version'),
schema_url = json_extract_scalar(schema, '$.url')
| project entity_name, schema_version, schema_url
| limit 0, 100
3.7 快速定位与检索
场景描述
在大量元数据中快速找到特定的 EntitySet 或关系定义,支持模糊匹配和精确查询。
应用示例
按名称模糊搜索:
-- 搜索包含"service"的EntitySet
.umodel
| where kind = 'entity_set'
and json_extract_scalar(metadata, '$.name') like '%service%'
| extend
entity_name = json_extract_scalar(metadata, '$.name'),
domain = json_extract_scalar(metadata, '$.domain')
| project entity_name, domain
| limit 0, 20
精确查找特定实体:
-- 精确查找特定EntitySet的完整定义
.umodel
| where json_extract_scalar(metadata, '$.name') = 'apm.service'
| limit 1
总结
UModel 查询作为 EntityStore 中专门用于查询知识图谱元数据的接口,为可观测性数据建模提供了强大的支持能力。通过 UModel 查询可以:
- 探索 Schema 结构:快速了解系统中定义的所有实体类型和关系类型
- 分析数据模型:深入分析 EntitySet 的字段设计、主键配置、复杂度等
- 构建关系图谱:通过图查询分析实体间的关联关系,理解知识图谱的拓扑结构
- 质量检查:验证元数据的完整性和一致性
- 跨域分析:分析不同域之间的关联模式
- 快速检索:在大量元数据中快速定位目标定义
这些能力使得 UModel 查询成为数据建模分析、Schema 管理和知识图谱探索的不可或缺的工具,为构建和维护高质量的可观测性数据模型提供了坚实的基础。
点击此处查看视频演示。


















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









