



 Pandas是Python用于数据操作的核心库,涉及数据结构如Series和DataFrame,数据读取如CSV和Excel,以及数据清洗和分析功能,如dropna(),fillna(),replace()和describe()等。通过掌握这些基础,能有效提升数据分析效率。
Pandas是Python用于数据操作的核心库,涉及数据结构如Series和DataFrame,数据读取如CSV和Excel,以及数据清洗和分析功能,如dropna(),fillna(),replace()和describe()等。通过掌握这些基础,能有效提升数据分析效率。
Pandas是Python中一种用于数据操作和数据处理的库,它提供了数据结构和数据分析工具。在Python数据分析中,Pandas是最常用的数据操作和数据处理库之一。本文将介绍Pandas的基本使用,包括数据结构、数据读取、数据清洗和数据分析等方面。
数据结构
Pandas中有两种主要的数据结构:Series和DataFrame。Series是一种一维数组结构,可以存储不同类型的数据。DataFrame是一种二维表格结构,可以存储多种类型的数据,类似于Excel表格。
数据读取
在Pandas中,可以使用read_csv()函数读取CSV文件中的数据,也可以使用read_excel()函数读取Excel文件中的数据。例如,以下代码读取名为data.csv的CSV文件:
import pandas as pd
data = pd.read_csv('data.csv')
print(data)
数据读取效果图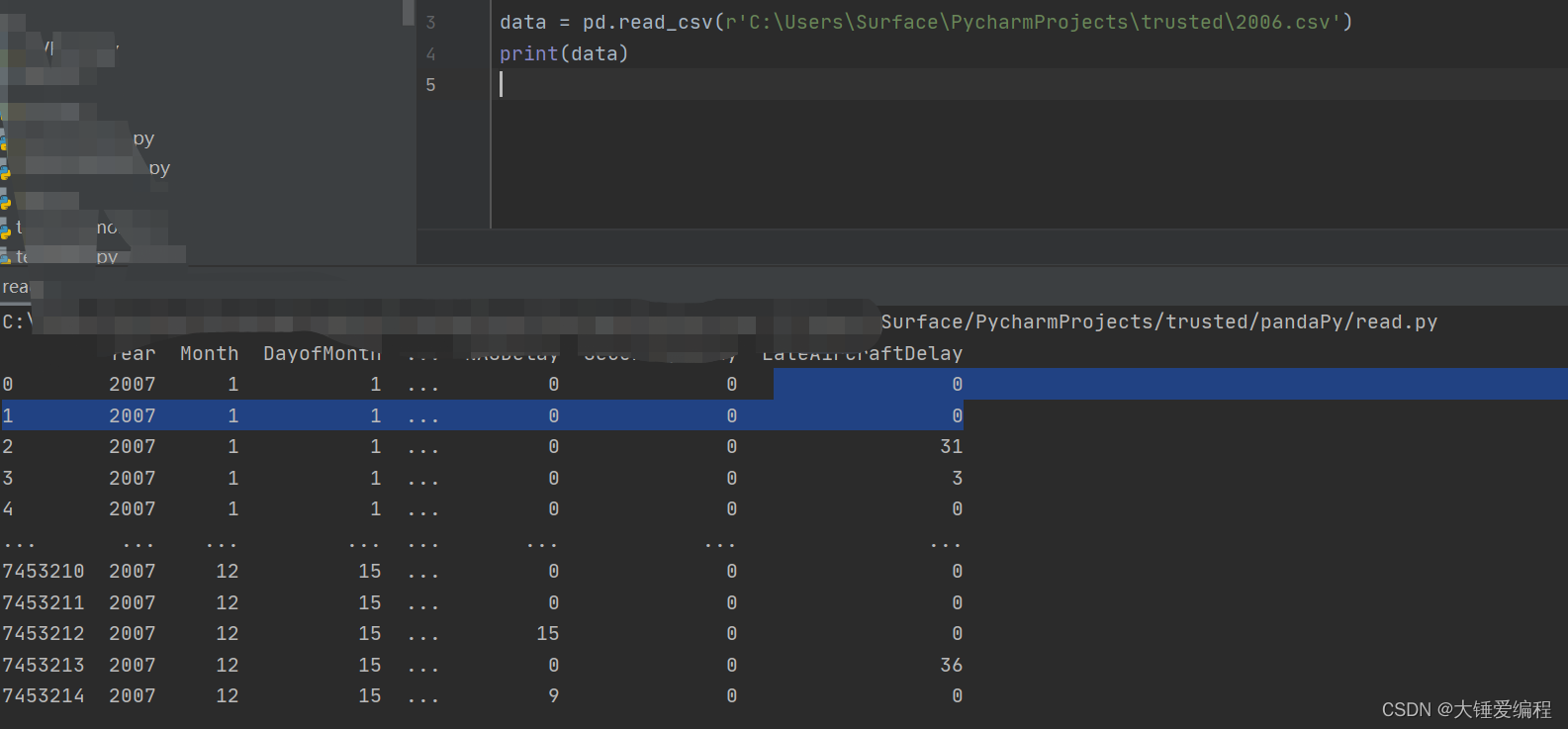
使用Python读取文件时,windows机器可能会出现(unicode error) 'unicodeescape'的问题。
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
对应的解决办法是在python文件的读取地址前加r
r'C:\Users\Surface\PycharmProjects\trusted\2006.csv'
数据清洗
在进行数据分析之前,需要对数据进行清洗以确保数据的准确性和一致性。在Pandas中,可以使用dropna()函数删除缺失值,使用fillna()函数填充缺失值,使用replace()函数替换特定的值等等。例如,以下代码删除名为data的DataFrame中的所有缺失值:
import pandas as pd
data = pd.read_csv('data.csv')
data = data.dropna()
print(data)
数据分析
在进行数据分析时,可以使用Pandas提供的各种函数和方法。例如,可以使用describe()函数计算DataFrame中各列的统计数据,使用groupby()函数对DataFrame进行分组操作,使用plot()函数绘制数据可视化图表等等。以下代码演示了如何使用describe()函数计算名为data的DataFrame中各列的统计数据:
import pandas as pd
data = pd.read_csv('data.csv')
print(data.describe())
样例数据对应的统计值:
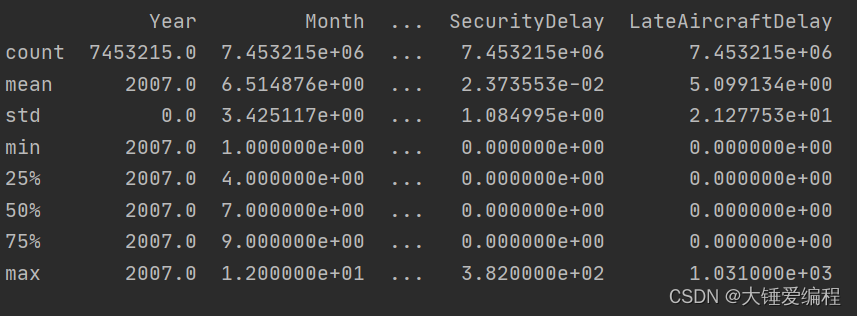
总结
Pandas是Python中最常用的数据操作和数据处理库之一。本文介绍了Pandas的基本使用,包括数据结构、数据读取、数据清洗和数据分析等方面。通过掌握Pandas的基本用法,可以更有效地处理和分析数据,进而提高数据分析的效率。


















 6448
6448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











