




 本文深入探讨了在调试Yolo3算法源码时遇到的BatchNorm2d层产生Nan值的问题,通过代码示例详细解析了BatchNorm2d在训练和测试阶段的工作原理,包括参数解释、算法实现及如何避免Nan值出现。
本文深入探讨了在调试Yolo3算法源码时遇到的BatchNorm2d层产生Nan值的问题,通过代码示例详细解析了BatchNorm2d在训练和测试阶段的工作原理,包括参数解释、算法实现及如何避免Nan值出现。
最近小编在研究yolo3的算法源码,在调试过程中发现中间层的BatchNorm2d的结果竟然出现了Nan。

第一次遇到这种情况,为了找出其中的原因,小编查阅了Pytorch官网关于BatchNorm2d的函数解释和网上关于该函数的相关博客,脑壳还是有点模糊,没有代码的测试验证,仅仅用文字去解释BatchNorm2d函数,初学者很容易一头雾水,半知半懂。
本文结合代码去验证BatchNorm2d的算法实现,若有不懂,读者可以参考文中代码并修改参数,来验证自己对该函数的理解是否准确。
实际项目中,我们处理的数据大部分是4维的,如:
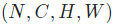
其中N为数据个数,C为通道数,H,W分别表示图形的宽和高。
我们用BatchNorm2d归一化上述的数据结构,值得注意的是归一化是每个通道的归一化,以每个通道作为视角来归一化数据。
首先引用Pytorch官网对BatchNorm2d的描述:

BatchNorm2d的计算公式:
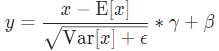
其中x为需要归一化的输入数据,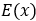 和
和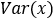 为批量数据的均值和方差,
为批量数据的均值和方差,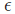 为防止分母出现零所增加的变量,γ和β是对输入值进行仿射操作,即线性变换。γ和β的默认值分别为1和0,仿射包含了不进行仿射的结果,使得BatchNormlization的引入至少不降低模型,γ和β为模型的学习参数。
为防止分母出现零所增加的变量,γ和β是对输入值进行仿射操作,即线性变换。γ和β的默认值分别为1和0,仿射包含了不进行仿射的结果,使得BatchNormlization的引入至少不降低模型,γ和β为模型的学习参数。
下面介绍BatchNorm2d的参数解释:
num_features:通道数,即维度大小
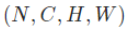 的C。
的C。
eps:为使数值稳定而在分母上增加的值。默认值:1 e-5
momentum:期望和方差的更新参数,与动量梯度下降法类似,期望和方差的更新公式:

 为模型的均值或方差,
为模型的均值或方差, 为当前观测值的均值或方差,
为当前观测值的均值或方差, 为更新后的均值或方差,momentum为更新参数。
为更新后的均值或方差,momentum为更新参数。
affine:归一化是否需要仿射,若设置为True,则需要对模型进行仿射,默认值为True。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1017
1017






 到【灌水乐园】发言
到【灌水乐园】发言







