







写在前面
YOLO来源于“you only look once”的简写,作者的想法是只看一次就能知道目标在哪里,跟人眼看到的第一反应一样,作为业内实时性、不错的精度的一种目标检测算法,yolo在过去的几年时间里,已经在工业应用中发挥着巨大的作用,如无人驾驶、农作物病虫害预防、医学检查等。
一、YOLO算法核心思想
YOLO系列算法的核心思想可以概括为:将输入图像划分为网格,每个网格单元负责预测中心点落在该区域内的目标。这种把目标检测作为一个回归问题进行处理,把整个图像作为网络的输入,仅仅经过一个神经网络,得到目标边界框的位置以及所属的类别的基本思想贯穿了yolo系列的许多版本,在迭代过程中还进一步得到了效果增强。
YOLOv1的实现
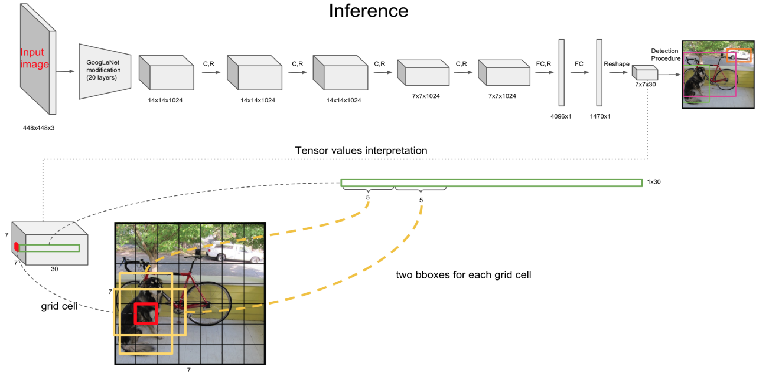
图1 yolo检测过程
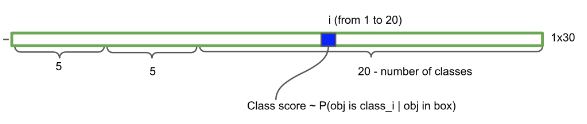
图2 每个格子的检测信息排列
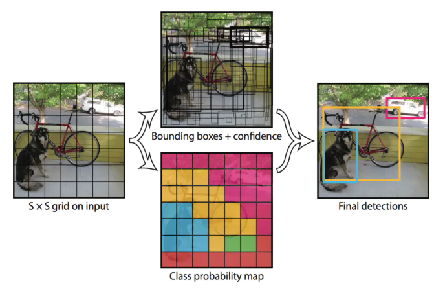
图3 检测过程可视化参考
具体的过程为:将图像分为 7x7 个区域进行预测。每个区域都会用两个bounding box去检测,如果一个目标的中心落入一个区域重,改区域就负责该目标检测,最终输出 向量 的前五个数值,分别是 bounding box的 x,y,w,h,c,即 bounding box的中心坐标 x,y,bounding box的宽高 w,h,bounding box的置信度。置信度就是算法的自信心得分,越高表示越坚信这个检测的目标没错。一个中心点用两个 bounding box检测 作的好处可以减少漏检,因为可以适应不同形状的 bounding box,进而提高bounding box的准确率。2 个 bounding box都会保留,最后通过 NMS 选择出最佳的 bounding box。而后面的 20 个,就是类别的概率,YOLO v1 是在 VOC 数据集上训练的,因此一共 20 个类。输出 向量 总共加起来就是 7×7×(2×5+20),写成公式就是:SxSx(Bx5+C)。
# 伪代码示意v1的预测输出
output = S × S × (B*5 + C) # 7×7×30的张量
以上是YOLOv1版本的核心思想,本文接下来是围绕着之前的目标检测之YoloV5+旋转目标来聊聊v5在这上面有了哪些改动。
YOLOv5知识点基本概念
- Anchor:Anchor是借用了Faster-RCNN的思想,在图像上预设好的不同大小,不同长宽比的参照框。Anchor解决了scale和aspect ratio变化范围大的问题,即将单元格的预测框空间划分为了几个子空间,降低模型学习难度。
- C3与Bottleneck:C3模块是一个关键的特征提取组件,它结合了CSPNet和残差连接的思想, 与普通残差块的区别在于:采用CSPNet的双路径结构,减少计算量,通过e参数(默认0.5)控制隐藏层通道压缩率,在head部分可禁用残差连接(shortcut=False),这种设计在保持特征提取能力的同时,显著提升了计算效率。
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # 隐藏层通道数
self.cv1 = Conv(c1, c_, 1, 1) # 1x1卷积降维
self.cv2 = Conv(c1, c_, 1, 1) # 1x1卷积降维
self.cv3 = Conv(2 * c_, c2, 1) # 1x1卷积融合
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
Bottleneck是C3模块中的核心组件,它是一种轻量级的残差结构, 结构特点 :
- 采用1x1+3x3的卷积组合
- 通过扩展系数e控制中间层通道数(默认0.5)
- 支持分组卷积(g参数)
- 条件式残差连接(输入输出通道相同且shortcut=True时启用)
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # 隐藏层通道数
self.cv1 = Conv(c1, c_, 1, 1) # 1x1卷积降维
self.cv2 = Conv(c_, c2, 3, 1, g=g) # 3x3卷积特征提取
self.add = shortcut and c1 == c2 # 是否使用残差连接
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
在yolov5中,通过.yaml文件来进行配置。
[-1, 3, C3, [128]] # 使用3个Bottleneck
- CSPNet(Cross Stage Partial Network):CSPNet(Cross Stage Partial Network)是一种用于提升CNN性能的网络设计方法,其核心思想是通过 跨阶段部分连接 来优化梯度流动和计算效率。在YOLOv5中,C3模块就是基于CSPNet改进的关键组件。核心思想是:
- 分治策略 :将特征图在通道维度分成两部分
- 跨阶段连接 :让部分特征直接传递到下一阶段
- 梯度分流 :缓解梯度重复计算问题
CSPNet原始结构:
# 原始CSP结构(简化版示意)
class CSPBlock(nn.Module):
def __init__(self, c1, c2, n=1):
super().__init__()
self.cv1 = Conv(c1, c2//2, 1) # 主路径
self.cv2 = Conv(c1, c2//2, 1) # 旁路路径
self.m = nn.Sequential(*[Bottleneck(c2//2, c2//2) for _ in range(n)])
def forward(self, x):
y1 = self.m(self.cv1(x))
y2 = self.cv2(x)
return torch.cat([y1, y2], 1)
但是在yolov5中就是上面的C3模块了。
4. SPP(Spatial Pyramid Pooling:SPP(Spatial Pyramid Pooling,空间金字塔池化)是YOLOv5中用于处理多尺度特征的关键模块。在YOLOv5 v6.0中,其改进版本SPPF(Spatial Pyramid Pooling - Fast)被采用。核心思想:
- 多尺度特征融合 :通过不同大小的池化核捕获多尺度特征
- 固定长度输出 :无论输入尺寸如何变化,输出特征维度固定
- 空间信息保留 :在池化过程中保持空间层级信息
网络结构:
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5): # 等效于原SPP的(k=5,9,13)
super().__init__()
c_ = c1 // 2 # 隐藏层通道
self.cv1 = Conv(c1, c_, 1, 1) # 降维
self.cv2 = Conv(c_ * 4, c2, 1, 1) # 升维
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
y3 = self.m(y2)
return self.cv2(torch.cat([x, y1, y2, y3], 1))
backbone:
[[-1, 1, SPPF, [1024, 5]], # 输入1024通道,等效k=5
- FPN(Feature pyramid network):FPN(Feature Pyramid Network,特征金字塔网络)是YOLOv5中用于多尺度特征融合的关键结构。核心思想:自顶向下路径 ,将深层语义信息传递到浅层。 横向连接 :融合不同分辨率的特征图。 多尺度预测 :在不同层级检测不同大小的目标。
# 简化的FPN结构实现
class FPN(nn.Module):
def __init__(self, channels=[256, 512, 1024]):
super().__init__()
# 上采样模块
self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
# 横向连接卷积
self.lateral_convs = nn.ModuleList([
Conv(c, c//2, 1) for c in channels[::-1]
])
# 输出卷积
self.output_convs = nn.ModuleList([
Conv(c//2, c//2, 3) for _ in channels
])
def forward(self, features):
# features = [P3, P4, P5] 多尺度特征
outputs = []
x = features[-1]
for i, f in enumerate(features[:-1][::-1]):
x = self.upsample(x)
x = torch.cat([self.lateral_convs[i](f), x], 1)
outputs.append(self.output_convs[i](x))
return outputs
head:
[[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 上采样
[[-1, 6], 1, Concat, [1]], # 横向连接(P4)
[-1, 3, C3, [512, False]], # 特征融合
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 上采样
[[-1, 4], 1, Concat, [1]], # 横向连接(P3)
[-1, 3, C3, [256, False]], # 特征融合
- PANet(Path Aggregation Network: PANet(Path Aggregation Network,路径聚合网络)是YOLOv5中用于增强特征金字塔网络(FPN)性能的关键结构。核心思想:
- 双向特征融合 :同时实现自顶向下和自底向上的特征传递
- 多路径增强 :通过额外路径增强特征表达能力
- 精确位置信息保留 :特别提升小目标检测能力
# 简化的PANet结构实现
class PANet(nn.Module):
def __init__(self, channels=[256, 512, 1024]):
super().__init__()
# 下采样模块
self.downsample = Conv(c1, c2, 3, 2)
# 横向连接卷积
self.lateral_convs = nn.ModuleList([
Conv(c, c//2, 1) for c in channels
])
# 输出卷积
self.output_convs = nn.ModuleList([
Conv(c, c, 3) for c in channels
])
def forward(self, features):
# features = [P3, P4, P5] 多尺度特征
# 自底向上路径
for i in range(1, len(features)):
features[i] = self.downsample(features[i-1]) + features[i]
return features
head:
# FPN路径(自顶向下)
[[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]],
# PAN路径(自底向上)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]]
YOLOv5的关键改进
- 引入Anchor机制:从随机初始化边界框改为使用预设锚框,这意味着原来部分的随机初始化边框和真实框差别很离谱导致不必要的计算的问题得到了解决。在.yaml文件中有Anchor的定义:
anchors:
- [10,13, 16,30, 33,23] # P3/8层anchor(小目标)
- [30,61, 62,45, 59,119] # P4/16层anchor(中目标)
- [116,90, 156,198, 373,326] # P5/32层anchor(大目标)
- 多尺度预测:从单一尺度扩展到3个检测层(P3/8, P4/16, P5/32),可以从小、中、大三个尺度检测目标对象,极大地减少了漏检情况。在.yaml文件中有多尺度的定义:
head:
[[17, 20, 23], 1, Detect, [nc, anchors]], # 三个检测层:P3/8, P4/16, P5/32
- 网络结构优化:引入Backbone-Neck-Head(Prediction)的模块化设计
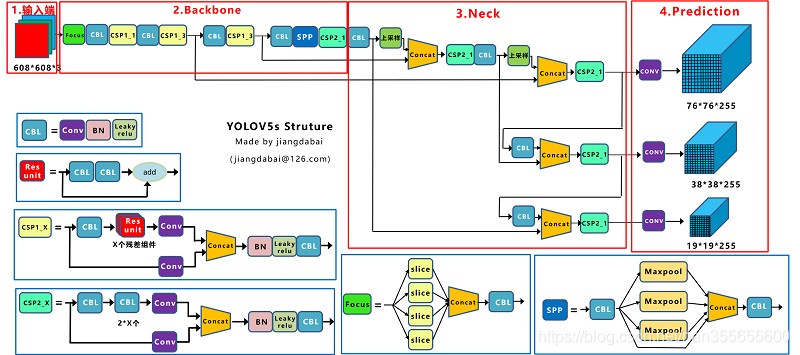
图4 YOLOV5网络结构图(来源:https://blog.youkuaiyun.com/nan355655600/article/details/107852288)
二、YOLOv5架构解析
1. 输入处理(Input)
代码位置:datasets.py
class LoadImagesAndLabels:
def __getitem__(self, index):
# Mosaic数据增强
if self.mosaic:
img, labels = load_mosaic(self, index)
# 其他预处理
img = letterbox(img, self.img_size)[0]
关键改进:
- Mosaic数据增强:4张图片随即缩放、随机裁剪、随机排布的方式进行拼接成新的图片
- 自适应锚框计算:根据数据集自动调整,比如:
anchors:
- [10,13, 16,30, 33,23] # P3/8层anchor(小目标)
- [30,61, 62,45, 59,119] # P4/16层anchor(中目标)
- [116,90, 156,198, 373,326] # P5/32层anchor(大目标)
这是在COCO数据集上的初始锚框。
2. 特征提取(Backbone)
代码位置:yolov5n.yaml
backbone:
[[-1, 1, Conv, [64, 6, 2, 2]], # P1/2
[-1, 1, Conv, [128, 3, 2]], # P2/4
[-1, 3, C3, [128]], # 特征提取
...
[-1, 1, SPPF, [1024, 5]] # 特征金字塔池化
]
核心组件:
- C3模块:结合CSPNet和Bottleneck的轻量级设计
- SPPF:改进的空间金字塔池化,加速特征融合
3. 特征融合(Neck)
代码位置:yolov5n.yaml
head:
[[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 上采样
[[-1, 6], 1, Concat, [1]], # 特征拼接
[-1, 3, C3, [512, False]], # 特征处理
...
]
创新点:
- FPN+PAN结构:双向特征金字塔
- 多尺度融合:浅层位置信息+深层语义信息
4. 预测头(Head)
代码位置:yolo.py
class Detect(nn.Module):
def __init__(self, nc=80, anchors=()):
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch)
def forward(self, x):
# 多尺度预测处理
for i in range(self.nl): # 检测层数量
x[i] = self.m[i](x[i]) # 预测输出
关键特性:
- 三尺度预测:P3/8(小目标)、P4/16(中目标)、P5/32(大目标)
- 自适应损失计算:根据目标大小自动调整损失权重
5. 多尺度预测处理
代码位置:yolo.py
def forward(self, x):
z = [] # 推理输出
for i in range(self.nl): # 对每个检测层处理
# 不同尺度的特征图处理
if not self.training: # 推理时处理
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
四、参考内容
【pytorch】目标检测:新手也能彻底搞懂的YOLOv5详解
目标检测之YoloV5+旋转目标
Yolov3、v4、v5、Yolox模型权重及网络结构图资源下载

















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









