



 本文详细介绍爬虫的工作原理,包括如何通过URL请求获取网页源代码,使用json库、BeautifulSoup库或正则表达式筛选数据,以及如何存储数据到本地或数据库。文章还介绍了提高爬虫效率的方法,如多线程和IP代理的使用。
本文详细介绍爬虫的工作原理,包括如何通过URL请求获取网页源代码,使用json库、BeautifulSoup库或正则表达式筛选数据,以及如何存储数据到本地或数据库。文章还介绍了提高爬虫效率的方法,如多线程和IP代理的使用。
思路
爬虫的原理,是通过给定的一个 URL(就是类似于 http://www.baidu.com 这样的网址) 请求,去访问一个网页,获取那个网页上的源代码(右键,查看网页源代码,我们需要的数据就藏在这些源代码里面)并返回来。
然后,通过一些手段(比如说json库,BeautifulSoup库,正则表达式等)从网页源代码中筛选出我们想要的数据(当然,前提是我们需要分析网页结构,知道自己想要什么数据,以及这些数据存放在网页的哪儿,存放的位置有什么特征等)。
最后,将我们获取到的数据按照一定的格式,存储到本地或者数据库中,这样就完成了爬虫的全部工作。
如果你嫌爬虫效率低,可以开多线程(就是相当于几十只爬虫同时给你爬,效率直接翻了几十倍);如果担心爬取频率过高被网站封 IP,可以挂 IP 代理(相当于打几枪换个地方,对方网站就不知道你究竟是爬虫还是正常访问的用户了);如果对方网站有反爬机制,那么也有一些骚操作可以绕过反爬机制。
————————————————
本文大多为参考,自己留个笔记
原文链接:https://blog.youkuaiyun.com/wenxuhonghe/article/details/84897936
分析网站的页面结构
可见原文链接:https://blog.youkuaiyun.com/wenxuhonghe/article/details/84897936
叙述的很详细!
爬虫编码阶段
一是主函数,作为程序的入口,爬虫调度器,二是网络请求函数,三是网页解析函数,四是数据存储函数。
get_data :其参数是目标网页 url,这个函数可以模拟浏览器访问 url,获取并将网页的内容返回。
parse_data :其参数是网页的内容,这个函数主要是用来解析网页内容,筛选提取出关键的信息,并打包成列表返回。
save_data :其参数是数据的列表,这个函数用来将列表中的数据写入本地的文件中。
main :这个函数是爬虫程序的调度器,可以根据事先分析好的 url 的规则,不断的构造新的请求 url,并调用其他三个函数,获取数据并保存到本地,直到结束。
if name == ‘main’ :这是主程序的入口,在这里调用 main 函数,启动爬虫调度器即可。
1、getdata.py模块
包含网络请求函数 :get_data (url)
import requests
def get_data(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
# 这里设置编码格式
r.encoding = r.apparent_encoding
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
注意:一般的网站的编码格式都是 UTF-8,所以当你系统的默认编码也是 UTF-8 时,也就是说,你的默认编码方式和目标网站的编码方式一致时,即使不明确设置编码方式,也不会出问题。但是如果不一致,便会出现乱码。这也是为什么经常有 “明明在我电脑上运行是好的,为什么在你电脑上就乱码了” 这样的问题。
这种问题解决也很简单,只要在代码中设置一下 encoding 即可。
这里建议一种方法,r.encoding = r.apparent_encoding ,这个可以自动推测目标网站的编码格式,省的你自己去一个个设置(当然极少数情况下它可能会推测错误出现乱码,到时候你再手动去查看网页编码,手动设置吧)。
————————————————
编码参考原文链接:https://blog.youkuaiyun.com/wenxuhonghe/article/details/95062701
2、parsedata.py模块
包含网页解析函数:parse_data(html)
这部分的写法多种多样,有很多发挥的空间,也没有什么太多固定的模式,因为这部分的写法是要随着不同网站的页面结构来做调整的,比如说有的网站提供了数据的 api 接口,那么返回的数据就是 json 格式,我们只需要调用 json 库就可以完成数据解析,而大部分的网站只能通过从网页源代码中一层层筛选(筛选手段也多种多样,什么正则表达式,beautifulsoup等等)。
这里需要根据数据的形式来选择不同的筛选策略,所以,知道原理就可以了,习惯什么方法就用什么方法,反正最后能拿到数据就好了。
import bs4
from getdata import get_data
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html, 'html.parser')
info = []
# 获取电影列表
tbList = bsobj.find_all('table', attrs={'class': 'tbspan'})
# 对电影列表中的每一部电影单独处理
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
# 获取电影的名称
name = link["title"]
# 获取详情页面的 url
url = 'https://www.dy2018.com' + link["href"]
# 将数据存放到电影信息列表里
movie.append(name)
movie.append(url)
try:
# 访问电影的详情页面,查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url), 'html.parser')
tbody = temp.find_all('tbody')
# 下载链接有多个(也可能没有),这里将所有链接都放进来
for i in tbody:
download = i.a.text
movie.append(download)
# print(movie)
# 将此电影的信息加入到电影列表中
info.append(movie)
except Exception as e:
print(e)
return info
3、savedata.py模块
包含数据存储函数:save_data(data)
这个函数目的是将数据存储到本地文件或数据库中,具体的写法要根据实际需要的存储形式来定,我这里是将数据存放在本地的 csv 文件中。
可以在这里写一些简单的数据处理的操作,比如说:数据清洗,数据去重等操作。
import pandas as pd
def save_data(data):
'''
功能:将 data 中的信息输出到文件中/或数据库中。
参数:data 将要保存的数据
'''
filename = '动作片.csv'
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename, encoding='utf_8_sig', mode='a', index=False, sep=',', header=False)
#用 excel 打开保存好的 csv 文件时出现乱码(用记事本打开没问题)
# 文件的编码方式和 Excel 的解码方式不一致导致的。在 dataframe.to_csv 这句,参数里添加一个 encoding='utf_8_sig',指定文件的编码格式
注意:存文件时的编码错误,就是爬取过程中没问题,但是用 excel 打开保存好的 csv 文件时出现乱码(用记事本打开没问题)。这个其实就是文件的编码方式和 Excel 的解码方式不一致导致的。在 dataframe.to_csv 这句,参数里添加一个 encoding=‘utf_8_sig’,指定文件的编码格式,应该就可以解决了
4 、main.py
包含爬虫调度器:main()
这个函数负责根据 url 生成规则,构造新的 url 请求,然后依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据。
所谓爬虫调度器,就是控制爬虫什么时候开始爬,多少只爬虫一起爬,爬哪个网页,爬多久休息一次,等等。
from getdata import get_data
from parsedata import parse_data
from savadata import save_data
def main():
# 循环爬取多页数据
for page in range(1, 114):
#在 main 函数中设置的页码爬取范围是 第1页到第113页,可以更改这里的数字,来改变爬取的页码范围
print('正在爬取:第' + str(page) + '页......')
# 根据之前分析的 URL 的组成结构,构造新的 url
if page == 1:
index = 'index'
else:
index = 'index_' + str(page)
url = 'https://www.dy2018.com/2/' + index + '.html'
# 依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据
html = get_data(url)
movies = parse_data(html)
save_data(movies)
print('第' + str(page) + '页完成!')
if __name__ == '__main__':
print('爬虫启动成功!')
main()
print('爬虫执行完毕!')
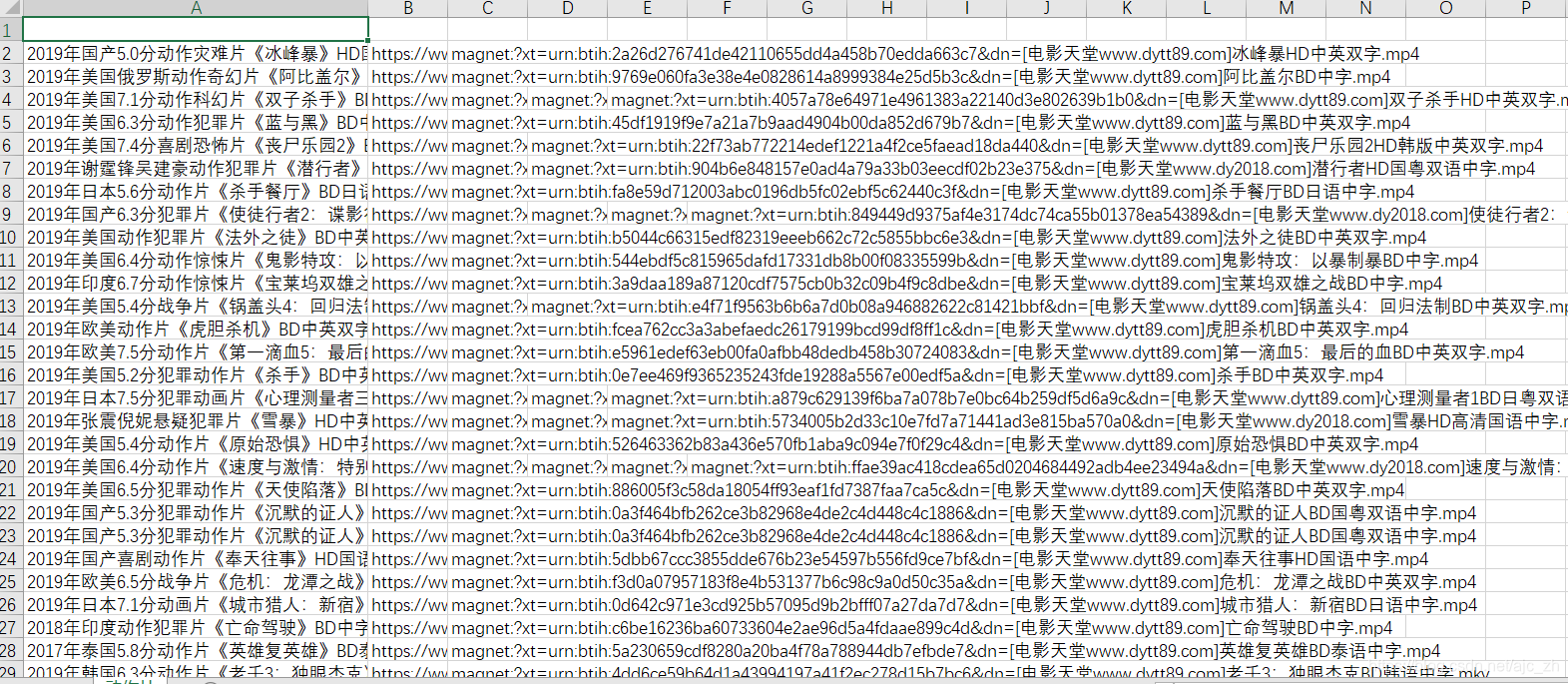
需要在当前目录下新建“动作片.csv”文件,结果如下:
本文较多参考,感谢他们!
https://blog.youkuaiyun.com/wenxuhonghe/article/details/84897936
https://blog.youkuaiyun.com/wenxuhonghe/article/details/95062701

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









