






 本文深入探讨MongoDB复制集的概念,包括数据冗余、读写分离、故障转移和延时复制策略。介绍了复制集成员角色、操作日志、数据同步机制、部署架构、高可用性和读写语义等内容。
本文深入探讨MongoDB复制集的概念,包括数据冗余、读写分离、故障转移和延时复制策略。介绍了复制集成员角色、操作日志、数据同步机制、部署架构、高可用性和读写语义等内容。
为什么要使用MongDB复制?
1.增加数据冗余。提高数据的安全性。
2.可以使用读写分离策略,提高数据查询性能。
3.在主节点服务器出现故障的时候,可以自动的进行故障转移。
4.可以使用延时复制策略,防止短时间内的数据误操作。
本文从以下九个方面对MongoDB进行介绍
一、复制集成员
二、复制集操作日志(Replica Set Oplog)
三、复制集的数据同步
四、复制集部署架构
五、高可用性复制集
六、复制集协议版本
七.Master slave(主从复制)
八.复制集读、写语义
九、数据库副本集配置实例
一、复制集成员
复制集是由一组mongod实例组成的,它提供了数据冗余和高可用性。复制集成员包括:主节点、从节点、仲裁器节点
复制集主节点
一个复制集中只能一个主节点。MongoDB在主节点上执行写入操作,并且把这些操作做记录到主节点上的oplog日志文件上。从节点会复制这个日志文件上的记录来和主节点保持数据的一致性。
复制集从节点
从节点包含了主节点的数据集拷贝。从节点使用异步处理的方式,从节点复制主节点中的oplog日志文件,并执行将其中记录的操作到自己的数据集中。复制集可以包含过个从节点。
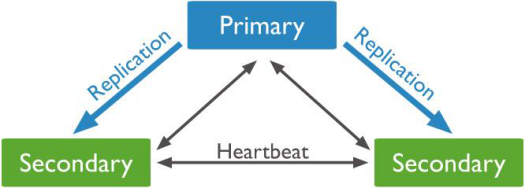
客户端不能够在从节点上写入数据,但是可以读取数据。
在主节点不可用的情况下,从节点可以通过选举的形式来升级为主节点:
Priority 0 replica set members
优先权为0的节点必须是一个从节点,此节点不能够升级为主节点。不能够触发选举。
可以包含复制集的数据拷贝,可以接收读取操作请求,可以在选举中进行投票。
Hidden replica set members
包含数据集的副本,但是对于客户端应用程序来说是不可用见的。
必须设置为priority=0,不能够升级为主节点。但是可以在选举中进行投票。
Db.isMaster()方法不能够返回隐藏节点。
Delayed Replica Set Members
要求:
--延时节点必须是0优先权节点、
--应该设置为隐藏节点
延时节点从oplog日志文件获取操作源信息。确定延时时间时,应该考虑一下问题:
--大于期望的窗口持续时间。
--要小于oplog日志的容量(oplog size)。
Sharding
In sharded clusters, delayed members have limited utility when the balancer is enabled. Because delayed members replicate chunk migrations with a delay, the state of delayed members in a sharded cluster are not useful for recovering to a previous state of the sharded cluster if any migrations occur during the delay window.
配置:
{ "_id" : <num>, "host" : <hostname:port>, "priority" : 0, "slaveDelay" : <seconds>, "hidden" : true }
二、复制集操作日志(Replica Set Oplog)
Oplog(operation log)。MongoDB在主节点上执行数据库操作,然后把这些操作记录在主节点上的oplog。从节点以异步的方法复制、执行这些操作。所有的复制集节点都包含oplog(其保存在local.oplog.rs collection中),这使得各个节点保持当前的数据库状态。
为了帮助复制,所有的复制集节点都向其它所有节点发送“心跳”(电子,脉冲)。任何节点都可以从其它任何一个节点导入oplog条目。
每一个oplog中的操作都是幂等的。就是说,不论执行一次还是多次操作、都会产生相同的结果。
Oplog size
当复制集启动的时候,MongoDB就会生成使用一个默认的oplog容量。
对于unix和windows操作系统:
| Storage engine | Default oplog size | Lower bound | Upper bound |
| In-memory storage engine | 物理内存的50% | 50MB | 50GB |
| wiredTiger storage engine | 可用磁盘空间的50% | 990MB | 50GB |
| MMAPv1 storage engine | 可用磁盘空间的50% | 990MB | 50GB |
绝大多数情况下,默认的oplog size是足够用的。
例如,oplog是可用磁盘容量的5%,并且容纳了24个小时的操作日志,那么从节点在24个小时之内不从oplog日志复制条目也不会造成数据的丢失。事实上,大部分复制集的操作次数都很少,它们的oplogs完全可以持有大量的操作日志。
在mongod创建oplog之前,可以用oplogSizeMB选项来制定其容量。一旦,复制集节点第一次开启后,只能通过Change the Size of the Oplog程序来改变oplog 容量。
Workloads that Might Require a Larger Oplog Size
如果应用程序主要执行读操作,而很少执行写入操作,那么一个较小的oplog容量就足够用了。相反的,如果自己的复制集有以下特征的工作负载,你可能需要创建一个比默认值更大的oplog容量:
-- 一次性更新多个文档记录。
-- 数据删除和数据插入数据量差不多的时候。
-- 有大量不会增加documents容量的更新操作。
操作日志的状态 Oplog status
使用rs.printReplicationInfo()进行operation的容量和时间范围等信息的查询。
在一些特别的情况下,从节点的oplog更新可能会存在我们不期望的时间延迟。在从节点中,使用db.getReplicationInfo()输出信息去判断当前的复制状态,最终确定是否存在计划之外的数据延时。
三、复制集的数据同步
为了保证复制最新的数据,从节点可以设置同步,或者是从其它节点复制数据。
同步初始化
初始化复制集的一个节点从其它节点同步复制数据。
过程
1克隆除了local之外的所有数据库。为了去克隆、mongod扫描所有数据库的每一个collection,把所有的数据插入到自己的数据拷贝中。
2执行所有数据及上的变化。使用源数据库的oplog,mongod更新当前节点的数据集以达到复制集当前的状态。
容错
为了从短暂的网络、操作错误中恢复,initial sync 内建了重操作逻辑。
3.4版本开始,增加了从间歇式的网络错误中恢复的能力。
复制
从节点会在同步初始化(initial sync)之后继续进行数据的复制。从节点以同步的方式从oplog中复制操作,以异步的方式执行这些操作。
从节点会在声脉冲时间和其它节点复制状态的改变的基础上 根据需要 自动的改变它们的数据同步来源。
从mongodb3.2开始,拥有一个选票的节点不能从没有选票的节点进行资源同步。
从节点避免从延时节点和隐藏节点同步数据。
members[n].buildIndexes=true的从节点只能从其值为true的节点同步数据。此值默认为true。
多线程复制(multithreaded replication)
Mongodb使用多线程进行分批次处理来提高并发性能。Mongodb以命名空间(MMAPv1)或者文档id(wiredTiger)进行分组,同时使用不同的线程来执行每一组操作。Mongodb总会按照数据的原始写入顺序对document执行写入操作。
执行分批处理的时候,mongodb会锁定所有的读取操作。结果就是,从节点的读取操作不可能出现主节点中不存的数据。
预获取索引以提高复制生产力
只适用于MMAPv1引擎
为什么?
MMAPv1引擎中,mongodb获取内存中持有数据和索引的脏页,帮助提升从oplog中执行操作的性能。预获取阶段最小化执行oplog期间mongodb持有写锁的时间。
四、复制集部署架构
复制集的架构决定了它的容量和能力。本节介绍复制集部署策略和常见的架构。
生产系统的标准复制集部署是三个节点的复制集。集合提供了冗余和容错能力。
策略
1确定节点的数量
2最大化投票节点
3部署奇数个节点
4考虑容错能力
| Number of members | Majority required to elect a new primary | Fault tolerance |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
5将隐藏节点和延时节点用于备份等专用功能
6负载均衡
增加对从节点的分布式读,提升数据读取能力。
7在需求来临之前增加架构容量
复制集要存在添加新节点的能力
8地理位置上的分布式节点
为了防止数据中心瘫痪而造成数据丢失,需要至少建立一个备援数据中心。
9用tag sets 设置 操作目标
使用replica set tage sets将读操作指向一个明确的节点,或者自定义write concern 去请求来自指定的从节点的写入确认信息。
10使用journal日志在电力瘫痪的情况下进行数据保护
Journal就是在mongodb数据持久化之前,将数据操作写成功写入journal日志。从而保证了数据的所有操作都记录在日志文件中。
复制集命名
如果应用程序和多个节点进行通讯,那么每个节点都要设置不一样的名字。
部署模式
三节点复制集
最小的复制集架构包含三个节点。
一主两从节点架构
两从均持有数据,并可以在选举中成为主节点。
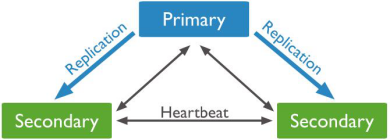
部署提供了两个从节点来始终持有数据集的完整拷贝。提供了额外的容错能力和高可用性。如果主节点故障,复制集将一个从节点选举为主节点继续进行正常的操作。当之前的主节点可用的时候,再重新加入复制集。
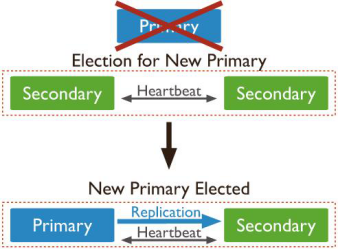
一主一从一仲裁(负责投票)节点架构
一个从节点,其可以在选举中成为主节点。
一个仲裁器节点,仅仅在选举中进行投票。
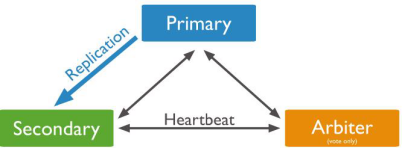
因为仲裁器不持有数据拷贝,这种部署仅仅提供了一份数据的完整拷贝。
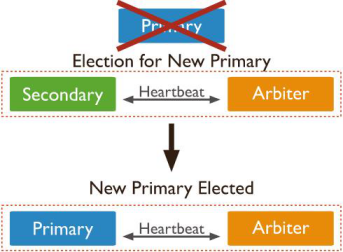
2个及以上数据中心的分布式复制集部署架构
虽然复制集对单实例损坏提供了基本的保护措施,但是,如果数据集的所有节点都放在一个数据中心,那么这个数据中心由于电力供应中断、网络中断、自然灾害的发生,将对复制集的所有节点造成影响。
建立跨地理分布的不同数据中心,可以增加数据冗余、提供容错能力。
分布式节点
为了防止数据中心的损坏,至少要建立一个备用数据中心。可能的话,尽量建立奇数个数据中心,除了最可能丢失数据的数据中心节点,剩下的节点要具有可以形成差额选票、提供数据拷贝的能力。
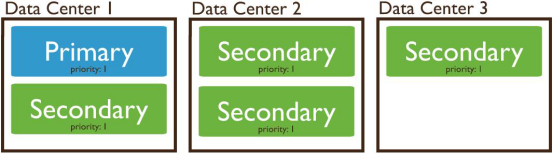
三节点多数据中心复制集:
1.两个数据中心
中心1放置2个节点,中心2放置1个节点。如果需要仲裁器节点,必须将其和其它持有数据的节点放置在同一数据中心。
2.三个数据中心(每一中心一个节点)
五节点多数据中心复制集:
举例:
1.两个数据中心
中心1放置3个节点,中心2放置2个节点。
2.三个数据中心
中心1放置2个节点,中心2放置2个节点,中心3放置1个节点。
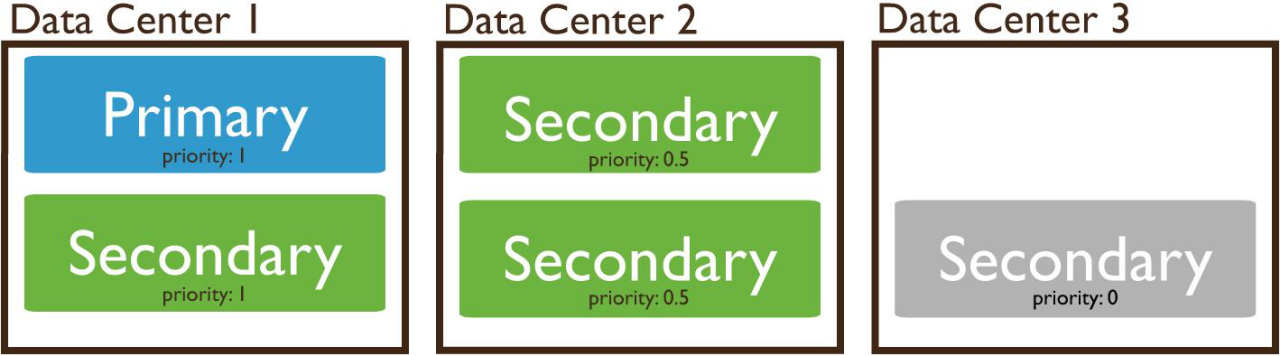
复制集节点灵活的可选性
有些情况下,如、节点存在网络限制或者是资源限制,应该将其配置为优先权为0(不能成为主节点)。
另外,如果更希望数据中心1中的节点成为主节点。可把数据中心1中节点的priority设置为比其它数据中心节点的priority更大的值。
例如下图所示的部署架构:
五、高可用性复制集
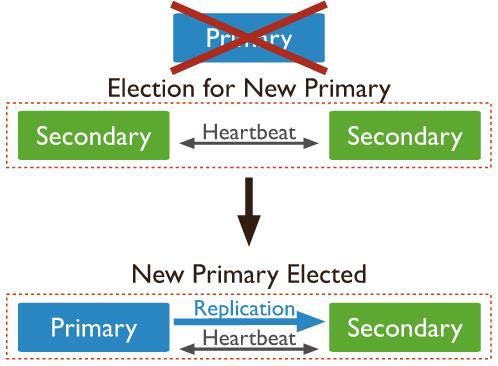
复制集选举
复制集使用选举的机制决定把哪一个从节点升级为主节点。选举发生在初始化一个复制集之后和主节点不可用的任何时候。在主节点不可用的情况下,复制集选举自行机制会将复制集恢复正常,而不需要人为的干涉。
然而选举的过程需要花费一定的时间来执行,在此期间,复制集中没有主节点并且不能接收任何写入操作,所有的节点都是只读的。
如果对于当前的主节点来说,大多数复制集成员都无法访问了,那么主节点会降级成为一个从节点。之后,复制集不对外提供写入操作,但是从节点成员可以对外提供读取操作。
影响选举的因素和条件
1.复制选举协议
从MongDB3.2开始,使用复制协议vesion1(protocolVersion:1)降低失效备援发生的次数、加速同一时间点多主节点检测。MongoDB3.2之前使用复制协议version0.
2.心跳
复制集成员之间每两秒钟会相互发送心跳(mongodb使用发送ping数据包进行心跳检测)。如果一个发送的心跳在10秒之内没有返回信息,那么其它节点会把这个无法返回心跳的节点标记为不可访问节点。
3.成员优先权
在复制及拥有一个稳定的主节点之后,选举算法依然会尝试找到可用的拥有最高优先权的从节点,并让此节点发出选举。成员节点的优先权既会影响选举时间,又会影响选举结果。和低优先权的节点相比,高优先权的节点会更快速的发出选举,并且具有更高的获胜几率。尽管存在更高优先权的节点,低优先权节点在一些特定的时期也可以被选举为主节点。复制集成员会不停地发出选举,直到拥有最高优先权的节点变成主节点。
4.数据中心的丢失
一个数据中心的丢失,可能会影响在其它数据中心中剩余节点的主节点选举。
尽可能的,分配复制集到各个数据中心,使得即使一个数据中心丢失,剩余的复制集节点也能选举出一个新的主节点。
5.网络隔离
网络隔离,可能会把复制集隔离成一个只有少数节点的复制集的一个划分。当主节点检测到自己只能连接到复制集中少数节点的时候,主节点会降级为从节点。在这个划分中,如果有一个节点可以和大部分节点进行通讯,那么这个节点会发出选举并且升级为主节点。
6.选举中的否决权
(mongodb3.2之后,protocolVersion:1摒弃了否决权策略)。以下讨论protocolVersion:0版本中的否决权机制。
使用protocolVersion:0的复制集,所有节点都可以否决选举(包括非投票成员)。在以下情况中,节点会否决一个选举:
a、如果发出选举的不是可投票成员。
b、对于另一个投票成员节点来说,如果主节点比发出选举的从节点具有更新的数据操作时间点(oplog记录了更多、更新的操作信息)。
c、如果主节点具有比发出选举的从节点更高或者相等的数据操作时间点。
d、If a priority 0 member [1] is the most current member at the time of the election. In this case, another eligible member of the set will catch up to the state of the priority 0 member member and then attempt to become primary.
e、如果一个比其它节点优先权低的节点发出选举。
投票成员
复制集通过配置项:members[n].votes和state两个配置项来决定节点是否具有投票权。
members[n].votes配置为1的节点可以投票。配置为0的节点不可以投票。
(从mongodb3.2开始:1.无投票权节点必须将priority设置为0。2.priority大于0的节点不能将votes设置为0)
只有state为以下值的节点可以进行投票:
PRIMARY
SECONDARY
RECOVERING
ARBITER
ROLLBACK
无投票权成员
此类型节点虽然不可以投票,但是持有复制集的数据拷贝,可以接收客户端的数据查询请求。
一个复制集最多只能有50个节点,7个投票节点,其它节点必须是非投票节点。
非投票节点votes和priority都要设置为0:
{ "_id" : <num>, "host" : <hostname:port>, "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 0, "tags" : { }, "slaveDelay" : NumberLong(0), "votes" : 0 }
复制集失效备援中的回滚操作
在发生失效备援(故障转移)之后,当之前的主节点(现在变成从节点)重新加入到当前的复制集中的时候,回滚会在旧版的主节点上把其它节点未接收到写入操作进行撤销。主节点降级为从节点之前,所有在主节点上发生但是没有被成功复制到从节点中的写入操作,都应该在主节点降低为从节点并从新加入复制集之后被回滚,以保证各节点的数据一致性。
回滚通常是由网络分割导致的。Mongodb会努力避免回滚的发生。跟不上之前主节点执行性能的从节点会增加回滚段(需要进行回滚的)的大小和影响。
如果在主节点降级之前,所有的写入操作都成功的复制到了另外一个从节点上,并且这个从节点对复制集中大多数节点来说都是可用的,那么回滚操作就不会发生。
1.收集回滚数据
当回滚发生的时候,mongodb将回滚数据写入dbpath目录下rollback/文件夹下的BSON文件。回滚文件格式如下:
<database>.<collection>.<timestamp>.bson
例如:records.accounts.2011-05-09T18-10-04.0.bson
使用bsondump程序可以读取rollback文件中的内容。
2.避免复制集回滚
复制集使用默认设置:wirte concern{w:1},仅仅提供了在主节点上写操作的确认。在默认的write concern设置下,如果在将写入操作复制到其它任何从节点之前主节点降级为从节点,那么数据可能就会被回滚。
为了阻止客户端已经确认的数据被回滚,运行所有开启journal日志并且使用write concern为{w:”majority”}的投票节点,来保证客户端收到确认信息之前把所有写入操作传播到大部分的复制集节点。
3.回滚限制
Mongod实例对超过300M的数据进行回滚。如果回滚数据超过了300M,你必须手动执行数据的回滚。在这种情况下,mongod日志会提示以下信息:
[replica set sync] replSet syncThread: 13410 replSet too much data to roll back
In this situation, save the data directly or force the member to perform an initial sync. To force initial sync, sync from a “current” member of the set by deleting the content of the dbPath directory for the member that requires a larger rollback.
六、复制集协议版本
MongoDB提供了两个复制集协议:pv0和pv1
--pv0优先考虑去降低{w:1}配置状态下写入操作被回滚的可能性。在特定的网络隔离的情况下,pv0可能导致无法确认{w:”majority”}写入操作。
--pv1保证{w:”majority”}写入操作的正常确认。
可用性
Pv0在所有版本中可用
Pv1在》=3.2版本中可用,并且默认启用。
Read concern
| Read concern | Pv0 | Pv1 |
| “local” | √ | √ |
| “majority” |
| √ |
| “linearizable” | √ | √ |
Arbiters(仲裁器)
对于包含一个仲裁器的复制集,在{w:1}配置上,pv1比pv0更容易使节点发生回滚。
Vetoes(否决选举)
Pv0允许成员节点根据optime和priority否决选举。
Pv1不使用否决权策略。在一个特定的选举中,各个节点可以投票支持或反对一个候选节点,各节点不能单方面的去否决一个选举。
同时间点上的多主节点检测
在一些情况下,复制集的两个节点暂时都认为自己是主节点,但是,他们两个之中最多只有一个可以完成write concern 设置为{w:”majority”}的写入操作。能够完成{w:”majority”}0写入操作的节点才是真正的主节点,另外一个是之前的主节点(还没有承认、意识到自己已经降级。这种情况通常是由网络隔离导致的)。
在多主节点同时存在的情况下,Pv0依赖时钟同步机制来消除模糊性。但是,依赖时钟机制会丢失w:majority 写入操作的确认信息。
不同于pvo,pv1使用term概念。这允许在一个较短的时间内,允许快速执行多主节点检测、多个成功的选举。如果pv0需要在一个较短时间间隔内执行多次成功的选举,那么pvo使复制集保持一个没有主节点的状态。
背靠背选举
为了最大化写入功能的可用性,在实施一个选举的时候,pv1不会考虑节点的priority。取而代之,pv1会在复制集拥有一个稳定的主节点之后,允许携带最高priority的从节点发出一个选举。当一个合适的带有更高priority的节点发出选举的时候,就产生了一个背靠背的选举。pv0在多个背靠背选举之间需要有30秒的缓冲,和pv0不同,pv1使用term允许更快速的并发执行背靠背选举。
设置为pv1的背靠背选举之间的频率增加、时间缓冲的缺乏都会增加{w:1}write concern回滚发生的可能性。但是,我们可以通过增加catchUpTimeoutMillis设置,可以减少回滚发生的次数。
在一次选举期间,pv0允许节点根据priority值进行否决选举。在这种情况下,复制集在拥有了稳定的主节点之后,pv0触发的背靠背选举会比pv1触发的少。因为pv0依赖时钟同步进行多主节点检测,pv0在背靠背选举中包含了30秒缓冲来预警贫乏的时钟同步。
两次投票
在一个成员节点发出选举期间,pv1会阻止两次投票。
Pv0通过30秒缓冲来降低两次投票的可能性,但是在一次选举超过30秒的情况下,不能保证一个节点会进行两次投票。
七.Master slave(主从复制)
从mongoDB3.2开始,不再把主从复制作为分片集群的组件。取而代之,将使用复制集。和复制集相比,master-slave复制模式无法提供更多的数据冗余、不能进行自动的故障转移。(主从复制教程请参考官方文档)
八.复制集读、写语义
mongodb实例是以一个单机的形式、还是副本集的一个成员,对于一个客户端程序来说是透明的。Mongodb提供了复制集相关的读、写配置。
Write concern for replica sets
描述mongodb写操作的确认级别
验证到复制集的写入操作
对于复制集来说,默认write concern只会对主节点进行请求确认。我们可以覆盖默认的write concern,如:以一个指定数量的复制集成员来确认写入操作。
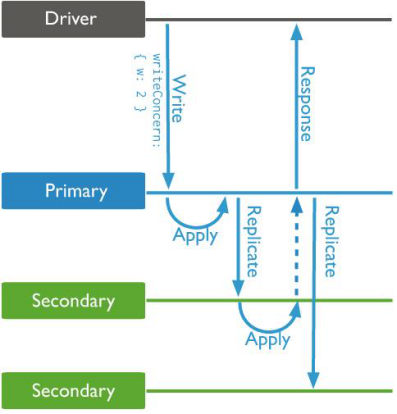
我们可以对每一个写入操作指定write concern来覆盖默认的write concern。例如,以下方法中指定方法必须在写入操作传播到主节点和至少一个从节点或者5秒之后返回执行结果。
db.products.insert( { item: "envelopes", qty : 100, type: "Clasp" }, { writeConcern: { w: 2, wtimeout: 5000 } } )
可以为write concern指定一个超时阈值。在无法完成writeconcern的时候,超时设置会防止写入操作被无限期的被阻塞。例如,write conren 指定为4,但是复制集只有三个成员节点,那么写入操作会被阻塞,直到有4个成员可用为止。
修改默认的write concern
通过在复制集配置中设置settings.getLastErrorDefaults来修改默认的write concern。以下命令行序列会创建一个配置,要求大部分的投票节点都完成了写入操作再执行写入函数的返回。
cfg = rs.conf() cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 } rs.reconfig(cfg)
自定义write concerns
Read preference(读首选项)
指定驱动程序应该将读操作指向什么地方。描述了客户端如何将读操作路由到复制集的成员节点。
默认情况下,应用程序将其读操作指向复制集的主节点。
在指定read preference的时候,不同于primary模式下的读取操作返回的可能不是最新的数据,这是因为复制集采用的是异步复制的机制,从节点上的数据不能反映最新的写入操作。
Read preference不会影响数据的可见性,也就是说,客户端可以在写入操作确认信息之前,可以看到写入的结果:
-- 与write concern无关,使用“local”(默认级别)readConcern的客户端可以看到未被确认的写入操作结果。
-- 使用“local”readConcern的客户端读取的数据接下来可能会被回滚。
Read preference 模式
除了primary模式,所有的read preference都会受到数据延迟的影响。如果要配置为非primary模式,那么要确认你的应用程序可以接受这种数据延迟。
MongoDB 驱动程序支持五种read preference模式:
Primary、primaryPreferred、secondary、secondaryPreferred、nearest
maxStalenessSeconds(new in 3.4)
复制集成员可能由于网络拥挤、低性能的磁盘处理能力、长期的操作等原因,而比主节点数据延时。maxStalenessSeconds选项可以指定从节点读取操作最大的复制延时时间。当延时超过了此设置,客户端会停止对当前节点的读取。
maxStalenessSeconds必须大于等于90秒。
Tag sets(标签集)
允许通过标签来标记可进行读取操作的复制集成员。
Read preference 和write concern以不同的方式对标签集进行处理。Tag值是Read preference确定读取节点所需考虑的因素。Write concern在选择节点时忽略tag的值,tag在这里只用于唯一性标识。
标签与primary read preference不能相互兼容。只能与另外四种模式组合使用。
服务器选择算法(Server selection algorithm)
介绍read preference的机制
复制集的read preference
分片集群中的read preference
负载均衡
如果连接列表有多个mongos实例,驱动程序会确定哪一个mongos是“最近的”(网络往返平均时间最短的那个节点),通过增加“最近”节点的平均往返时间和localThresholdMS来计算延迟窗口。驱动程序使用这个延时窗口将合格的成员列表(mongos集合)进一步的进行过滤。最后,驱动程序随机的从窗口中选择一个mongos实例来进行连接使用。
Read preference和分片
对于分片集群中拥有复制集的分片,当从分片中进行数据读取的时候mongos会使用read preference设置。服务器的选择由read preference和replication.localPingThreasholdMs(默认阈值为15毫秒)设置来确定。
九、数据库副本集配置实例
待续。。。。

















 2659
2659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









