



 本文介绍词向量的基本概念,包括one-hot编码的局限性及词向量的优势,详细解析Word2Vec的CBOW和Skip-gram两种训练方法,并提供基于Python的实践案例。
本文介绍词向量的基本概念,包括one-hot编码的局限性及词向量的优势,详细解析Word2Vec的CBOW和Skip-gram两种训练方法,并提供基于Python的实践案例。
词向量
- 基本概念
- 算法
- 实践
基本概念
word2vec(word to vector),词向量是自然语言分词在词空间中的表示,词之间的距离代表了分词之间的相似性。
词的基本表示方法有两种:
-
one-hot表示方法
-
词向量表示方法
one-hot 编码的缺点:1 、无法表示出语义层面上词语之间的相关信息
2、词汇表达的时候 ,无法表示,耗费空间。
词向量 将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,通过向量来刻画其相似性。
其训练方法主要有两种:1、cbow 2、skip-gram
算法
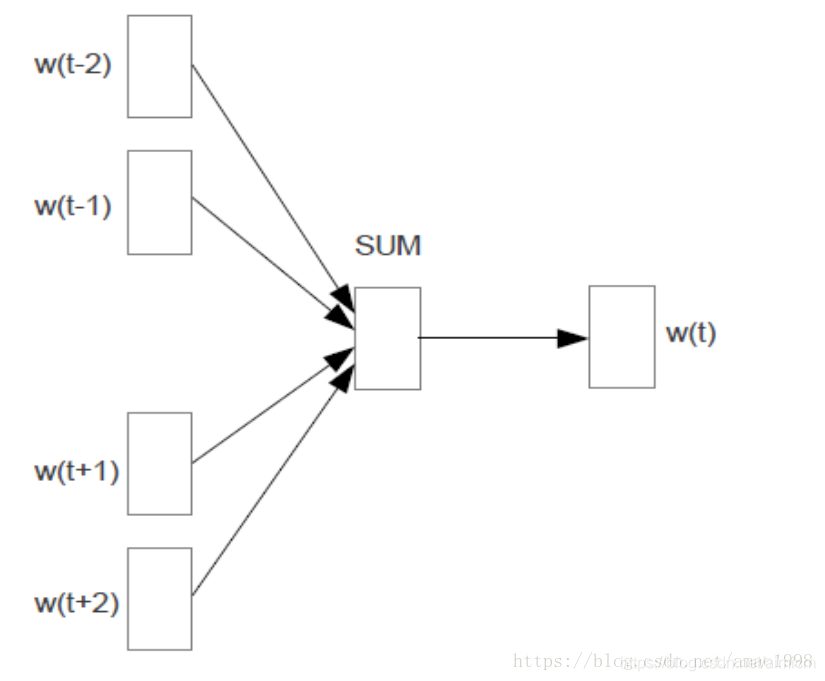
cbow模型:
cbow模型,又称连续词袋模型, 如下图所示,该模型的特点是输入已知上下文,输出对当前单词的预测:
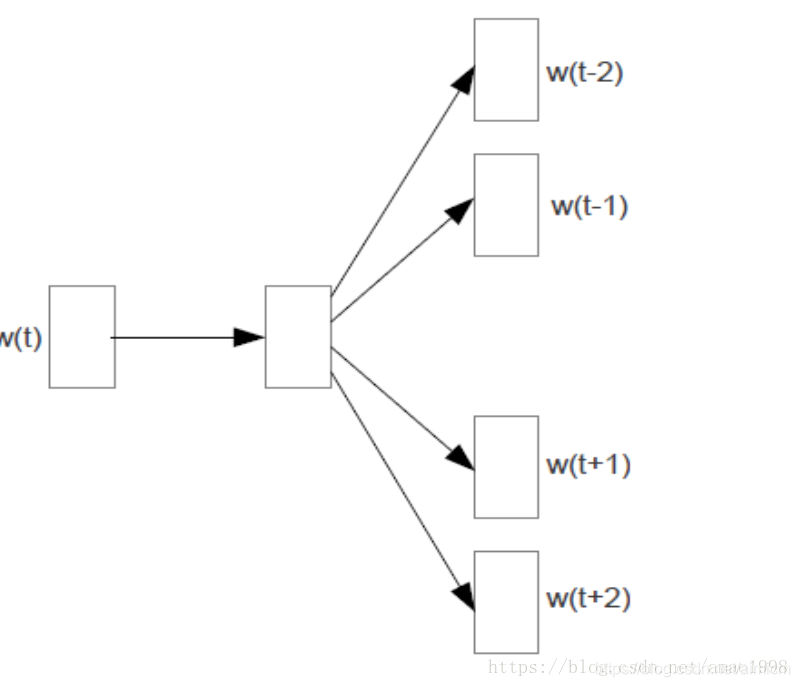
skip-gram 模型
skip模型只是逆转了CBOW的因果关系而已,即已知当前词语,预测上下文。
备注:
- 当语料特别大时,多用Skip-Gram
- Word2Vec对多义词表示的并不好,因此有了改进版本GloVe,但用的不多。
- 还有sense2vec模型,它是将词性和word2vec结合的技术
实践
import pandas as pd
import gensim
import time
import pickle
import numpy as np
import csv, sys
vector_size = 100
maxInt = sys.maxsize
decrement = True
while decrement:
decrement = False
try:
csv.field_size_limit(maxInt)
except OverflowError:
maxInt = int(maxInt / 10)
decrement = True
def sentence2list(sentence):
return sentence.strip().split()
start_time = time.time()
data_path = './data'
feature_path = './data/feature_file'
proba_path = './data/proba_file'
model_path = './data/model_file'
result_path = "./data/result"
df_train = pd.read_csv(data_path + 'train_set.csv', engine='python')
df_test = pd.read_csv(data_path + 'test_set.csv', engine='python')
sentences_train = list(df_train.loc[:, 'word_seg'].apply(sentence2list))
sentences_test = list(df_test.loc[:, 'word_seg'].apply(sentence2list))
sentences = sentences_train + sentences_test
model = gensim.models.Word2Vec(
sentences=sentences,
size=vector_size,
window=5,
min_count=5,
workers=8,
sg=0,
iter=5)
wv = model.wv
vocab_list = wv.index2word
word_idx_dict = {}
for idx, word in enumerate(vocab_list):
word_idx_dict[word] = idx
vectors_arr = wv.vectors
vectors_arr = np.concatenate((np.zeros(vector_size)[np.newaxis, :], vectors_arr), axis=0)
f_wordidx = open(feature_path + 'word_seg_word_idx_dict.pkl', 'wb')
f_vectors = open(feature_path + 'word_seg_vectors_arr.pkl', 'wb')
pickle.dump(word_idx_dict, f_wordidx)
pickle.dump(vectors_arr, f_vectors)
f_wordidx.close()
f_vectors.close()

















 1148
1148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









