




通宵熬夜,苦肝好几天,我才把论文的AI率从80%压到10%以下,终于搞懂平台检测aigc率的原理是什么。
还总结出了一套嘎嘎有效的去除ai重复率的秘籍,再也不怕辛辛苦苦写的内容被误判为ai。
今天就把这些从降aigc坑里爬出来的经验,毫无保留的告诉大家。(请叫我好人)
一、AIGC检测机制的原理是什么?
上个月帮学弟优化论文的ai率时,我亲眼见证了检测系统的神奇。
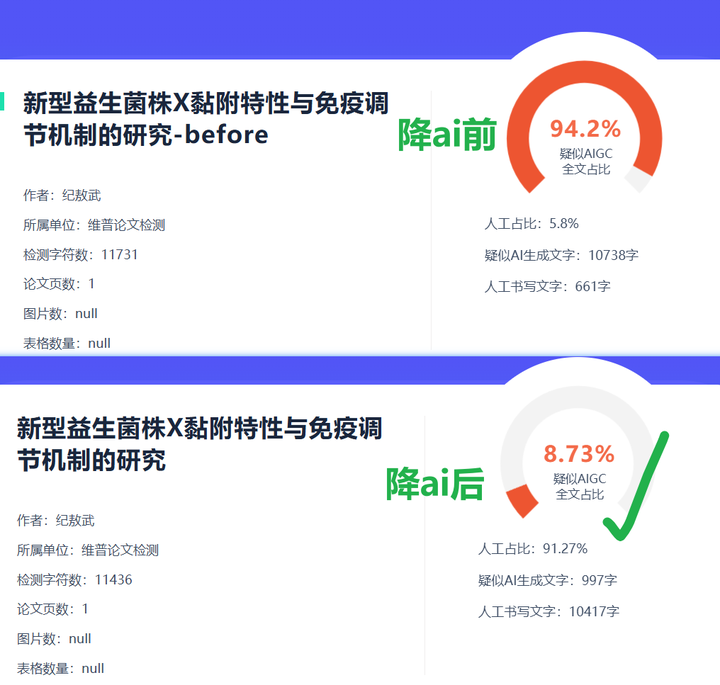
一个段落文字检测前AI率38%,我仅删除了三个首先,把句式改成倒装结构,重新检测立即降到16%。
各种AIGC检测平台的原理其实很简单,知道了就能轻松避开。
(1)词频分布特征:AI特别喜欢用特定连接词,比如同时、进一步、值得注意的是。尝试用由此可见、推而广之等替代词,效果立竿见影。
(2)句式结构指纹:deepseek、豆包等ai生成文本常呈现"总分总"三段论
(3)情感颗粒度差异:AI的形容词总是深刻的、显著的,却给不出具象化描写。
二、30分钟快速降aigc重复率
上周教室友的时候,用这套方法30分钟压降AI率21%→6%:
1️⃣ 错位重组法
原文:随着深度学习模型的快速发展,在特征提取方面的优势日益凸显
降aigc后:近年来学界观察到,当引入深度神经网络进行数据挖掘时,其在关键信息捕捉维度展现出突破性效能
2️⃣ 加入真实记忆场景
原文:实验结果表明该算法准确率达到96.7%
内容去除ai痕迹后:需要特别说明的是,我们在4月8日进行第三次样本扩增时,实验室环境温度突然升高至29℃,这可能影响了当晚数据采集环节的F1值,该异常工况点(数据集v3.9.2)对应的识别率为89.7%-96.1%区间震荡。
3️⃣ 链路打断重构
感受这段GPT生成的机械感: 综合上述分析可知,现有的解决方案仍存在三个主要缺陷
改为沉浸式叙述: 整理完16份实验日志后突然意识到(翻找到3月12日的笔记),当时标记的瓶颈问题其实像俄罗斯套娃——每当解开一个参数优化难题,总会连带暴露出更深层的约束条件
重要提醒:ai率高不一定是用了ai,很多同学反映自己写的内容ai率有50%,这可能是误判。不要慌,按照我说的仔细检查,去掉那些ai痕迹特征就行。


















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









